# .##################################################################################
# Daten(vor)verarbeitung Fallstudie WPZ ####
# Modul Research Methods, HS23. Autor/in ####
# .##################################################################################BiEc2_N Daten(vor)verarbeitung
Projektaufbau RStudio-Projekte
Vor den eigentlichen Auswertungen müssen einige vorbereitende Arbeiten unternommen werden. Die Zeit, die man hier investiert, wird in der späteren Projektphase um ein vielfaches eingespart. Im Skript soll die Ordnerstruktur des Projekts genannt werden, damit der Arbeitsvorgang auf verschiedenen Rechnern reproduzierbar ist.
Arbeitet mit Projekten, da diese sehr einfach ausgetauscht und somit auch reproduziert werden önnen; es gibt keine absoluten Arbeitspfade sondern nur relative. Der Datenimport (und auch der Export) kann mithilfe dieser relativen Pfaden stark vereinfacht werden. Projekte helfen alles am richtigen Ort zu behalten. (mehr zur Arbeit mit Projekten: Link)
Aufbau von R-Skripten
Im Kopf des Skripts zuerst immer den Titel des Projekts sowie die Autor:innen des Skripts nennen. Hier soll auch die Herkunft der Daten ersichtlich sein und falls externe Daten verwendet werden, sollte geklärt werden, wer die Datenherrschaft hat (Rehdaten: Forschungsgruppe WILMA).
Beschreibt zudem folgendes:
- Ordnerstruktur; ich verwende hier den Projektordner mit den Unterordnern:
- Skripts
- Data
- Results
- Plots
- Verwendete Daten
Ein Skript soll in R eigentlich immer nach dem selbem Schema aufgebaut sein. Dieses Schema beinhaltet (nach dem bereits erwähnten Kopf des Skripts) 4 Kapitel:
- Datenimport
- Datenvorverarbeitung
- Analyse
- Visualisierung
Bereitet euer Skript also nach dieser Struktur vor. Nutzt für den Text, welcher nicht Code ist, vor dem Text das Symbol #. Wenn ihr den Text als Titel definieren wollt, der die grobe Struktur des Skripts absteckt, baut in wie in folgendem Beispiel auf:
# .###################################################################################
# METADATA ####
# .###################################################################################
# Datenherkunft ####
# ...
# .###################################################################################
# 1. DATENIMPORT ####
# .###################################################################################Libraries laden
library("readr")
library("dplyr")
library("ggplot2")Daten laden
Herunterladen der Daten der Feldaufnahmen von Moodle (Aufgabe3_Feldaufnahmen_alle_Gruppen.zip), Einlesen, Sichtung der Datensätze und der Datentypen.
Verschiedene Dinge funktionieren nicht auf Anhieb:
- Daten Gruppe 1: erste Zeile = Spaltenbezeichnungen
- Daten Gruppe 3 = Excelfile
- Daten Gruppe 5: erste Zeile = zusätzlicher Titel
- Datentypen Gruppen 1 & 5 = character statt numeric
Versucht diese Dinge direkt mit R zu lösen, damit die Datensätze zu einem sauberen Gesamtdatensatz zusammengefügt werden können
Code
df_team1 <- read_delim("datasets/fallstudie_n/Aufgabe3_Feldaufnahmen_alle_Gruppen/Felderhebung Waldstruktur Team 1.csv", delim = ";") %>%
purrr::set_names(as.character(slice(., 1))) %>%
slice(-1) %>%
mutate_if(is.character, as.numeric)
df_team2 <- read_delim("datasets/fallstudie_n/Aufgabe3_Feldaufnahmen_alle_Gruppen/Gruppe_2_Deckungsgrade.csv", delim = ";")
df_team3 <- read_delim("datasets/fallstudie_n/Aufgabe3_Feldaufnahmen_alle_Gruppen/Feldaufnahmen_LiDAR.csv", delim = ";")
df_team4 <- read_delim("datasets/fallstudie_n/Aufgabe3_Feldaufnahmen_alle_Gruppen/Felderhebung_Waldstruktur_Team4.csv", delim = ";")
df_team5 <- read_delim("datasets/fallstudie_n/Aufgabe3_Feldaufnahmen_alle_Gruppen/Felderhebung_Waldstruktur_Team_5.csv", delim = ";") %>%
purrr::set_names(as.character(slice(., 1))) %>%
slice(-1) %>%
mutate_if(is.character, as.numeric)
# hier können die Probekreise mit den Angaben zur Anzahl Rehlokalisationen und der
# LIDAR-basierten Ableitung der Waldstruktur eingelesen werden
df_reh <- read_delim("datasets/fallstudie_n/Aufgabe3_Reh_Waldstruktur_231014.csv", delim = ";")
str(df_reh)
## spc_tbl_ [305 × 7] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ Anz_reh_lokalisationen: num [1:305] 0 0 0 0 0 0 0 0 0 0 ...
