library("readr")
crime <- read_delim("datasets/stat5-8/crime2.csv", ";")Stat8: Lösung
- Download dieses Lösungsscript via “</>Code” (oben rechts)
- Lösungstext als Download
Musterlösung Aufgabe 8.1: Clusteranalysen
Übungsaufgabe
(hier so ausführlich formuliert, wie dies auch in der Klausur der Fall sein wird)
- Ladet den Datensatz crime2.csv. Dieser enthält Raten von 7 Kriminatlitätsformen pro 100000 Einwohner und Jahr für die Bundesstaaten der USA.
- Führt eine k-means- und eine agglomerative Clusteranalyse eurer Wahl durch. Bitte beachet, dass wegen der sehr ungleichen Varianzen in jedem Fall eine Standardisierung stattfinden muss, damit die Distanzen zwischen den verschiedenen Kriminalitätsraten sinnvoll berechnet werden können.
- Überlegt in beiden Fällen, wie viele Cluster sinnvoll sind (k-means: z. B. visuelle Betrachtung einer PCA, agglomertive Clusteranalyse: z. B. Silhoutte-Plot).
- Entscheidet euch dann für eine der beiden Clusterungen und vergleicht dann die erhaltenen Cluster bezüglich der Kriminalitätsformen und interpretiert die Cluster entsprechend.
- Bitte erklärt und begründet die einzelnen Schritte, die ihr unternehmt, um zu diesem Ergebnis zu kommen. Dazu erstellt bitte ein Word-Dokument, in das ihr Schritt für Schritt den verwendeten R-Code, die dazu gehörigen Ausgaben von R, eure Interpretation derselben und die sich ergebenden Schlussfolgerungen für das weitere Vorgehen dokumentieren.
- Formuliert abschliessend einen Methoden- und Ergebnisteil (ggf. incl. adäquaten Abbildungen) zu dieser Untersuchung in der Form einer wissenschaftlichen Arbeit (ausformulierte schriftliche Zusammenfassung, mit je einem Absatz von ca. 60-100 Worten, resp. 3-8 Sätzen für den Methoden- und Ergebnisteil). D. h. alle wichtigen Informationen sollten enthalten sein, unnötige Redundanz dagegen vermieden werden.
- Zu erstellen sind (a) Ein lauffähiges R-Skript; (b) begründeter Lösungsweg (Kombination aus R-Code, R Output und dessen Interpretation) und (c) ausformulierter Methoden- und Ergebnisteil (für eine wiss. Arbeit).
Lösung
crime# A tibble: 50 × 8
...1 Murder Rape Robbery Assault Burglary Theft Vehicle
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ME 2 14.8 28 102 803 2347 164
2 NH 2.2 21.5 24 92 755 2208 228
3 VT 2 21.8 22 103 949 2697 181
4 MA 3.6 29.7 193 331 1071 2189 906
5 RI 3.5 21.4 119 192 1294 2568 705
6 CT 4.6 23.8 192 205 1198 2758 447
7 NY 10.7 30.5 514 431 1221 2924 637
8 NJ 5.2 33.2 269 265 1071 2822 776
9 PA 5.5 25.1 152 176 735 1654 354
10 OH 5.5 38.6 142 235 988 2574 376
# ℹ 40 more rowsIm mitgelieferten R-Skript habe ich die folgenden Analysen zunächst mit untransformierten, dann mit standardisierten Kriminalitätsraten berechnet. Ihr könnt die Ergebnisse vergleichen und seht, dass sie sehr unterschiedlich ausfallen.
crimez <- crime
crimez[, c(2:8)] <- lapply(crime[, c(2:8)], scale)
crimez# A tibble: 50 × 8
...1 Murder[,1] Rape[,1] Robbery[,1] Assault[,1] Burglary[,1] Theft[,1]
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ME -1.38 -1.32 -1.05 -1.25 -0.939 -0.760
2 NH -1.32 -0.853 -1.08 -1.32 -1.05 -0.945
3 VT -1.38 -0.832 -1.10 -1.24 -0.591 -0.294
4 MA -0.919 -0.287 0.467 0.398 -0.300 -0.970
5 RI -0.948 -0.860 -0.212 -0.601 0.232 -0.466
6 CT -0.630 -0.694 0.458 -0.508 0.00320 -0.213
7 NY 1.14 -0.232 3.41 1.12 0.0580 0.00774
8 NJ -0.456 -0.0452 1.16 -0.0766 -0.300 -0.128
9 PA -0.369 -0.604 0.0908 -0.716 -1.10 -1.68
10 OH -0.369 0.328 -0.000917 -0.292 -0.498 -0.458
# ℹ 40 more rows
# ℹ 1 more variable: Vehicle <dbl[,1]>„scale“ führt eine Standardisierung (z-Transformation) durch, so dass alle Variablen anschiessen einen Mittelwert von 0 und eine SD von 1 haben, ausgenommen natürlich die 1. Spalte mit den Kürzeln der Bundesstaaten. Anschliessend wird das SSI-Kriterium getestet und zwar für Partitionierungen von 2 bis 6 Gruppen (wie viele Gruppen man maximal haben will, muss man pragmatisch nach der jeweiligen Fragestelltung entscheiden).
