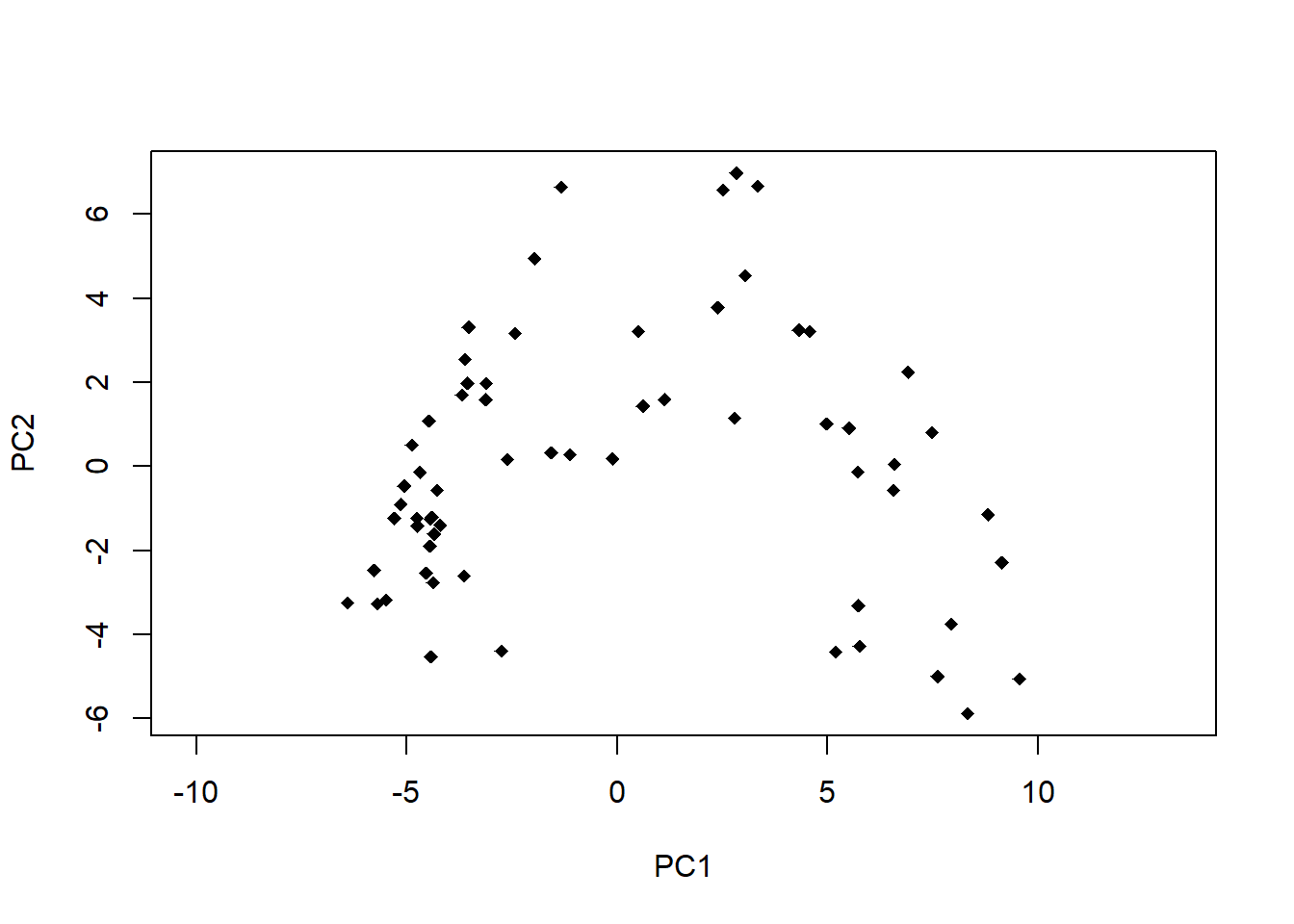
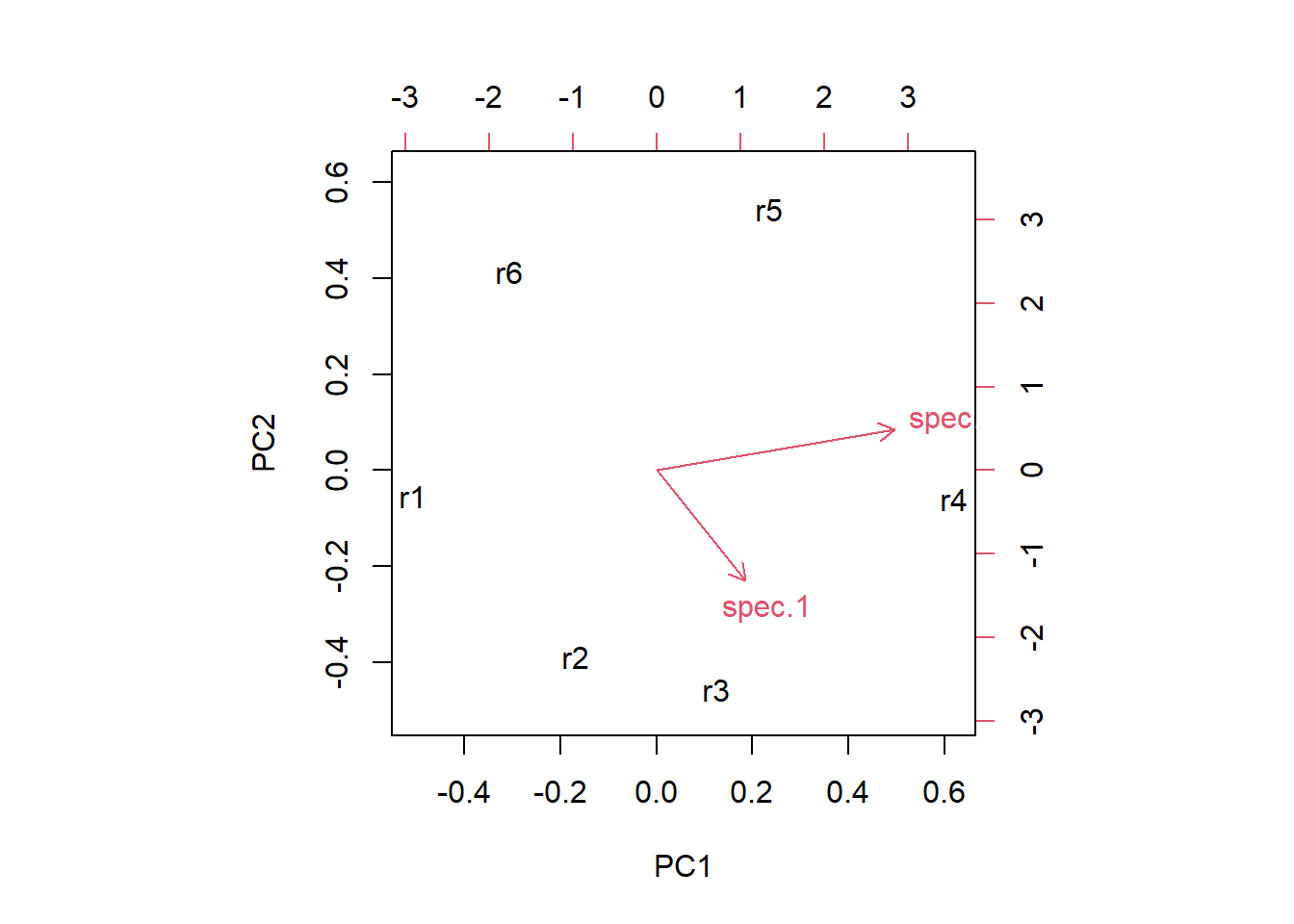# Mit Beispieldaten aus Wildi (2013, 2017)library("labdsv")library("readr")sveg <-read_delim("datasets/statKons/dave_sveg.csv")head(sveg)str(sveg)# View(sveg)# PCA-----------# Deckungen Wurzeltransformiert, cor=T erzwingt Nutzung der Korrelationsmatrixo.pca <- labdsv::pca(sveg^0.25, cor = T)o.pca2 <- stats::prcomp(sveg^0.25)# Koordinaten im Ordinationsraum => Yhead(o.pca$scores)head(o.pca2$x)# Korrelationen der Variablen mit den Ordinationsachsenhead(o.pca$loadings)head(o.pca2$rotation)# Erklaerte Varianz der Achsen (sdev ist die Wurzel daraus)# früher gabs den Befehl summary()# jetzt von hand: standardabweichung im quadrat/totale varianz * 100 (um prozentwerte zu bekommen)E <- o.pca$sdev^2/ o.pca$totdev *100E[1:5] # erste fünf PCA# package stats funktioniert summary()summary(o.pca2)# PCA-Plot der Lage der Beobachtungen im Ordinationsraumplot(o.pca$scores[, 1], o.pca$scores[, 2], type ="n", asp =1, xlab ="PC1", ylab ="PC2")points(o.pca$scores[, 1], o.pca$scores[, 2], pch =18)