## $ x : num [1:305] 684900 684900 684900 684900 684875 ...
## $ y : num [1:305] 237100 237125 237150 237175 237075 ...
## $ DG_us_2014 : num [1:305] 0.0903 0.2717 0.468 0.7407 0.1811 ...
## $ DG_os_2014 : num [1:305] 0.908 0.959 0.871 0.986 0.86 ...
## $ DG_us_2022 : num [1:305] 0.269 0.823 0.936 0.359 0.245 ...
## $ DG_os_2022 : num [1:305] 0.945 0.99 0.953 0.997 0.898 ...
## - attr(*, "spec")=
## .. cols(
## .. Anz_reh_lokalisationen = col_double(),
## .. x = col_double(),
## .. y = col_double(),
## .. DG_us_2014 = col_double(),
## .. DG_os_2014 = col_double(),
## .. DG_us_2022 = col_double(),
## .. DG_os_2022 = col_double()
## .. )
## - attr(*, "problems")=<externalptr>
# Die eingelesenen Datensätze anschauen und versuchen zu einem Gesamtdatensatz
# verbinden. Ist der Output zufriedenstellend?
df_gesamt <- bind_rows(df_team1, df_team2, df_team3, df_team4, df_team5)
str(df_gesamt)
## tibble [125 × 10] (S3: tbl_df/tbl/data.frame)
## $ Kreis (r 12.5m) : num [1:125] 0 1 2 3 4 5 6 7 8 9 ...
## $ X : num [1:125] 684900 684875 684875 684875 684850 ...
## $ Y : num [1:125] 237175 237125 237175 237250 237225 ...
## $ Deckungsgrad Rubus sp. [%] : num [1:125] 20 70 45 40 75 10 40 50 10 45 ...
## $ DG Strauchschicht [%] (0.5-3m): num [1:125] 50 60 60 40 55 95 75 75 45 55 ...
## $ DG Baumschicht [%] (ab 3m) : num [1:125] 55 80 85 70 65 100 80 85 85 95 ...
## $ DG Strauchschicht [%] : num [1:125] NA NA NA NA NA NA NA NA NA NA ...
## $ DG Baumschicht [%] : num [1:125] NA NA NA NA NA NA NA NA NA NA ...
## $ Bemerkung : chr [1:125] NA NA NA NA ...
## $ Datum : chr [1:125] NA NA NA NA ...Aufgabe 1
- 1.1 Einfügen zusätzliche Spalte pro Datensatz mit der Gruppenzugehörigkeit (Team1-5)
- 1.2 Spaltenumbenennung damit die Bezeichungen in allen Datensätzen gleich sind und der Gesamtdatensatz zusammengefügt werden kann
- → Befehle mutate und rename, mit pipes (alt:
%>%, neu:|>) in einem Schritt möglich
- → Befehle mutate und rename, mit pipes (alt:
Code
# .#################################################################################
# 2. DATENVORVERARBEITUNG #####
# .#################################################################################
df_team1 <- df_team1 |>
mutate(team = "team1") |>
rename(
KreisID = "Kreis (r 12.5m)",
DG_Rubus = "Deckungsgrad Rubus sp. [%]",
DG_Strauchschicht = "DG Strauchschicht [%] (0.5-3m)",
DG_Baumschicht = "DG Baumschicht [%] (ab 3m)"
)
df_team2 <- df_team2 |>
mutate(team = "team2") |>
rename(
KreisID = "Kreis (r 12.5m)",
DG_Rubus = "Deckungsgrad Rubus sp. [%]",
DG_Strauchschicht = "DG Strauchschicht [%]",
DG_Baumschicht = "DG Baumschicht [%]"
)
df_team3 <- df_team3 |>
mutate(team = "team3") |>
rename(
KreisID = "Kreis (r 12.5m)",
DG_Rubus = "Deckungsgrad Rubus sp. [%]",
DG_Strauchschicht = "DG Strauchschicht [%] (0.5-3m)",
DG_Baumschicht = "DG Baumschicht [%] (ab 3m)"
)
df_team4 <- df_team4 |>
mutate(team = "team4") |>
rename(
KreisID = "Kreis (r 12.5m)",
DG_Rubus = "Deckungsgrad Rubus sp. [%]",
DG_Strauchschicht = "DG Strauchschicht [%] (0.5-3m)",
DG_Baumschicht = "DG Baumschicht [%] (ab 3m)"
)
df_team5 <- df_team5 |>
mutate(team = "team5") |>
rename(
KreisID = "Kreis (r 12.5m)",
DG_Rubus = "Deckungsgrad Rubus sp. [%]",
DG_Strauchschicht = "DG Strauchschicht [%] (0.5-3m)",
DG_Baumschicht = "DG Baumschicht [%] (ab 3m)"
)Aufgabe 2
Zusammenführen der Teildatensätze zu einem Datensatz
Code
df_gesamt <- bind_rows(df_team1, df_team2, df_team3, df_team4, df_team5)Aufgabe 3
Verbinden (join) des Datensatzes der Felderhebungen mit dem Datensatz der Rehe (Aufgabe3_Reh_Waldstruktur_231014.csv).