library("vegan")
crimez.KM.cascade <- cascadeKM(crimez[, c(2:8)],
inf.gr = 2, sup.gr = 6, iter = 100, criterion = "ssi"
)
summary(crimez.KM.cascade) Length Class Mode
partition 250 -none- numeric
results 10 -none- numeric
criterion 1 -none- character
size 30 -none- numeric crimez.KM.cascade$results 2 groups 3 groups 4 groups 5 groups 6 groups
SSE 174.959159 144.699605 124.437221 108.119280 95.316398
ssi 1.226057 1.304674 1.555594 1.539051 1.351146crimez.KM.cascade$partition 2 groups 3 groups 4 groups 5 groups 6 groups
1 2 2 4 4 6
2 2 2 4 4 6
3 2 2 4 4 6
4 1 1 2 5 2
5 2 1 3 5 2
6 2 1 3 5 5
7 1 1 2 3 1
8 1 1 2 5 2
9 2 2 3 1 5
10 2 1 3 1 5
11 2 2 3 1 5
12 1 1 2 3 1
13 1 3 1 3 3
14 2 2 4 4 6
15 2 2 4 4 6
16 2 2 4 4 6
17 1 1 3 1 1
18 2 2 4 4 6
19 2 2 4 4 6
20 2 2 4 4 6
21 2 2 3 1 5
22 2 1 3 1 5
23 1 1 2 3 1
24 2 2 3 1 5
25 2 2 4 4 6
26 2 1 3 1 5
27 1 1 3 1 1
28 1 1 1 3 1
29 1 3 1 3 3
30 2 2 3 1 5
31 1 1 2 1 1
32 2 1 3 1 5
33 2 2 3 1 5
34 2 2 3 1 5
35 1 3 1 3 1
36 1 1 1 2 4
37 1 3 1 3 3
38 2 2 4 4 6
39 2 2 4 4 6
40 2 2 4 4 6
41 1 3 1 2 4
42 1 3 1 2 4
43 1 3 1 2 4
44 2 2 4 4 6
45 1 3 1 3 3
46 1 3 1 2 4
47 1 3 1 2 4
48 1 3 1 3 3
49 1 3 1 2 4
50 2 2 3 4 5# k-means visualisation
library("cclust")
plot(crimez.KM.cascade, sortg = TRUE)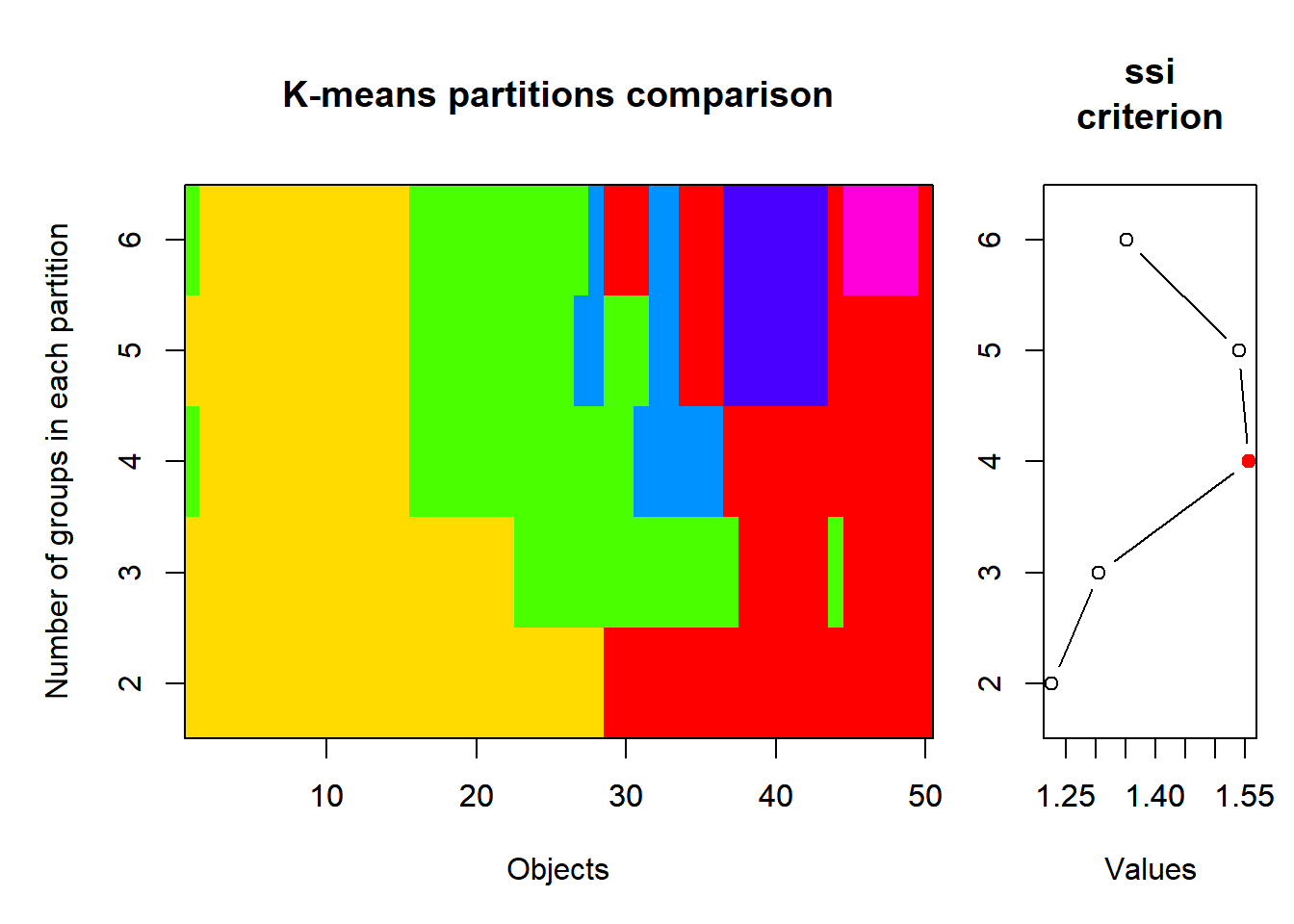
Nach SSI ist die 4-Gruppenlösung die beste, mit dieser wird also weitergerechnet.
# 4 Kategorien sind nach SSI offensichtlich besonders gut
modelz <- kmeans(crimez[, c(2:8)], 4)
modelzK-means clustering with 4 clusters of sizes 6, 22, 9, 13
Cluster means:
Murder Rape Robbery Assault Burglary Theft
1 0.3543004 1.22297941 0.03118143 0.6957454 1.3332749 1.5763188
2 -0.6982854 -0.77138855 -0.76544570 -0.8495717 -0.7970855 -0.4900018
