library("readr")
splityield <- read_delim("datasets/stat5-8/splityield.csv", ",", col_types = cols("block" = "f", "irrigation" = "f", "density" = "f", "fertilizer" = "f"))Stat5: Lösung 1
- Download dieses Lösungsscript via “</>Code” (oben rechts)
- Lösungstext als Download
Musterlösung Aufgabe 5.1: Split-plot ANOVA
Übungsaufgabe
(hier so ausführlich formuliert, wie dies auch in der Klausur der Fall sein wird)
- Ladet den Datensatz splityield.csv. Dieser enthält Versuchsergebnisse eines Experiments zum Ernteertrag (yield) einer Kulturpflanze in Abhängigkeit der drei Faktoren Bewässerung (irrigated vs. control), Düngung (N, NP, P) und Aussaatdichten (low, medium, high). Es gab vier ganze Felder (block), die zwei Hälften mit den beiden Bewässerungstreatments (irrigation), diese wiederum drei Drittel für die drei Saatdichten (density) und diese schliesslich je drei Drittel für die drei Düngertreatments (fertilizer) hatten.
- Ermittelt das minimal adäquate statistische Modell, das den Ernteertrag in Abhängigkeit von den angegebenen Faktoren beschreibt.
- Bitte erklärt und begründet die einzelnen Schritte, die ihr unternehmt, um zu diesem Ergebnis zu kommen. Dazu erstellt bitte ein Word-Dokument, in das ihr Schritt für Schritt den verwendeten R-Code, die dazu gehörigen Ausgaben von R, eure Interpretation derselben und die sich ergebenden Schlussfolgerungen für das weitere Vorgehen dokumentieren.
- Dieser Ablauf sollte insbesondere beinhalten:
- Überprüfen der Datenstruktur nach dem Einlesen, welches sind die abhängige(n) und welches die unabängige(n) Variablen
- Explorative Datenanalyse, um zu sehen, ob evtl. Dateneingabefehler vorliegen oder Datentransformationen vorgenommen werden sollten
- Auswahl und Begründung eines statistischen Verfahrens
- Bestimmung des vollständigen/maximalen Models
- Selektion des/der besten Models/Modelle
- Generieren aller Zahlen, Statistiken und Tabellen, die für eine wiss. Ergebnisdarstellung benötigt werden
- Formuliert abschliessend einen Methoden- und Ergebnisteil (ggf. incl. adäquaten Abbildungen) zu dieser Untersuchung in der Form einer wissenschaftlichen Arbeit (ausformulierte schriftliche Zusammenfassung, mit je einem Absatz von ca. 60-100 Worten, resp. 3-8 Sätzen für den Methoden- und Ergebnisteil). D. h. alle wichtigen Informationen sollten enthalten sein, unnötige Redundanz dagegen vermieden werden.
- Zu erstellen sind (a) Ein lauffähiges R-Skript; (b) begründeter Lösungsweg (Kombination aus R-Code, R Output und dessen Interpretation) und (c) ausformulierter Methoden- und Ergebnisteil (für eine wiss. Arbeit).
Kommentierter Lösungsweg
# Checken der eingelesenen Daten
splityield# A tibble: 72 × 6
...1 yield block irrigation density fertilizer
<dbl> <dbl> <fct> <fct> <fct> <fct>
1 1 90 A control low N
2 2 95 A control low P
3 3 107 A control low NP
4 4 92 A control medium N
5 5 89 A control medium P
6 6 92 A control medium NP
7 7 81 A control high N
8 8 92 A control high P
9 9 93 A control high NP
10 10 80 A irrigated low N
# ℹ 62 more rowsMan sieht, dass das Design vollkommen balanciert ist, d.h. jede Kombination irrigation density fertilizer kommt genau 4x vor (in jedem der vier Blöcke A-D einmal).
str(splityield)spc_tbl_ [72 × 6] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ ...1 : num [1:72] 1 2 3 4 5 6 7 8 9 10 ...
$ yield : num [1:72] 90 95 107 92 89 92 81 92 93 80 ...
$ block : Factor w/ 4 levels "A","B","C","D": 1 1 1 1 1 1 1 1 1 1 ...
$ irrigation: Factor w/ 2 levels "control","irrigated": 1 1 1 1 1 1 1 1 1 2 ...
$ density : Factor w/ 3 levels "low","medium",..: 1 1 1 2 2 2 3 3 3 1 ...