plot(o.pca$scores[, 1], o.pca$scores[, 3], type ="n", asp =1, xlab ="PC1", ylab ="PC3")points(o.pca$scores[, 1], o.pca$scores[, 3], pch =18)
# Subjektive Auswahl von Arten zur Darstellungsel.sp <-c(3, 11, 23, 39, 46, 72, 77, 96, 101, 119)snames <-names(sveg[, sel.sp])snames# PCA-Plot der Korrelationen der Variablen (hier Arten) mit den Achsen# (hier reduction der observationen)x <- o.pca$loadings[, 1]y <- o.pca$loadings[, 2]plot(x, y, type ="n", asp =1)arrows(0, 0, x[sel.sp], y[sel.sp], length =0.08)text(x[sel.sp], y[sel.sp], snames, pos =1, cex =0.6)
# hier gehts noch zu weiteren Beispielen zu PCA's:# https://stats.stackexchange.com/questions/102882/steps-done-in-factor-analysis-compared-to-steps-done-in-pca/102999#102999# https://stats.stackexchange.com/questions/222/what-are-principal-component-scores
PCA mit Beispiel aus Skript
# Idee von Ordinationen aus Wildi p. 73-74# Für Ordinationen benötigen wir Matrizen, nicht Data.frames# Generieren von Datenraw <-matrix(c(1, 2, 2.5, 2.5, 1, 0.5, 0, 1, 2, 4, 3, 1), nrow =6)colnames(raw) <-c("spec.1", "spec.2")rownames(raw) <-c("r1", "r2", "r3", "r4", "r5", "r6")raw# originale Daten im zweidimensionalen Raumx1 <- raw[, 1]y1 <- raw[, 2]z <-c(rep(1:6))# Plot Abhängigkeit der Arten vom Umweltgradientenplot(c(x1, y1) ~c(z, z),type ="n", axes = T, bty ="l", las =1, xlim =c(1, 6), ylim =c(0, 5),xlab ="Umweltgradient", ylab ="Deckung der Arten")points(x1 ~ z, pch =21, type ="b")points(y1 ~ z, pch =16, type ="b")
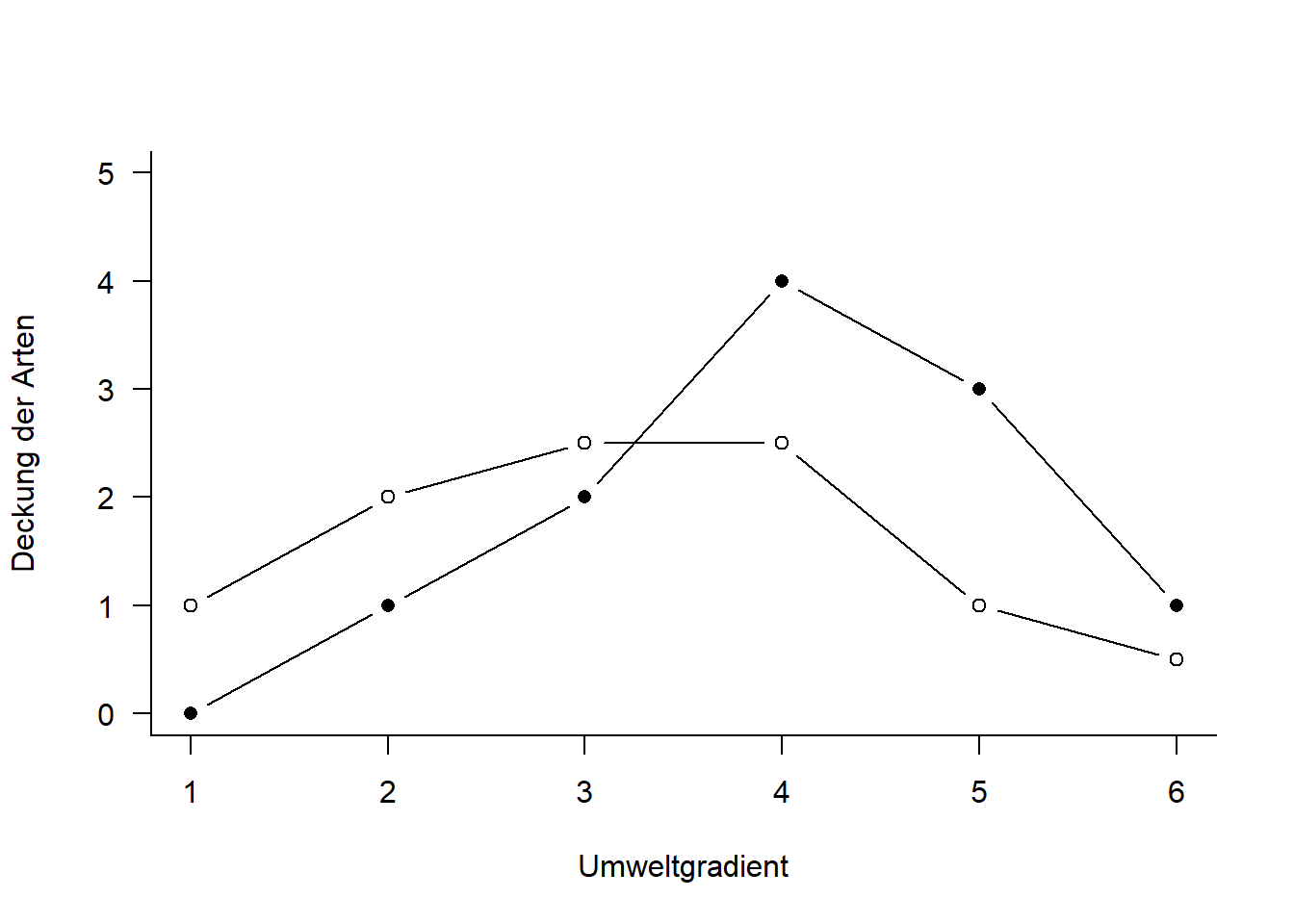
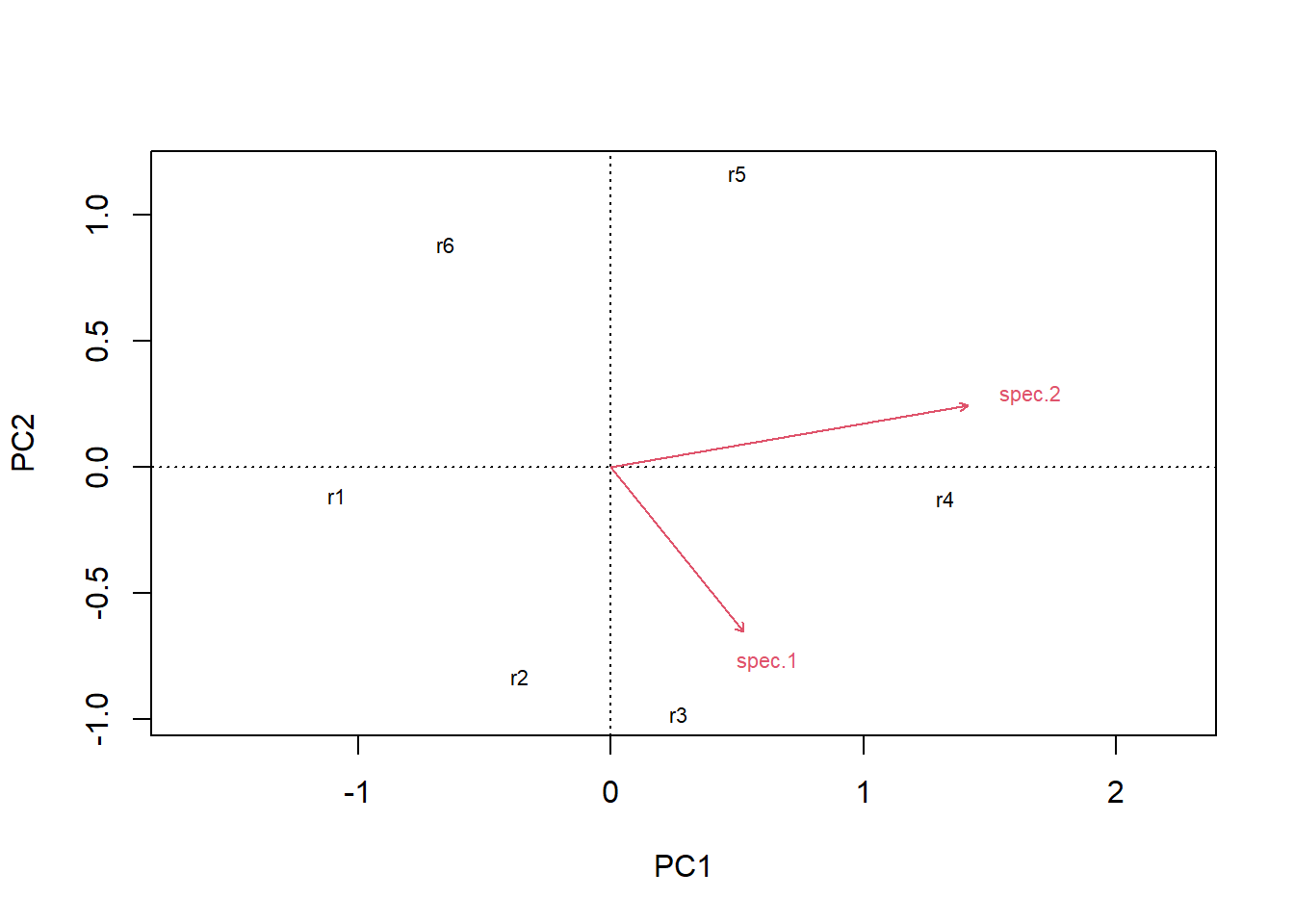
# zentrierte Datencent <-scale(raw, scale = F)x2 <- cent[, 1]y2 <- cent[, 2]# rotierte Dateno.pca <-pca(raw)x3 <- o.pca$scores[, 1]y3 <- o.pca$scores[, 2]# Visualisierung der Schritte im Ordinationsraumplot(c(y1, y2, y3) ~c(x1, x2, x3),type ="n", axes = T, bty ="l", las =1, xlim =c(-4, 4),ylim =c(-4, 4), xlab ="Art 1", ylab ="Art 2")points(y1 ~ x1, pch =21, type ="b", col ="green", lwd =2)points(y2 ~ x2, pch =16, type ="b", col ="red", lwd =2)points(y3 ~ x3, pch =17, type ="b", col ="blue", lwd =2)
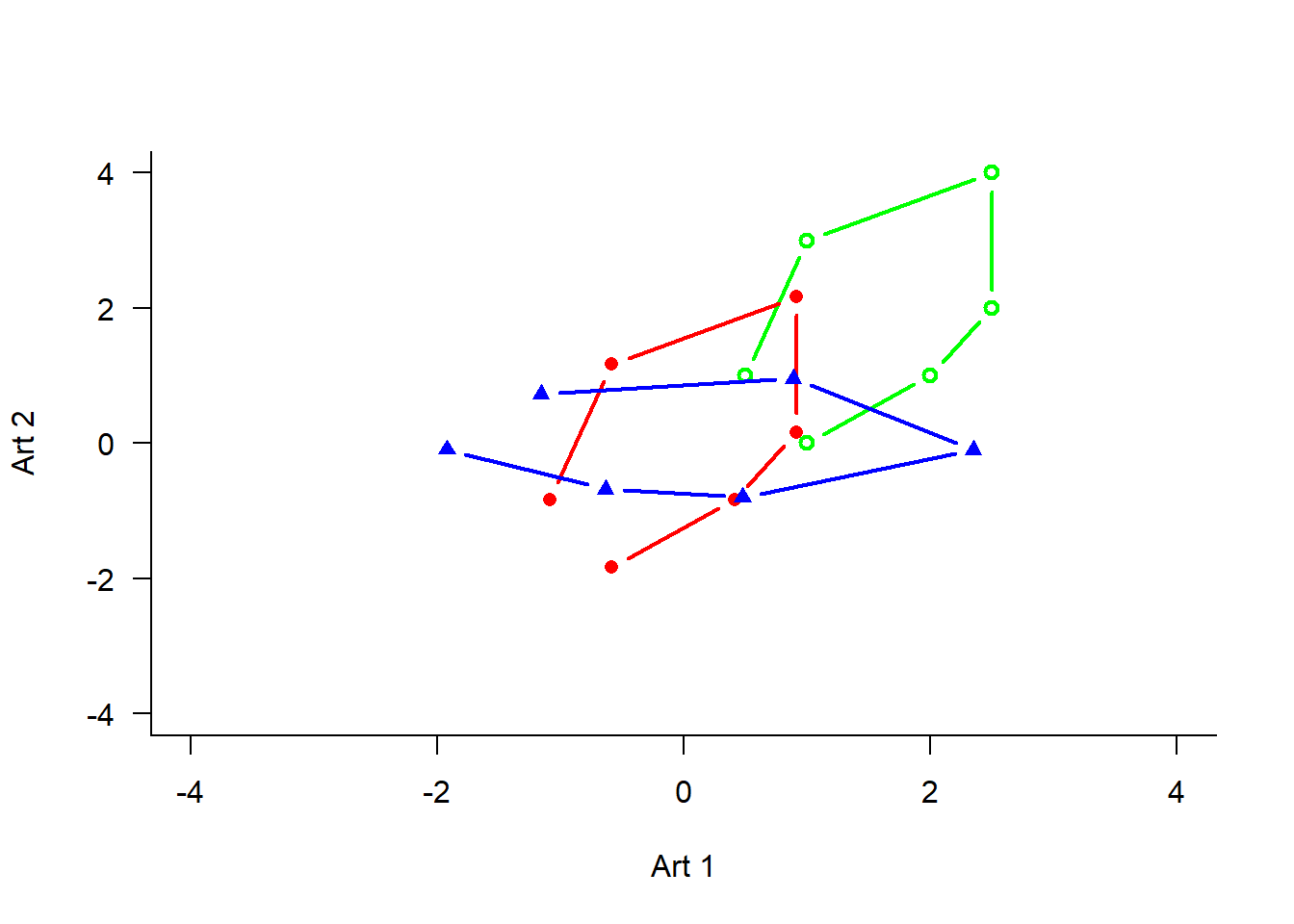