3 1.3127382 0.94679752 1.65699740 1.2772894 0.9185274 0.6804530
4 0.1093718 0.08549954 0.13382617 0.2323462 0.0976527 -0.3693808
Vehicle
1 0.2190487
2 -0.8162838
3 1.1463189
4 0.4866986
Clustering vector:
[1] 2 2 2 4 4 4 3 4 2 4 2 3 3 2 2 2 4 2 2 2 2 4 3 2 2 4 4 4 3 2 4 4 2 2 3 4 3 2
[39] 2 2 1 1 1 2 3 1 1 3 1 2
Within cluster sum of squares by cluster:
[1] 13.15184 44.59027 27.50024 40.03154
(between_SS / total_SS = 63.5 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault" # File für ANOVA (Originaldaten der Vorfälle, nicht die ztransformierten)
crime.KM4 <- data.frame(crime, modelz[1])
crime.KM4$cluster <- as.factor(crime.KM4$cluster)
crime.KM4 ...1 Murder Rape Robbery Assault Burglary Theft Vehicle cluster
1 ME 2.0 14.8 28 102 803 2347 164 2
2 NH 2.2 21.5 24 92 755 2208 228 2
3 VT 2.0 21.8 22 103 949 2697 181 2
4 MA 3.6 29.7 193 331 1071 2189 906 4
5 RI 3.5 21.4 119 192 1294 2568 705 4
6 CT 4.6 23.8 192 205 1198 2758 447 4
7 NY 10.7 30.5 514 431 1221 2924 637 3
8 NJ 5.2 33.2 269 265 1071 2822 776 4
9 PA 5.5 25.1 152 176 735 1654 354 2
10 OH 5.5 38.6 142 235 988 2574 376 4
11 IN 6.0 25.9 90 186 887 2333 328 2
12 IL 8.9 32.4 325 434 1180 2938 628 3
13 MI 11.3 67.4 301 424 1509 3378 800 3
14 WI 3.1 20.1 73 162 783 2802 254 2
15 MN 2.5 31.8 102 148 1004 2785 288 2
16 IA 1.8 12.5 42 179 956 2801 158 2
17 MO 9.2 29.2 170 370 1136 2500 439 4
18 ND 1.0 11.6 7 32 385 2049 120 2
19 SD 4.0 17.7 16 87 554 1939 99 2
20 NE 3.1 24.6 51 184 748 2677 168 2
21 KS 4.4 32.9 80 252 1188 3008 258 2
22 DE 4.9 56.9 124 241 1042 3090 272 4
23 MD 9.0 43.6 304 476 1296 2978 545 3
24 VA 7.1 26.5 106 167 813 2522 219 2
25 WV 5.9 18.9 41 99 625 1358 169 2