$ fertilizer: Factor w/ 3 levels "N","P","NP": 1 2 3 1 2 3 1 2 3 1 ...
- attr(*, "spec")=
.. cols(
.. ...1 = col_double(),
.. yield = col_double(),
.. block = col_factor(levels = NULL, ordered = FALSE, include_na = FALSE),
.. irrigation = col_factor(levels = NULL, ordered = FALSE, include_na = FALSE),
.. density = col_factor(levels = NULL, ordered = FALSE, include_na = FALSE),
.. fertilizer = col_factor(levels = NULL, ordered = FALSE, include_na = FALSE)
.. )
- attr(*, "problems")=<externalptr> summary(splityield) ...1 yield block irrigation density fertilizer
Min. : 1.00 Min. : 60.00 A:18 control :36 low :24 N :24
1st Qu.:18.75 1st Qu.: 86.00 B:18 irrigated:36 medium:24 P :24
Median :36.50 Median : 95.00 C:18 high :24 NP:24
Mean :36.50 Mean : 99.72 D:18
3rd Qu.:54.25 3rd Qu.:114.00
Max. :72.00 Max. :136.00 splityield$density <- ordered(splityield$density, levels = c("low", "medium", "high"))
splityield$density [1] low low low medium medium medium high high high low
[11] low low medium medium medium high high high low low