# zusammengefasst:-------# Durchführung der PCApca <-pca(raw)# Koordinaten im Ordinationsraumpca$scores# Korrelationen der Variablen mit den Ordinationsachsenpca$loadings# Erklärte Varianz der Achsen in ProzentE <- pca$sdev^2/ pca$totdev *100E### excurs für weitere r-packages##### mit prcomp, ein weiteres Package für Ordinationenpca.2<- stats::prcomp(raw, scale = F)summary(pca.2)plot(pca.2)
biplot(pca.2)
# mit vegan, ein anderes Package für Ordinationenpca.3<- vegan::rda(raw, scale =FALSE) # Die Funktion rda führt ein PCA aus an wenn nicht Umwelt- und Artdaten definiert werden# scores(pca.3,display=c("sites"))# scores(pca.3,display=c("species"))summary(pca.3, axes =0)biplot(pca.3, scaling =2)biplot(pca.3, scaling ="species") # scaling=species macht das selbe wie scaling=2
CA mit sveg
library("vegan")library("FactoMineR") # siehe Beispiel hier: https://www.youtube.com/watch?v=vP4korRby0Q# ebenfalls mit transformierten dateno.ca <-cca(sveg^0.5) # package vegano.ca1 <-CA(sveg^0.5) # package FactoMineR