26 NC 8.1 26.4 88 354 1225 2423 208 4
27 SC 8.6 41.3 99 525 1340 2846 277 4
28 GA 11.2 43.9 214 319 1453 2984 430 4
29 FL 11.7 52.7 367 605 2221 4373 598 3
30 KY 6.7 23.1 83 222 824 1740 193 2
31 TN 10.4 47.0 208 274 1325 2126 544 4
32 AL 10.1 28.4 112 408 1159 2304 267 4
33 MS 11.2 25.8 65 172 1076 1845 150 2
34 AR 8.1 28.9 80 278 1030 2305 195 2
35 LA 12.8 40.1 224 482 1461 3417 442 3
36 OK 8.1 36.4 107 285 1787 3142 649 4
37 TX 13.5 51.6 240 354 2049 3987 714 3
38 MT 2.9 17.3 20 118 783 3314 215 2
39 ID 3.2 20.0 21 178 1003 2800 181 2
40 WY 5.3 21.9 22 243 817 3078 169 2
41 CO 7.0 42.3 145 329 1792 4231 486 1
42 NM 11.5 46.9 130 538 1845 3712 343 1
43 AZ 9.3 43.0 169 437 1908 4337 419 1
44 UT 3.2 25.3 59 180 915 4074 223 2
45 NV 12.6 64.9 287 354 1604 3489 478 3
46 WA 5.0 53.4 135 244 1861 4267 315 1
47 OR 6.6 51.1 206 286 1967 4163 402 1
48 CA 11.3 44.9 343 521 1696 3384 762 3
49 AK 8.6 72.7 88 401 1162 3910 604 1
50 HI 4.8 31.0 106 103 1339 3759 328 2str(crime.KM4)'data.frame': 50 obs. of 9 variables:
$ ...1 : chr "ME" "NH" "VT" "MA" ...
$ Murder : num 2 2.2 2 3.6 3.5 4.6 10.7 5.2 5.5 5.5 ...
$ Rape : num 14.8 21.5 21.8 29.7 21.4 23.8 30.5 33.2 25.1 38.6 ...
$ Robbery : num 28 24 22 193 119 192 514 269 152 142 ...
$ Assault : num 102 92 103 331 192 205 431 265 176 235 ...
$ Burglary: num 803 755 949 1071 1294 ...
$ Theft : num 2347 2208 2697 2189 2568 ...
$ Vehicle : num 164 228 181 906 705 447 637 776 354 376 ...
$ cluster : Factor w/ 4 levels "1","2","3","4": 2 2 2 4 4 4 3 4 2 4 ...Von den agglomerativen Clusterverfahren habe ich mich für Ward’s minimum variance clustering entschieden, da dieses allgemein als besonders geeignet gilt.