[21] low medium medium medium high high high low low low
[31] medium medium medium high high high low low low medium
[41] medium medium high high high low low low medium medium
[51] medium high high high low low low medium medium medium
[61] high high high low low low medium medium medium high
[71] high high
Levels: low < medium < highMan sieht, dass die Variable yield metrisch ist, während die vier anderen Variablen schon korrekt als kategoriale Variablen (factors) kodiert sind
# Explorative Datenanalyse (auf Normalverteilung, Varianzhomogenität)
boxplot(yield~fertilizer, data = splityield)
boxplot(yield~irrigation, data = splityield)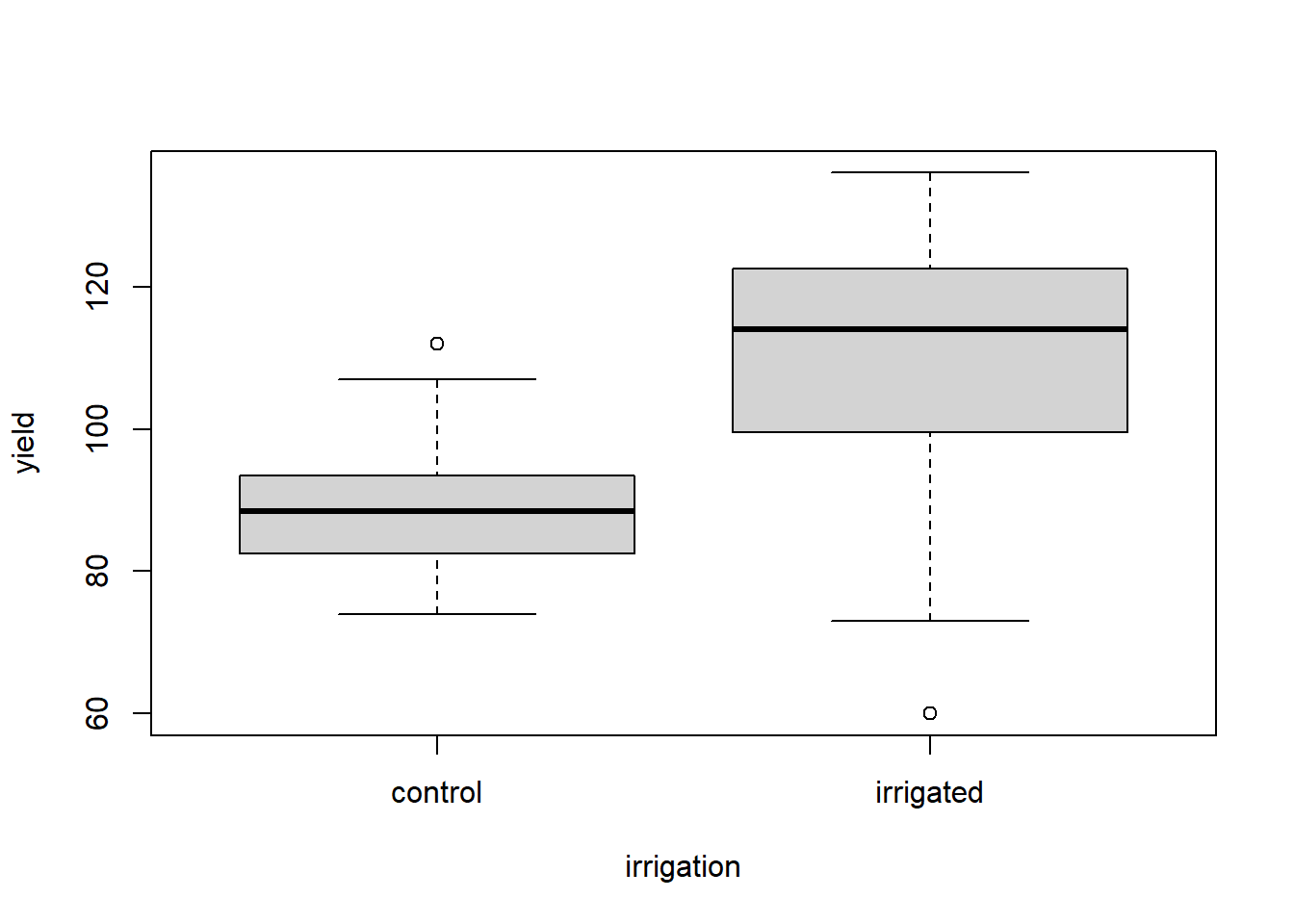
boxplot(yield~density, data = splityield)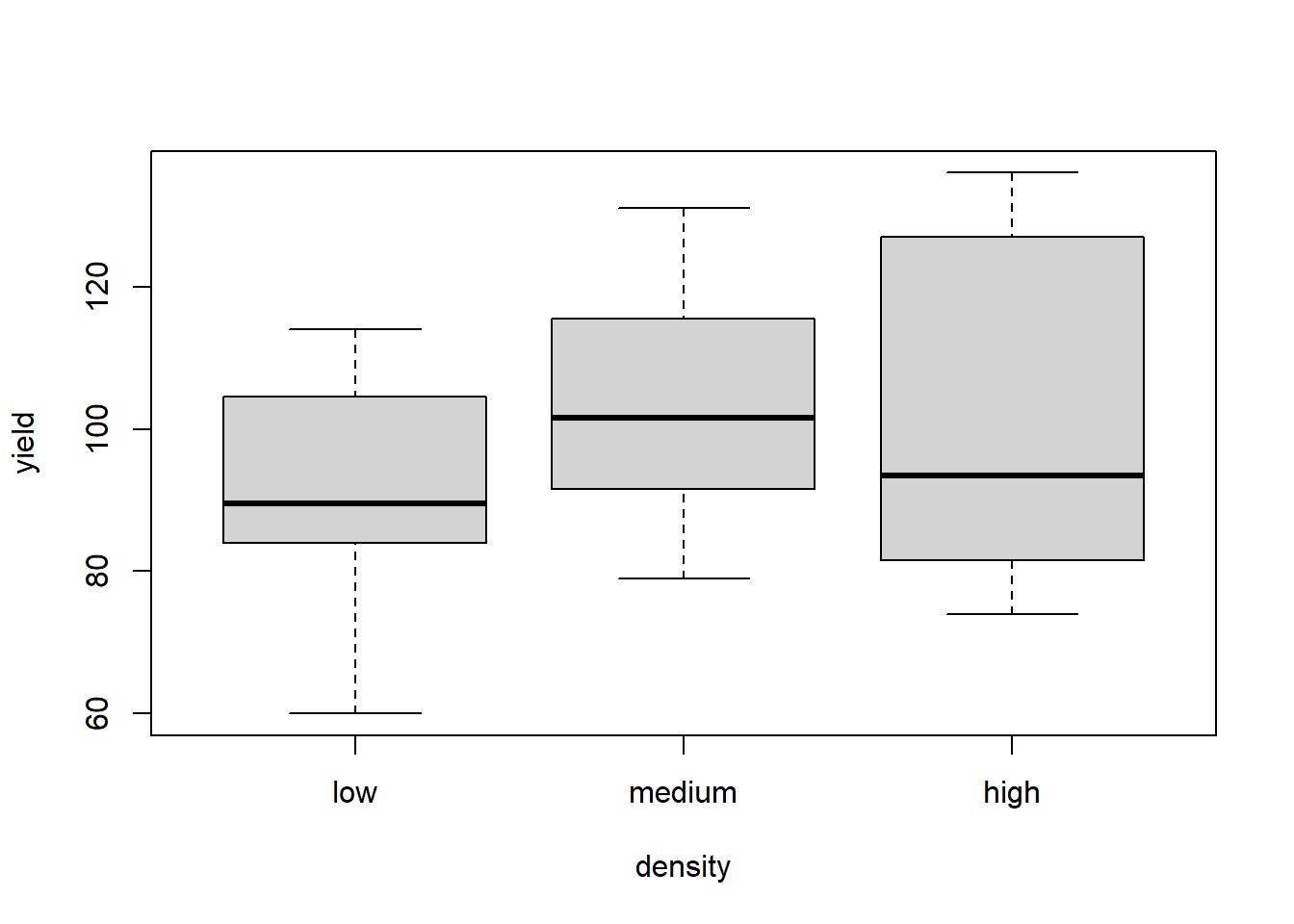
boxplot(yield~irrigation * density * fertilizer, data = splityield)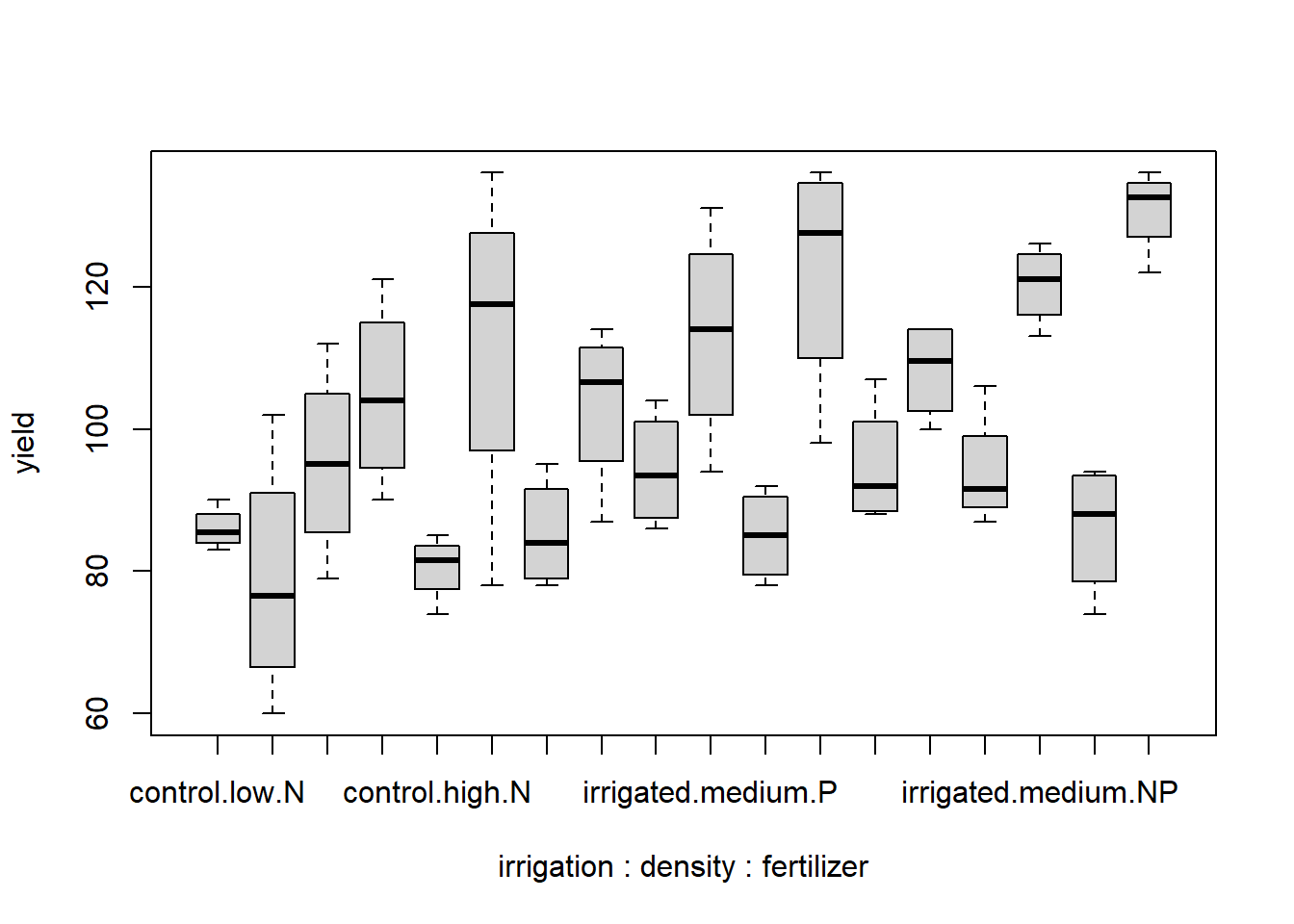
Die Boxplots sind generell hinreichend symmetrisch, so dass man davon ausgehen kann, dass keine problematische Abweichung von der Normalverteilung vorliegt. Die