# Arten (o) und Communities (+) plottenplot(o.ca)
summary(o.ca1)# Nur Arten plottenx <- o.ca$CA$u[, 1]y <- o.ca$CA$u[, 2]plot(x, y)
# Anteilige Varianz, die durch die ersten beiden Achsen erklaert wirdo.ca$CA$eig[1:63] /sum(o.ca$CA$eig)
NMDS mit sveg
# NMDS----------# Distanzmatrix als Start erzeugenlibrary("MASS")mde <-vegdist(sveg, method ="euclidean")mdm <-vegdist(sveg, method ="manhattan")# Zwei verschiedene NMDS-Methodenset.seed(1) # macht man, wenn man bei einer Wiederholung exakt die gleichen Ergebnisse willo.imds <-isoMDS(mde, k =2) # mit K = Dimensionenset.seed(1)o.mmds <-metaMDS(mde, k =3) # scheint nicht mit 2 Dimensionen zu konvergierenplot(o.imds$points)plot(o.mmds$points)# Stress = Abweichung der zweidimensionalen NMDS-Loesung von der originalen Distanzmatrixstressplot(o.imds, mde)stressplot(o.mmds, mde)
PCA mit mtcars
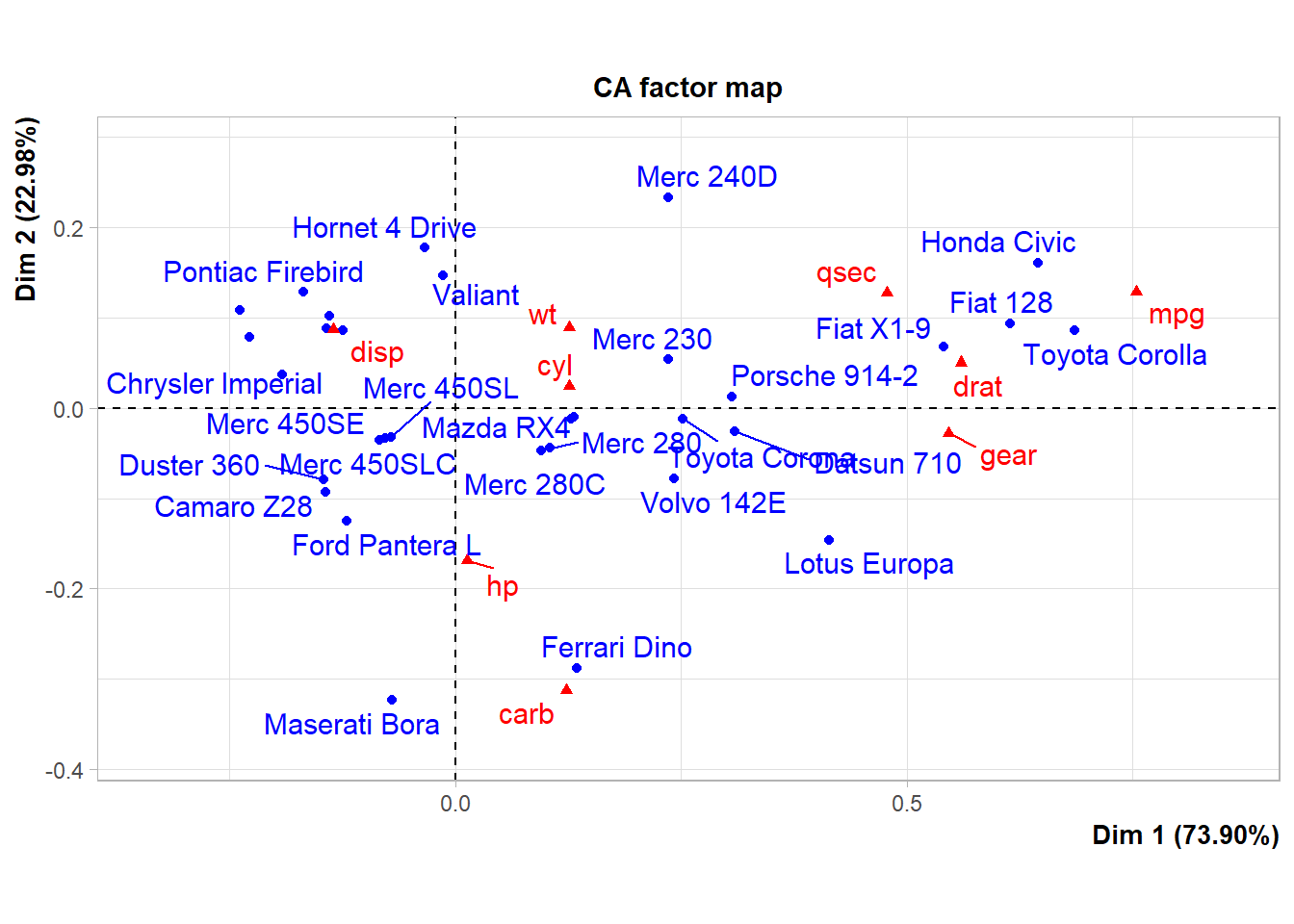