Vor der Berechnung von crime.norm und crime.ch muss man die Spalte mit den Bundesstaatenkürzeln entfern.
library("cluster")
# Add rownames to the dataframe
crime <- as.data.frame(crime)
rownames(crime) <- crime$...1
crime2 <- crime[, -1]
# Agglomerative Clusteranalyse
crime.norm <- decostand(crime2, "normalize")
crime.ch <- vegdist(crime.norm, "euc")
# Attach site names to object of class 'dist'
attr(crime.ch, "Labels") <- rownames(crime2)
# Ward's minimum variance clustering
crime.ch.ward <- hclust(crime.ch, method = "ward.D2")
par(mfrow = c(1, 1))
plot(crime.ch.ward, labels = rownames(crime2), main = "Chord - Ward")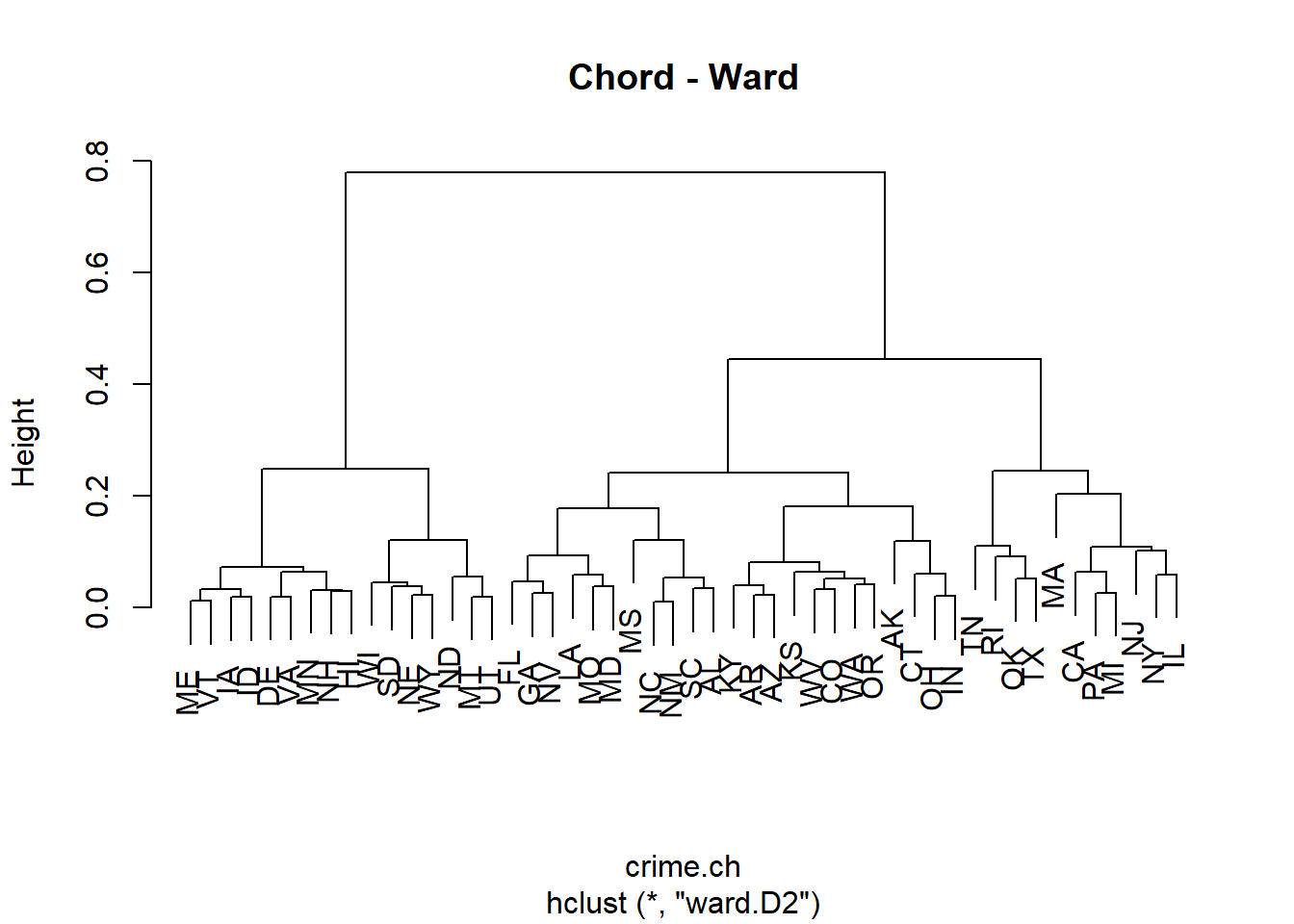
# Choose and rename the dendrogram ("hclust" object)
hc <- crime.ch.ward