Varianzhomogenität sieht für den Gesamtboxplot sowie für fertilizer und density bestens aus, für irrigation und für die 3-fach-Interaktion deuten sich aber gewisse Varianzheterogenitäten an, d. h. die Boxen (Interquartil-Spannen) sind deutlich unterschiedlich lang. Da das Design aber vollkommen „balanciert“ war, wie wir von oben wissen, sind selbst relativ stark divergierende Varianzen nicht besonders problematisch. Der Boxplot der Dreifachinteraktion zeigt zudem, dass grössere Varianzen (~Boxen) mal bei kleinen, mal bei grossen Mittelwerten vorkommen, womit wir bedenkenlos weitermachen können (Wenn die grossen Varianzen immer bei grossen Mittelwerten aufgetreten wären, hätten wir eine log- oder Wurzeltransformation von yield in Betracht ziehen müssen).
boxplot(log10(yield) ~ irrigation * density * fertilizer, data = splityield) # bringt keine Verbesserung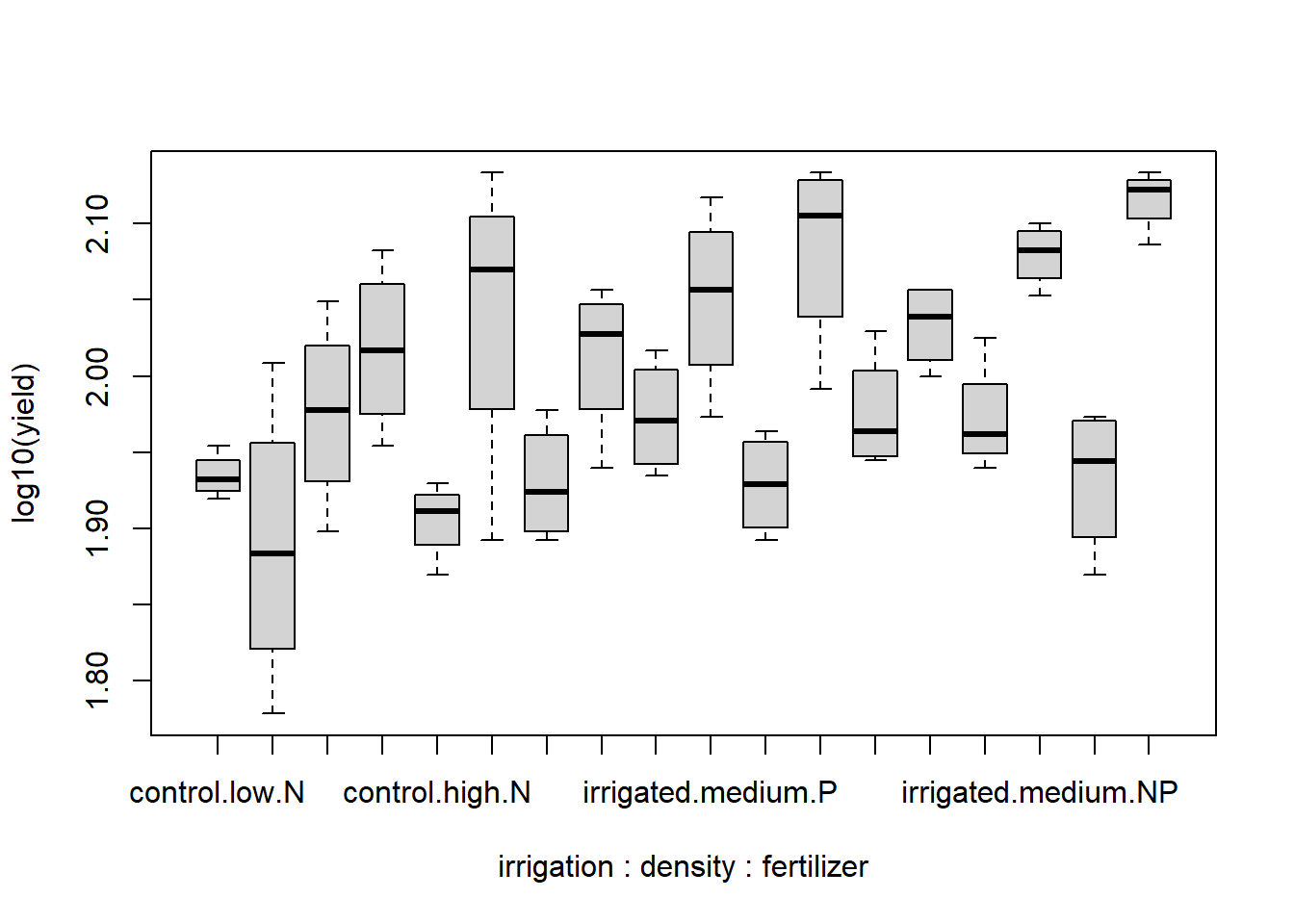