# Beispiel inspiriert von Luke Hayden: https://www.datacamp.com/community/tutorials/pca-analysis-r# Ausgangslage: viel zusammenhängende Variablen# Ziel: Reduktion der Variablenkomplexität# WICHTIG hier: Datenformat muss Wide sein! Damit die Matrixmultiplikation gemacht werden kann# lade Dateicars <- mtcars# Korrelationencor <-cor(cars[, c(1:7, 10, 11)])cor[abs(cor) < .7] <-0cor# definiere Datei für PCAcars <- mtcars[, c(1:7, 10, 11)]# pca# achtung unterschiedliche messeinheiten, wichtig es muss noch einheitlich transfomiert werdenlibrary("FactoMineR") # siehe Beispiel hier: https://www.youtube.com/watch?v=vP4korRby0Qo.pca <-PCA(cars, scale.unit =TRUE) # entweder korrelations oder covarianzmatrix# schaue output ansummary(o.pca) # generiert auch automatische plots
CA mit mtcars
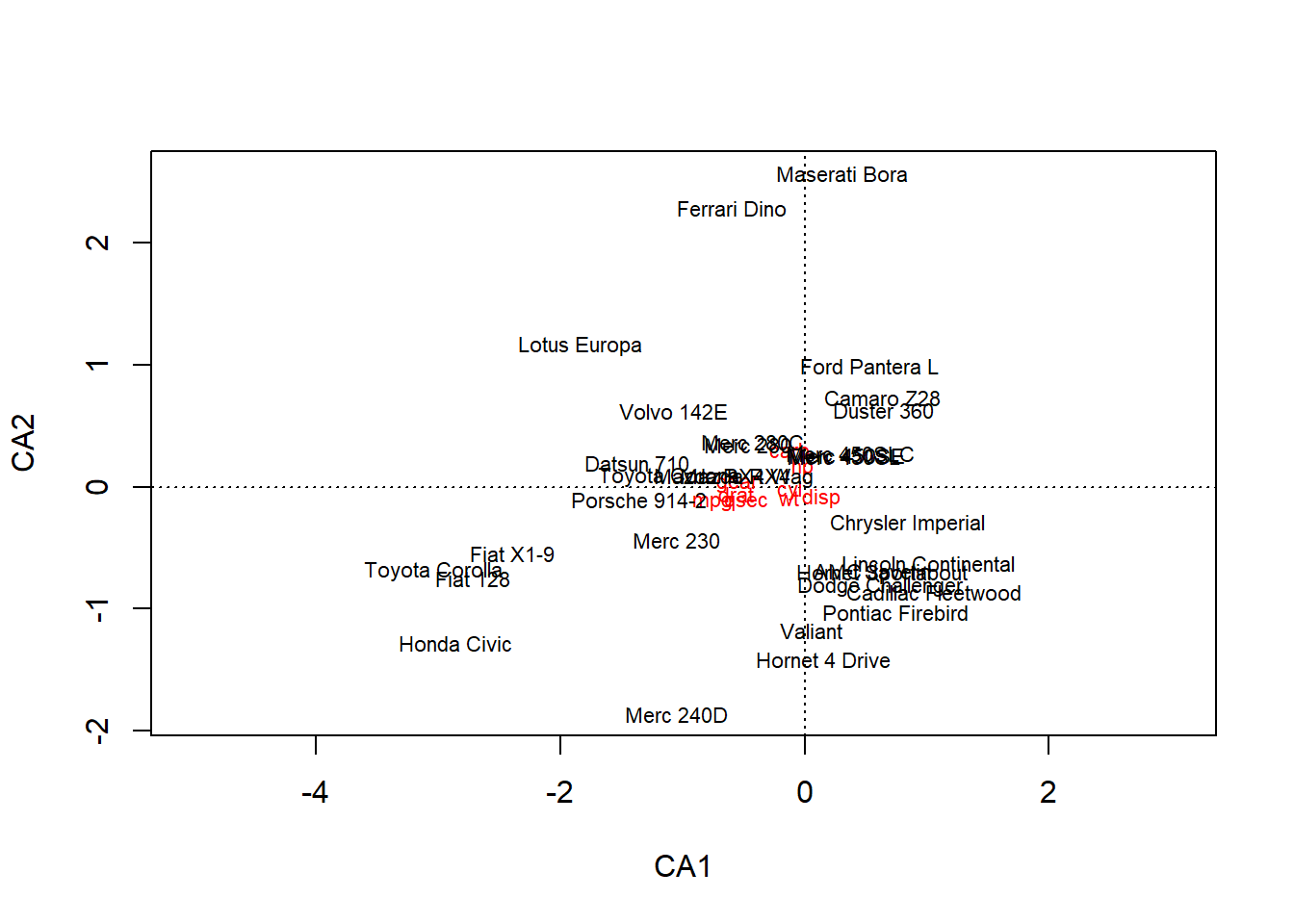
# ebenfalls mit transformierten dateno.ca <- vegan::cca(cars)o.ca1 <- FactoMineR::CA(cars) # blau: auots, rot: variablen
# Anteilige Varianz, die durch die ersten beiden Achsen erklaert wirdo.ca$CA$eig[1:8] /sum(o.ca$CA$eig)
NMDS mit mtcars