# hc <- spe.ch.beta2
# hc <- spe.ch.complete
dev.new(title = "Optimal number of clusters", width = 12, height = 8, noRStudioGD = TRUE)
dev.off()png
2 par(mfrow = c(1, 2))
# Average silhouette widths (Rousseeuw quality index)
library("cluster")
Si <- numeric(nrow(crime))
for (k in 2:(nrow(crime) - 1))
{
sil <- silhouette(cutree(hc, k = k), crime.ch)
Si[k] <- summary(sil)$avg.width
}
k.best <- which.max(Si)
plot(1:nrow(crime), Si,
type = "h",
main = "Silhouette-optimal number of clusters",
xlab = "k (number of clusters)", ylab = "Average silhouette width"
)
axis(1, k.best, paste("optimum", k.best, sep = "\n"),
col = "red",
font = 2, col.axis = "red"
)
points(k.best, max(Si), pch = 16, col = "red", cex = 1.5)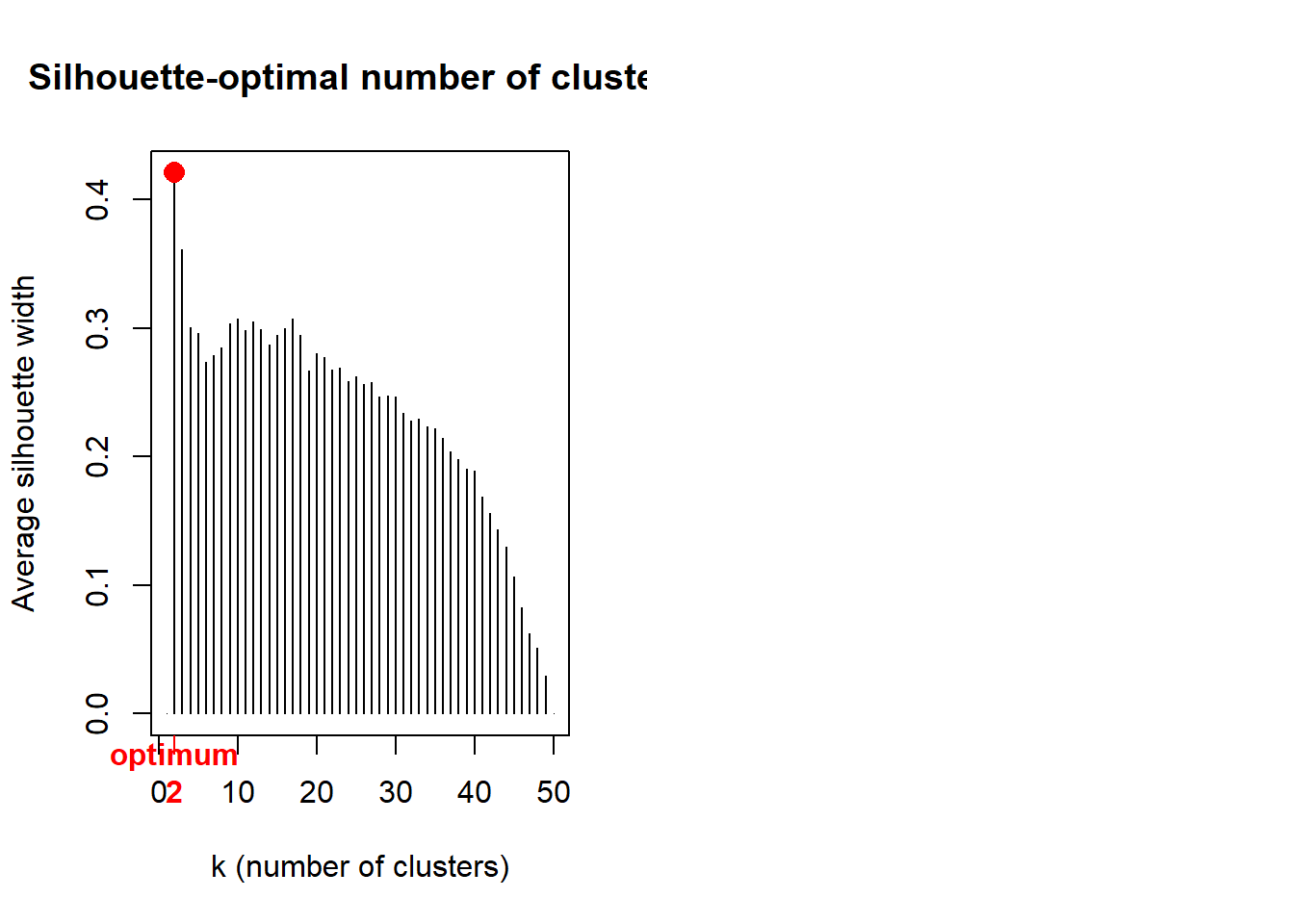
Demnach wären beim Ward’s-Clustering nur zwei Gruppen die optimale Lösung.