Ziel: ein Datensatz mit allen Kreisen der Felderhebung, angereichert mit den Umweltvariablen Understory und Overstory aus den LIDAR-Daten (DG_us_2022, DG_os_2022) aus dem Rehdatensatz. –> Welche Art von join? Welche Spalten zum Verbinden (by = ?) der Datensätze
Code
df_with_LIDAR <- left_join(df_gesamt, df_reh, by = c("X" = "x", "Y" = "y"))Aufgabe 4
Scatterplot der korrespondondierenden Umweltvariablen aus den Felderhebungen gegen die Umweltvariablen aus den LIDAR-Daten (DG_xy_2022) erstellen (zusätzlich Einfärben der Gruppen und Regressionslinie darüberlegen). Korrelieren die Feldaufnahmen und die LiDAR basierte Waldstruktur?
Im Reh Datensatz gibt es dieselben Variablen der Waldstruktur aus der LiDAR-Befliegung 2014. Ihr könnt untersuchen wie sich diese verändert haben und wie gut oder eben auch nicht sie mit euren Feldaufnahmen übereinstimmen.
Code
# .#####################################################################################
# 4. VISUALISERUNG #####
# .#####################################################################################
ggplot(df_with_LIDAR, aes(DG_us_2022, DG_Strauchschicht, color = team)) +
geom_point() +
stat_smooth(method = "lm")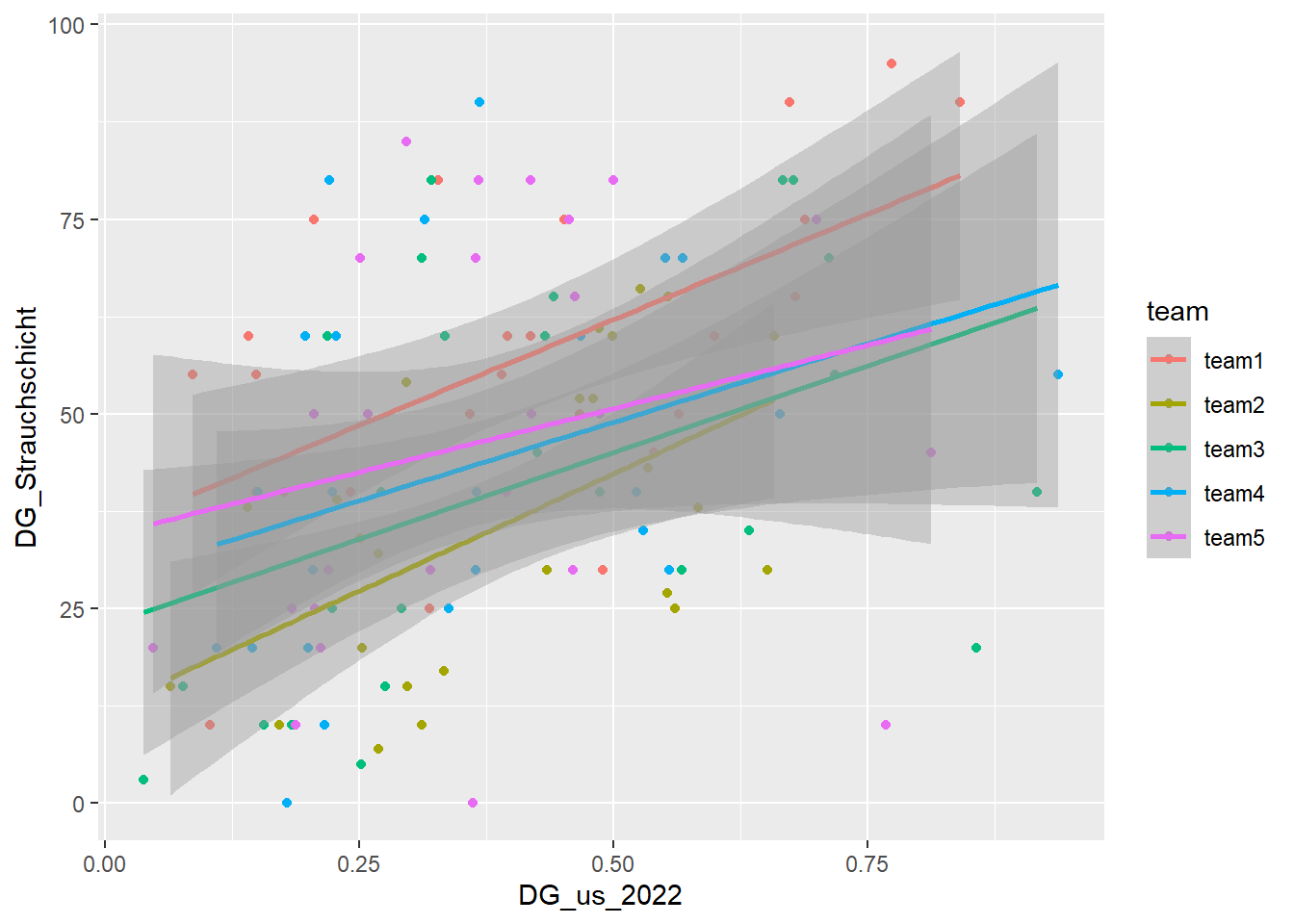
Code
write_delim(df_with_LIDAR, "datasets/fallstudie_n/df_with_lidar.csv", delim = ";")