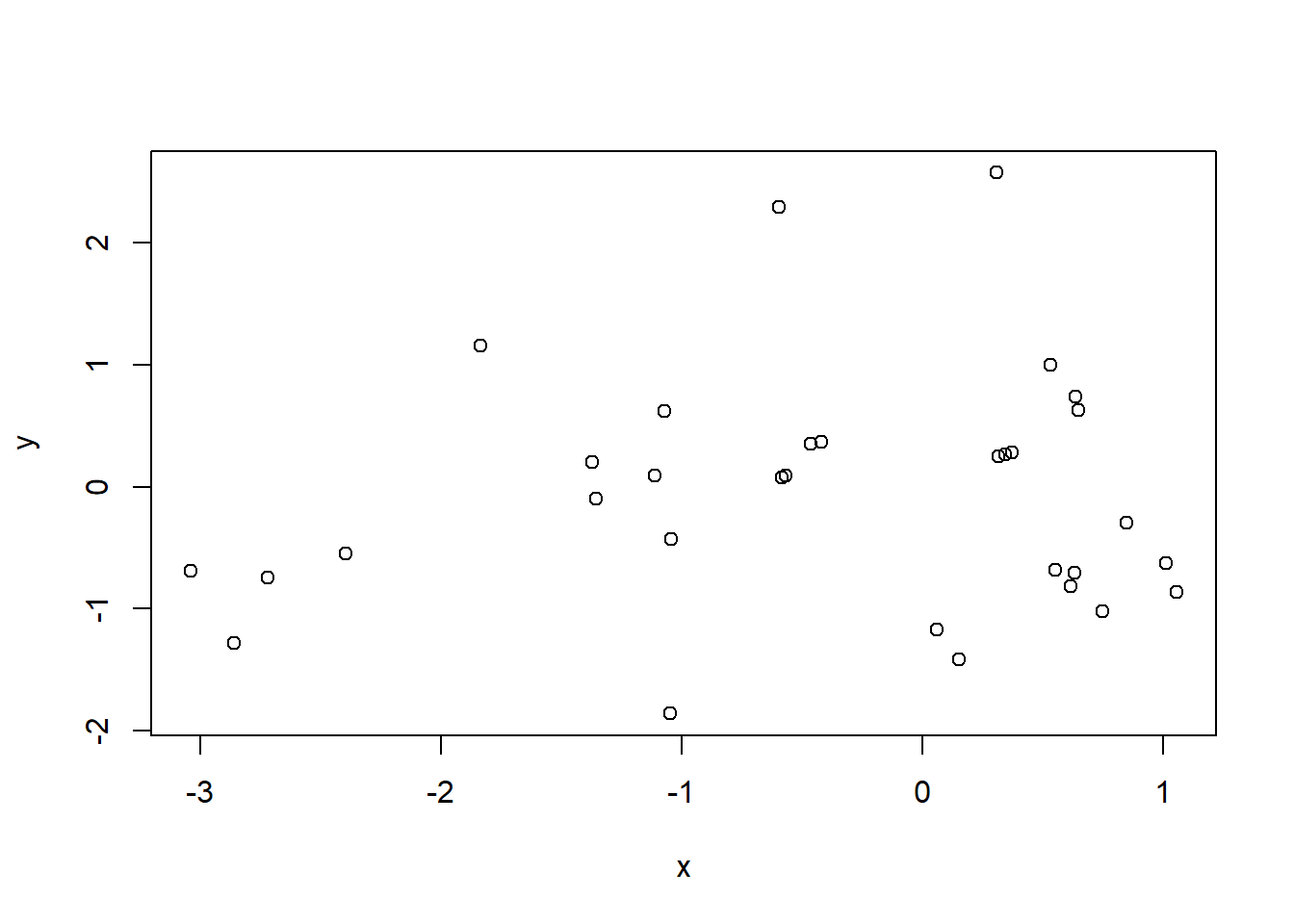
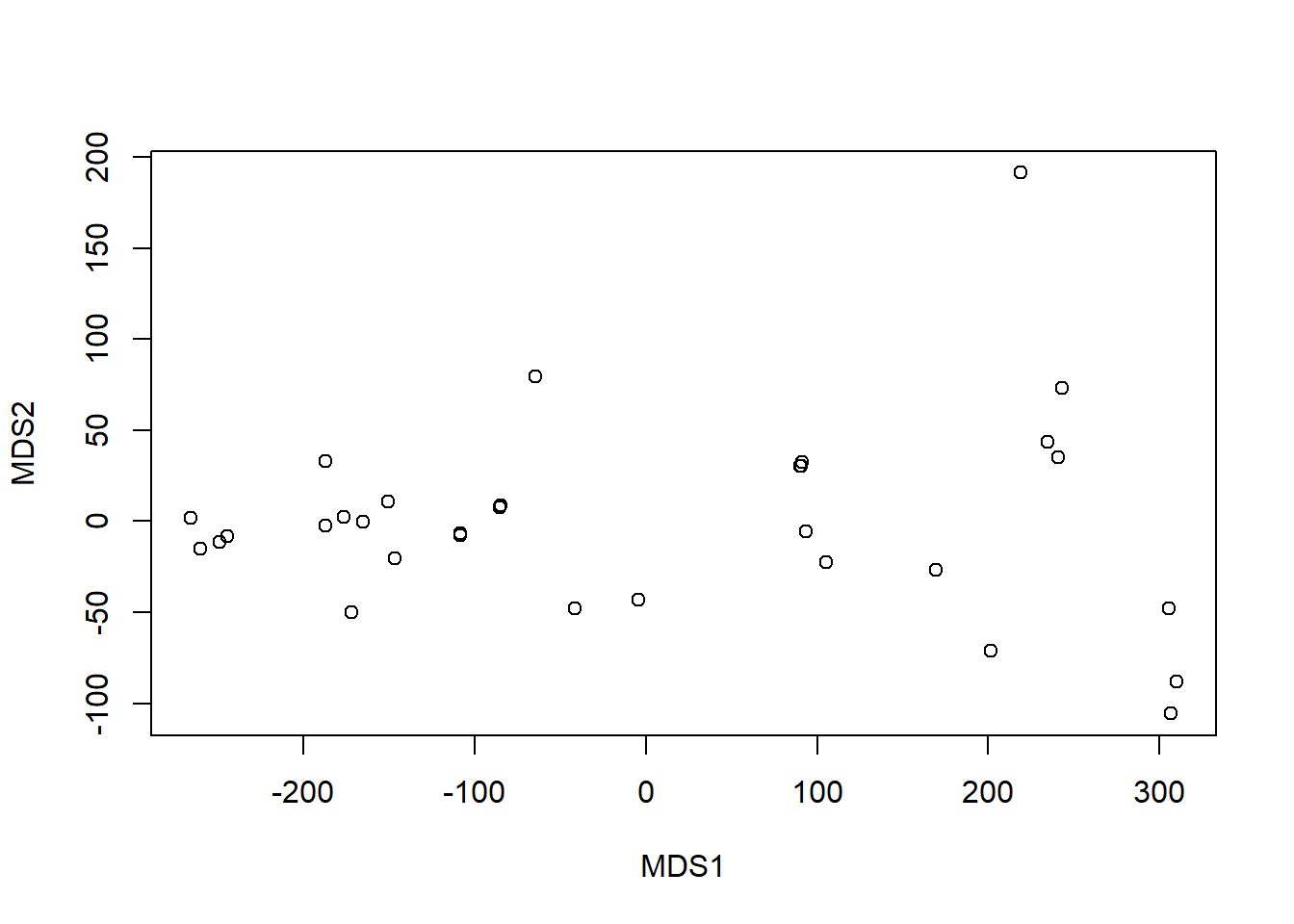
# Distanzmatrix als Start erzeugenmde <- vegan::vegdist(cars, method ="euclidean")mdm <- vegan::vegdist(cars, method ="manhattan")# Zwei verschiedene NMDS-Methodenset.seed(1) # macht man, wenn man bei einer Wiederholung exakt die gleichen Ergebnisse willo.mde.mass <- MASS::isoMDS(mde, k =2) # mit K = Dimensioneno.mdm.mass <- MASS::isoMDS(mdm)set.seed(1)o.mde.vegan <- vegan::metaMDS(mde, k =1) # scheint nicht mit 2 Dimensionen zu konvergiereno.mdm.vegan <- vegan::metaMDS(mdm, k =2)# plot euclidean distanceplot(o.mde.mass$points)
plot(o.mde.vegan$points)
# plot manhattan distanceplot(o.mdm.mass$points)
plot(o.mdm.vegan$points)
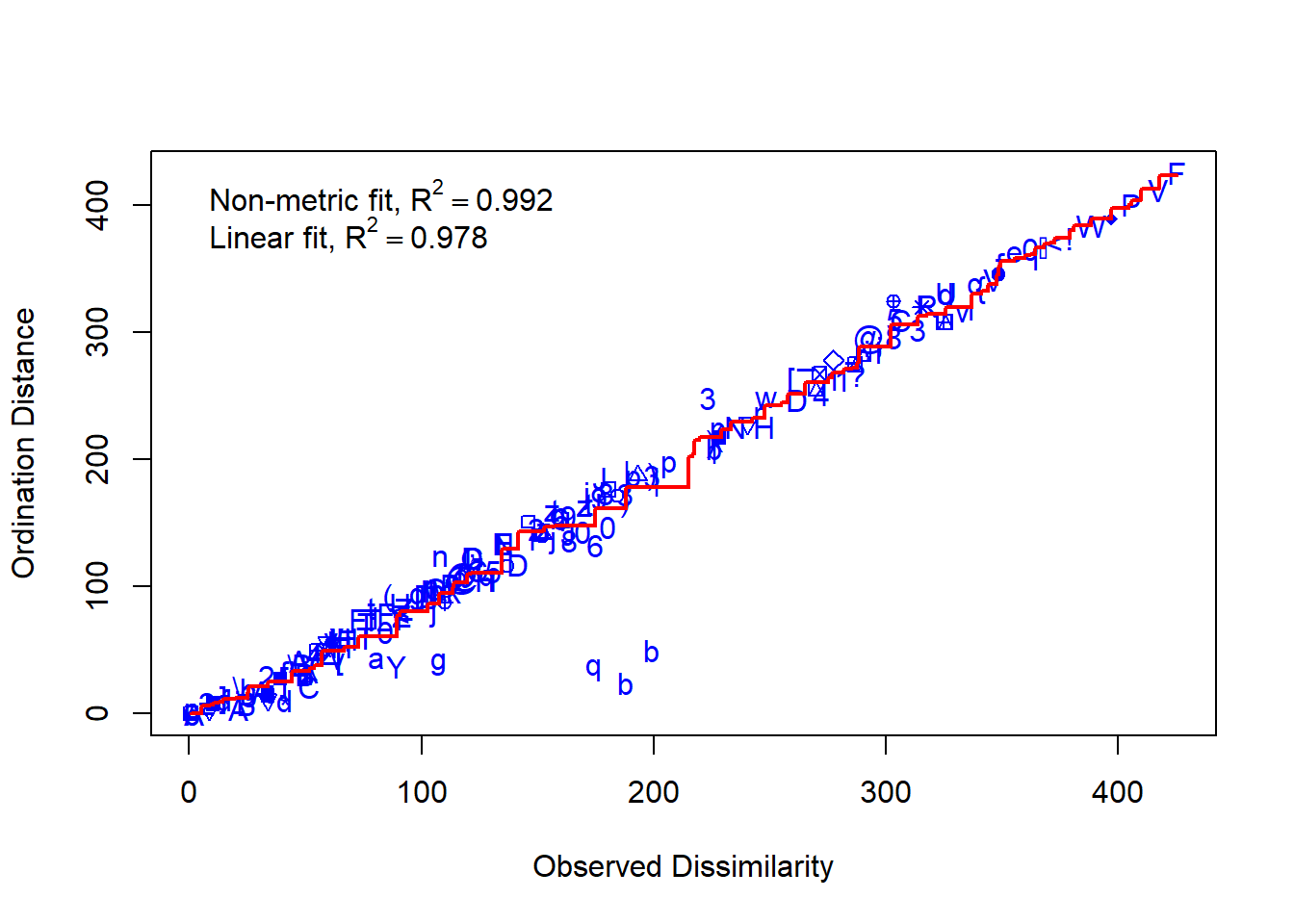
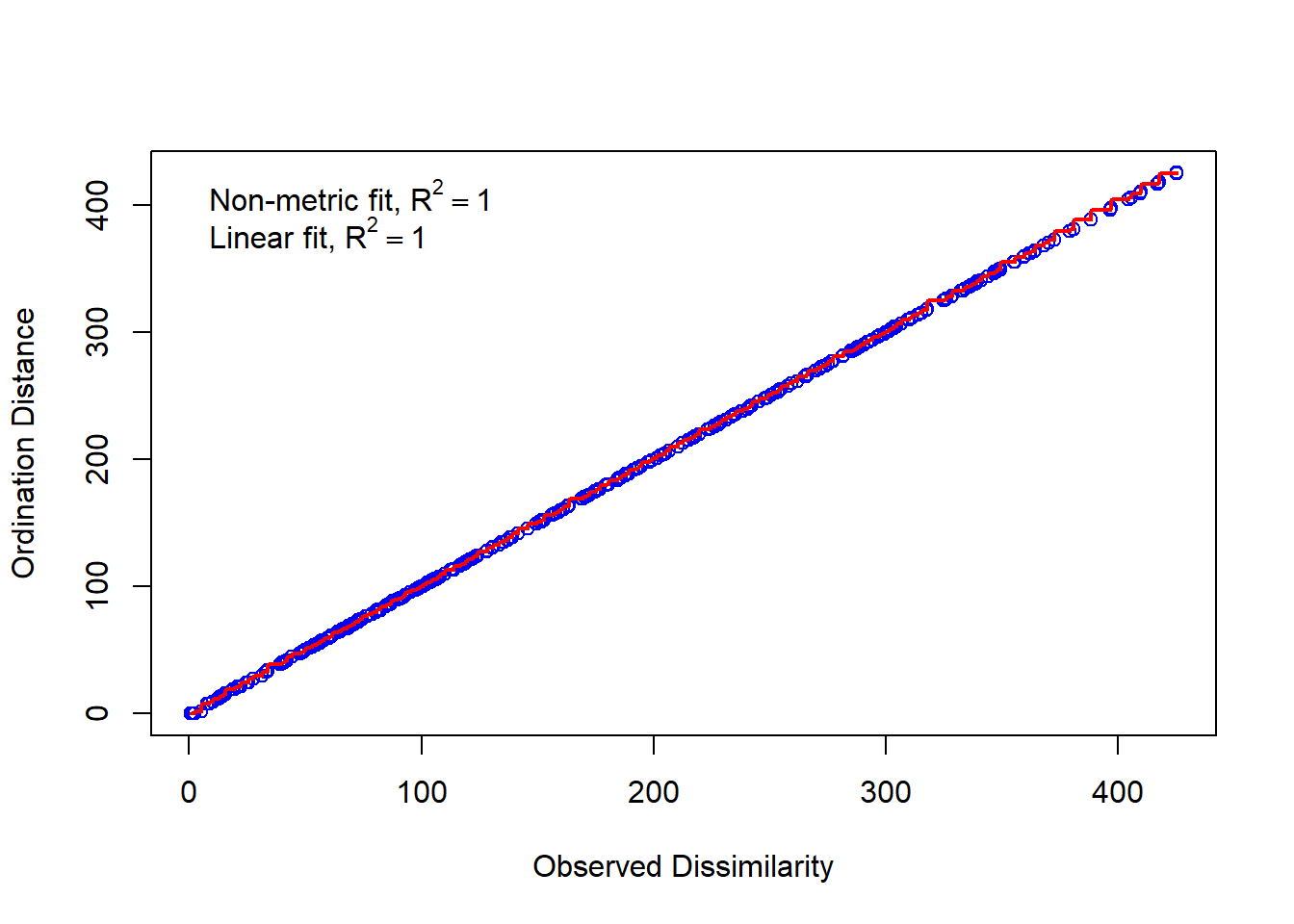
# Stress = Abweichung der zweidimensionalen NMDS-Loesung von der originalen Distanzmatrixvegan::stressplot(o.mde.vegan, mde)
vegan::stressplot(o.mde.mass, mde)
Wildi, Otto. 2017. Data analysis in vegetation ecology. Cabi.