Für die Vergleiche der Bundesstaatengruppen habe ich mich im Folgenden für die k-means Clusterung mit 4 Gruppen entschieden.
Damit die Boxplots und die ANOVA direkt interpretierbar sind, werden für diese, anders als für die Clusterung, die untransformierten Incidenz-Werte verwendet (also crime statt crimez). Die Spalte mit der Clusterzugehörigkeit im Fall von k-means mit 4 Clustern hängt man als Spalte an (Achtung: muss als Faktor definiert werden!).
Anschliessend kann man die 7 ANOVAs rechnen, die Posthoc-Vergleiche durchführen und die zugehörigen Boxplots mit Buchstaben für die homogenen Gruppen erzeugen. Sinnvollerweise gruppiert man die Abbildungen gleich, z. B. je 2 x 2. Das Skript ist hier simple für jede Verbrechensart wiederholt. Erfahrenere R-Nutzer können das Ganze hier natürlich durch eine Schleife abkürzen.
library("multcomp")
par(mfrow = c(3, 3))
ANOVA.Murder <- aov(Murder ~ cluster, data = crime.KM4)
summary(ANOVA.Murder) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 324.0 107.99 19.05 3.58e-08 ***
Residuals 46 260.8 5.67
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Murder, linfct = mcp(cluster = "Tukey")))
boxplot(Murder ~ cluster, xlab = "Cluster", ylab = "Murder", data = crime.KM4)
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Rape <- aov(Rape ~ cluster, data = crime.KM4)
summary(ANOVA.Rape) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 6341 2113.6 24.69 1.14e-09 ***
Residuals 46 3938 85.6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Rape, linfct = mcp(cluster = "Tukey")))
boxplot(Rape ~ cluster, xlab = "Cluster", ylab = "Rape", data = crime.KM4)
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Robbery <- aov(Robbery ~ cluster, data = crime.KM4)
summary(ANOVA.Robbery) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 449894 149965 51.99 8.11e-15 ***
Residuals 46 132695 2885
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Robbery, linfct = mcp(cluster = "Tukey")))
boxplot(Robbery ~ cluster, xlab = "Cluster", ylab = "Robbery", data = crime.KM4)
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Assault <- aov(Assault ~ cluster, data = crime.KM4)
summary(ANOVA.Assault) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 661962 220654 35.32 5.35e-12 ***
Residuals 46 287341 6247
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Assault, linfct = mcp(cluster = "Tukey")))
boxplot(Assault ~ cluster, xlab = "Cluster", ylab = "Assault", data = crime.KM4)
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Burglary <- aov(Burglary ~ cluster, data = crime.KM4)
summary(ANOVA.Burglary) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 5692055 1897352 29.82 7.35e-11 ***
Residuals 46 2926800 63626
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Burglary, linfct = mcp(cluster = "Tukey")))
boxplot(Burglary ~ cluster, data = crime.KM4, xlab = "Cluster", ylab = "Burglary")
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Theft <- aov(Theft ~ cluster, data = crime.KM4)
summary(ANOVA.Theft) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 14771705 4923902 17.52 9.98e-08 ***
Residuals 46 12926846 281018
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Theft, linfct = mcp(cluster = "Tukey")))
boxplot(Theft ~ cluster, xlab = "Cluster", ylab = "Theft", data = crime.KM4)
mtext(letters$mcletters$Letters, at = 1:6)
ANOVA.Vehicle <- aov(Vehicle ~ cluster, data = crime.KM4)
summary(ANOVA.Vehicle) Df Sum Sq Mean Sq F value Pr(>F)
cluster 3 1313441 437814 23.91 1.79e-09 ***
Residuals 46 842430 18314
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1letters <- cld(glht(ANOVA.Vehicle, linfct = mcp(cluster = "Tukey")))
boxplot(Vehicle ~ cluster, data = crime.KM4, xlab = "Cluster", ylab = "Vehicle")
mtext(letters$mcletters$Letters, at = 1:6)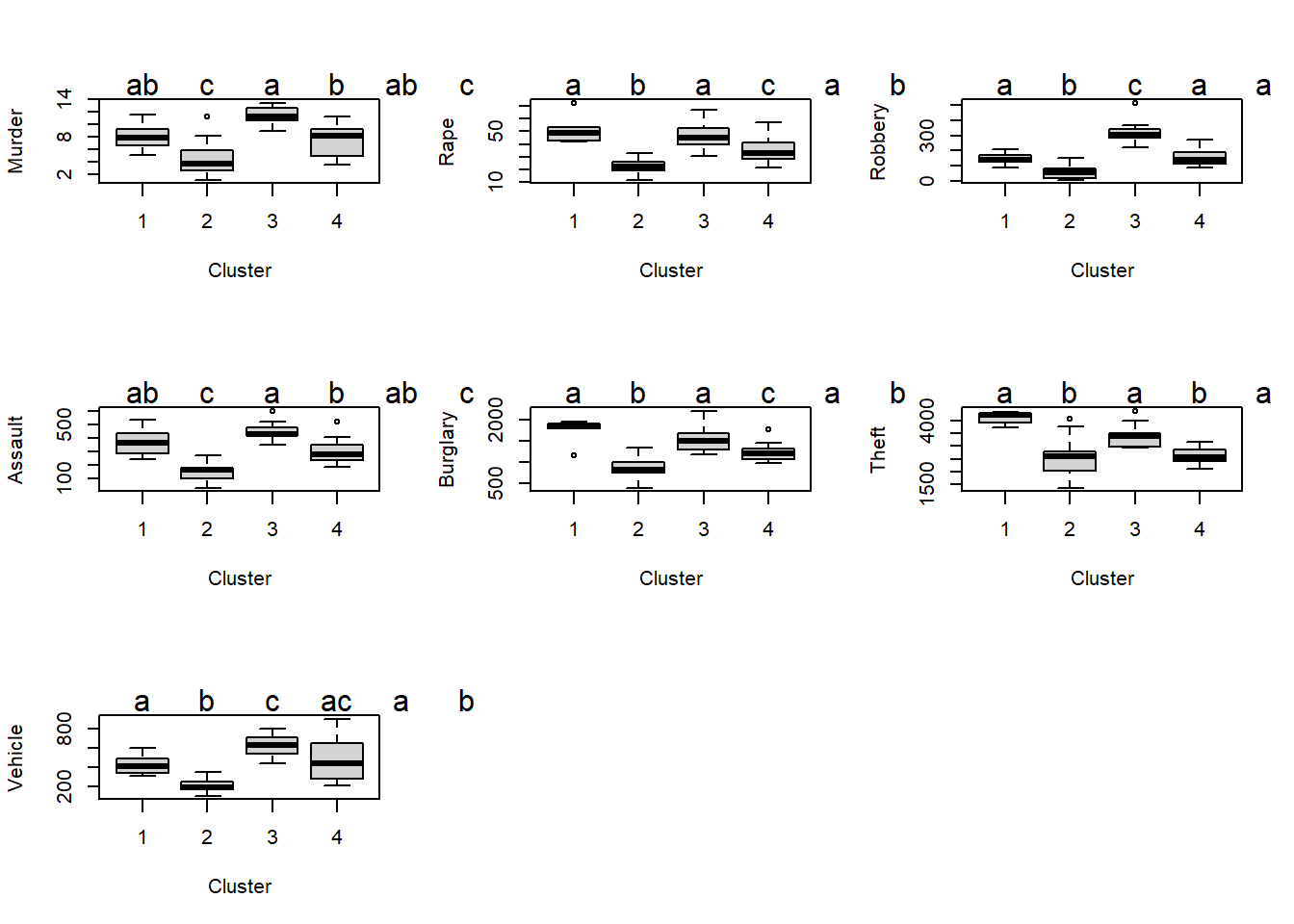
Die Boxplots erlauben jetzt auch eine Beurteilung der Modelldiagnostik: sind die Residuen hinreichen normalverteilt (symmetrisch) und sind die Varianzen zwischen den Kategorien einigermassen ähnlich. Mit der Symmetrie/Normalverteilung sieht es OK aus. Die Varianzhomogenität ist nicht optimal – meist deutlich grössere Varianz bei höheren Mittelwerten. Eine log-Transformation hätte das verbessert und könnte hier gut begründet werden. Da die p-Werte sehr niedrig waren und die Varianzheterogenität noch nicht extrem war, habe ich aber von einer Transformation abgesehen, da jede Transformation die Interpretation der Ergebnisse erschwert. Jetzt muss man nur noch herausfinden, welche Bundesstaaten überhaupt zu welchem der vier Cluster gehören, sonst ist das ganze schöne Ergebnis nutzlos. Z. B. kann man in R auf den Dataframe clicken und ihn nach cluster sortieren.