Quellcode
---date: 2023-11-14lesson: StatKons2thema: PCAindex: 1format: html: code-tools: source: true---# StatKons2: Demo- Download dieses Demoscript via "\</\>Code" (oben rechts)- Datensatz *dave_sveg.csv* von @wildi2017```{r}#| echo: false#| results: hideknitr::opts_chunk$set(echo = T, collapse =TRUE, message =FALSE, results ="hide", warning =FALSE)```## PCA mit sveg```{r}# Mit Beispieldaten aus Wildi (2013, 2017)library("labdsv")library("readr")sveg <-read_delim("datasets/statKons/dave_sveg.csv")head(sveg)str(sveg)# View(sveg)# PCA-----------# Deckungen Wurzeltransformiert, cor=T erzwingt Nutzung der Korrelationsmatrixo.pca <- labdsv::pca(sveg^0.25, cor = T)o.pca2 <- stats::prcomp(sveg^0.25)# Koordinaten im Ordinationsraum => Yhead(o.pca$scores)head(o.pca2$x)# Korrelationen der Variablen mit den Ordinationsachsenhead(o.pca$loadings)head(o.pca2$rotation)# Erklaerte Varianz der Achsen (sdev ist die Wurzel daraus)# früher gabs den Befehl summary()# jetzt von hand: standardabweichung im quadrat/totale varianz * 100 (um prozentwerte zu bekommen)E <- o.pca$sdev^2/ o.pca$totdev *100E[1:5] # erste fünf PCA# package stats funktioniert summary()summary(o.pca2)# PCA-Plot der Lage der Beobachtungen im Ordinationsraumplot(o.pca$scores[, 1], o.pca$scores[, 2], type ="n", asp =1, xlab ="PC1", ylab ="PC2")points(o.pca$scores[, 1], o.pca$scores[, 2], pch =18)plot(o.pca$scores[, 1], o.pca$scores[, 3], type ="n", asp =1, xlab ="PC1", ylab ="PC3")points(o.pca$scores[, 1], o.pca$scores[, 3], pch =18)# Subjektive Auswahl von Arten zur Darstellungsel.sp <-c(3, 11, 23, 39, 46, 72, 77, 96, 101, 119)snames <-names(sveg[, sel.sp])snames# PCA-Plot der Korrelationen der Variablen (hier Arten) mit den Achsen# (hier reduction der observationen)x <- o.pca$loadings[, 1]y <- o.pca$loadings[, 2]plot(x, y, type ="n", asp =1)arrows(0, 0, x[sel.sp], y[sel.sp], length =0.08)text(x[sel.sp], y[sel.sp], snames, pos =1, cex =0.6)# hier gehts noch zu weiteren Beispielen zu PCA's:# https://stats.stackexchange.com/questions/102882/steps-done-in-factor-analysis-compared-to-steps-done-in-pca/102999#102999# https://stats.stackexchange.com/questions/222/what-are-principal-component-scores```## PCA mit Beispiel aus Skript```{r}# Idee von Ordinationen aus Wildi p. 73-74# Für Ordinationen benötigen wir Matrizen, nicht Data.frames# Generieren von Datenraw <-matrix(c(1, 2, 2.5, 2.5, 1, 0.5, 0, 1, 2, 4, 3, 1), nrow =6)colnames(raw) <-c("spec.1", "spec.2")rownames(raw) <-c("r1", "r2", "r3", "r4", "r5", "r6")raw# originale Daten im zweidimensionalen Raumx1 <- raw[, 1]y1 <- raw[, 2]z <-c(rep(1:6))# Plot Abhängigkeit der Arten vom Umweltgradientenplot(c(x1, y1) ~c(z, z),type ="n", axes = T, bty ="l", las =1, xlim =c(1, 6), ylim =c(0, 5),xlab ="Umweltgradient", ylab ="Deckung der Arten")points(x1 ~ z, pch =21, type ="b")points(y1 ~ z, pch =16, type ="b")# zentrierte Datencent <-scale(raw, scale = F)x2 <- cent[, 1]y2 <- cent[, 2]# rotierte Dateno.pca <-pca(raw)x3 <- o.pca$scores[, 1]y3 <- o.pca$scores[, 2]# Visualisierung der Schritte im Ordinationsraumplot(c(y1, y2, y3) ~c(x1, x2, x3),type ="n", axes = T, bty ="l", las =1, xlim =c(-4, 4),ylim =c(-4, 4), xlab ="Art 1", ylab ="Art 2")points(y1 ~ x1, pch =21, type ="b", col ="green", lwd =2)points(y2 ~ x2, pch =16, type ="b", col ="red", lwd =2)points(y3 ~ x3, pch =17, type ="b", col ="blue", lwd =2)# zusammengefasst:-------# Durchführung der PCApca <-pca(raw)# Koordinaten im Ordinationsraumpca$scores# Korrelationen der Variablen mit den Ordinationsachsenpca$loadings# Erklärte Varianz der Achsen in ProzentE <- pca$sdev^2/ pca$totdev *100E### excurs für weitere r-packages##### mit prcomp, ein weiteres Package für Ordinationenpca.2<- stats::prcomp(raw, scale = F)summary(pca.2)plot(pca.2)biplot(pca.2)# mit vegan, ein anderes Package für Ordinationenpca.3<- vegan::rda(raw, scale =FALSE) # Die Funktion rda führt ein PCA aus an wenn nicht Umwelt- und Artdaten definiert werden# scores(pca.3,display=c("sites"))# scores(pca.3,display=c("species"))summary(pca.3, axes =0)biplot(pca.3, scaling =2)biplot(pca.3, scaling ="species") # scaling=species macht das selbe wie scaling=2```## CA mit sveg```{r}library("vegan")library("FactoMineR") # siehe Beispiel hier: https://www.youtube.com/watch?v=vP4korRby0Q# ebenfalls mit transformierten dateno.ca <-cca(sveg^0.5) # package vegano.ca1 <-CA(sveg^0.5) # package FactoMineR# Arten (o) und Communities (+) plottenplot(o.ca)summary(o.ca1)# Nur Arten plottenx <- o.ca$CA$u[, 1]y <- o.ca$CA$u[, 2]plot(x, y)# Anteilige Varianz, die durch die ersten beiden Achsen erklaert wirdo.ca$CA$eig[1:63] /sum(o.ca$CA$eig)```## NMDS mit sveg```{r}#| eval: false# NMDS----------# Distanzmatrix als Start erzeugenlibrary("MASS")mde <-vegdist(sveg, method ="euclidean")mdm <-vegdist(sveg, method ="manhattan")# Zwei verschiedene NMDS-Methodenset.seed(1) # macht man, wenn man bei einer Wiederholung exakt die gleichen Ergebnisse willo.imds <-isoMDS(mde, k =2) # mit K = Dimensionenset.seed(1)o.mmds <-metaMDS(mde, k =3) # scheint nicht mit 2 Dimensionen zu konvergierenplot(o.imds$points)plot(o.mmds$points)# Stress = Abweichung der zweidimensionalen NMDS-Loesung von der originalen Distanzmatrixstressplot(o.imds, mde)stressplot(o.mmds, mde)```## PCA mit mtcars```{r}# Beispiel inspiriert von Luke Hayden: https://www.datacamp.com/community/tutorials/pca-analysis-r# Ausgangslage: viel zusammenhängende Variablen# Ziel: Reduktion der Variablenkomplexität# WICHTIG hier: Datenformat muss Wide sein! Damit die Matrixmultiplikation gemacht werden kann# lade Dateicars <- mtcars# Korrelationencor <-cor(cars[, c(1:7, 10, 11)])cor[abs(cor) < .7] <-0cor# definiere Datei für PCAcars <- mtcars[, c(1:7, 10, 11)]# pca# achtung unterschiedliche messeinheiten, wichtig es muss noch einheitlich transfomiert werdenlibrary("FactoMineR") # siehe Beispiel hier: https://www.youtube.com/watch?v=vP4korRby0Qo.pca <-PCA(cars, scale.unit =TRUE) # entweder korrelations oder covarianzmatrix# schaue output ansummary(o.pca) # generiert auch automatische plots```## CA mit mtcars```{r}# ebenfalls mit transformierten dateno.ca <- vegan::cca(cars)o.ca1 <- FactoMineR::CA(cars) # blau: auots, rot: variablen# plotten (schwarz: autos, rot: variablen)plot(o.ca)summary(o.ca)summary(o.ca1)# Nur autos plotten; wieso?x <- o.ca$CA$u[, 1]y <- o.ca$CA$u[, 2]plot(x, y)# Anteilige Varianz, die durch die ersten beiden Achsen erklaert wirdo.ca$CA$eig[1:8] /sum(o.ca$CA$eig)```## NMDS mit mtcars```{r}# Distanzmatrix als Start erzeugenmde <- vegan::vegdist(cars, method ="euclidean")mdm <- vegan::vegdist(cars, method ="manhattan")# Zwei verschiedene NMDS-Methodenset.seed(1) # macht man, wenn man bei einer Wiederholung exakt die gleichen Ergebnisse willo.mde.mass <- MASS::isoMDS(mde, k =2) # mit K = Dimensioneno.mdm.mass <- MASS::isoMDS(mdm)set.seed(1)o.mde.vegan <- vegan::metaMDS(mde, k =1) # scheint nicht mit 2 Dimensionen zu konvergiereno.mdm.vegan <- vegan::metaMDS(mdm, k =2)# plot euclidean distanceplot(o.mde.mass$points)plot(o.mde.vegan$points)# plot manhattan distanceplot(o.mdm.mass$points)plot(o.mdm.vegan$points)# Stress = Abweichung der zweidimensionalen NMDS-Loesung von der originalen Distanzmatrixvegan::stressplot(o.mde.vegan, mde)vegan::stressplot(o.mde.mass, mde)```