aov.1 <- aov(yield ~ irrigation * density * fertilizer + Error(block / irrigation / density), data = splityield)Das schwierigste an der Analyse ist hier die Definition des Splitt-Plot ANOVA-Modells. Hier machen wir es mit der einfachsten Möglichkeit, dem aov-Befehl. Um diesen richtig zu spezifieren, muss man verstanden haben, welches der „random“-Faktor war und wie die „fixed“ factors ineinander geschachtelt waren. In diesem Fall ist block der random Faktor, in den zunächst irrigation und dann density geschachtelt sind (die unterste Ebene fertilizer muss man nicht mehr angeben, da diese in der nächsthöheren nicht repliziert ist).
(Übrigens: das simple 3-faktorielle ANOVA-Modell aov(yield~irrigationdensityfertilizer,data=splityield) würde unterstellen, dass alle 72 subplot unabhängig von allen anderen angeordnet sind, also nicht in Blöcken. Man kann ausprobieren, wie sich das Ergebnis mit dieser Einstellung unterscheidet)
summary(aov.1)
Error: block
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 3 194.4 64.81
Error: block:irrigation
Df Sum Sq Mean Sq F value Pr(>F)
irrigation 1 8278 8278 17.59 0.0247 *
Residuals 3 1412 471
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: block:irrigation:density
Df Sum Sq Mean Sq F value Pr(>F)
density 2 1758 879.2 3.784 0.0532 .
irrigation:density 2 2747 1373.5 5.912 0.0163 *
Residuals 12 2788 232.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
fertilizer 2 1977.4 988.7 11.449 0.000142 ***
irrigation:fertilizer 2 953.4 476.7 5.520 0.008108 **
density:fertilizer 4 304.9 76.2 0.883 0.484053
irrigation:density:fertilizer 4 234.7 58.7 0.680 0.610667
Residuals 36 3108.8 86.4
---
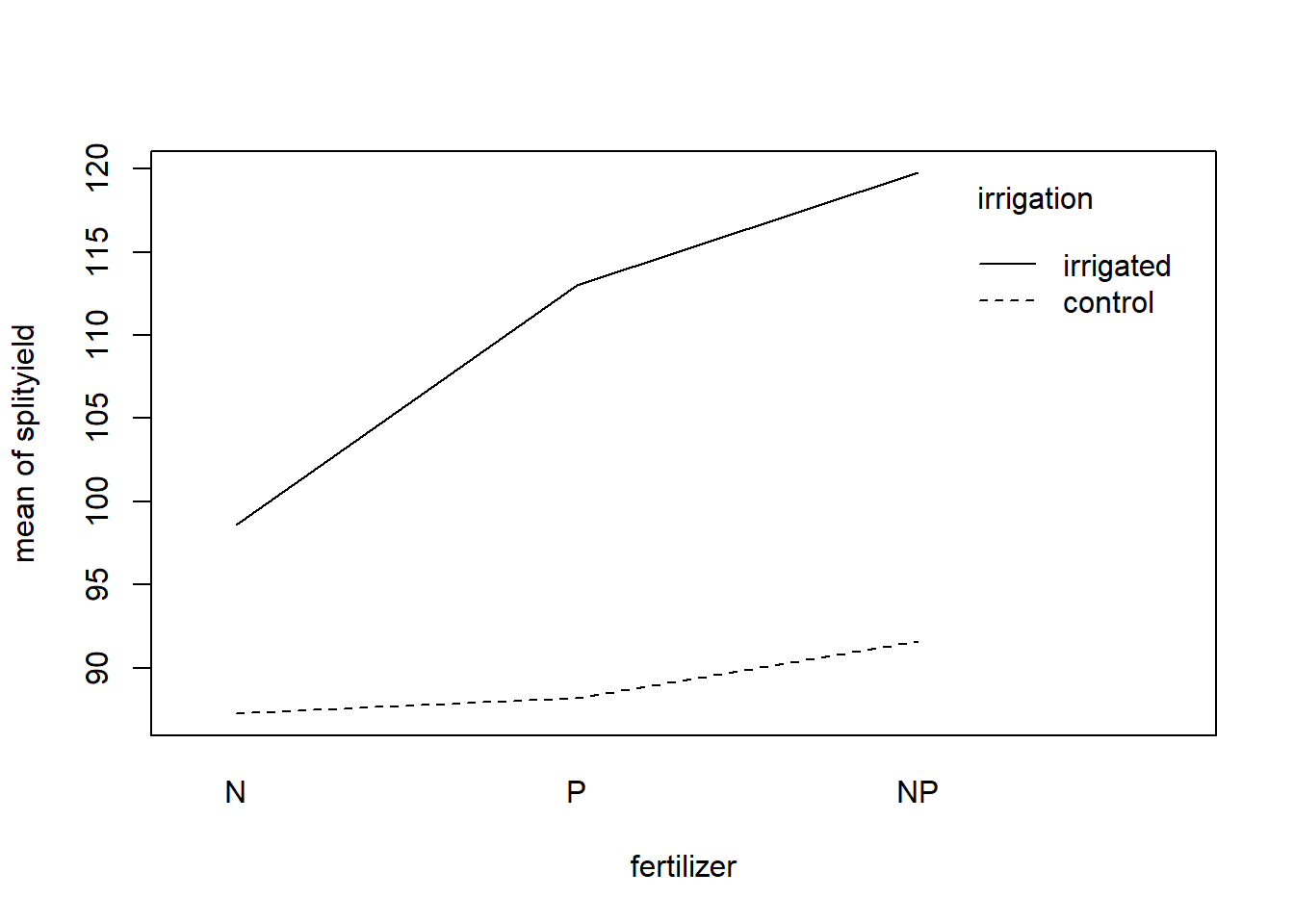
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Wir bekommen p-Werte für die drei Einzeltreatments, die drei 2-fach-Interaktionen und die 3- fach Interaktion. Keinen p-Wert gibt es dagegen für block, da dieser als „random“ Faktor spezifiziert wurde. Signifikant sind für sich genommen irrigation und fertilizer sowie die Interaktionen irrigation:density und irrigation:fertilizer.
# Modelvereinfachung
aov.2 <- aov(yield ~ irrigation + density + fertilizer + irrigation:density +
irrigation:fertilizer + density:fertilizer + Error(block / irrigation / density), data = splityield)
summary(aov.2)
Error: block
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 3 194.4 64.81
Error: block:irrigation
Df Sum Sq Mean Sq F value Pr(>F)
irrigation 1 8278 8278 17.59 0.0247 *
Residuals 3 1412 471
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: block:irrigation:density
Df Sum Sq Mean Sq F value Pr(>F)
density 2 1758 879.2 3.784 0.0532 .
irrigation:density 2 2747 1373.5 5.912 0.0163 *
Residuals 12 2788 232.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
fertilizer 2 1977 988.7 11.828 9.21e-05 ***
irrigation:fertilizer 2 953 476.7 5.703 0.00662 **
density:fertilizer 4 305 76.2 0.912 0.46639
Residuals 40 3344 83.6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1aov.3 <- aov(yield ~ irrigation + density + fertilizer + irrigation:density +
irrigation:fertilizer + Error(block / irrigation / density), data = splityield)
summary(aov.3)
Error: block
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 3 194.4 64.81
Error: block:irrigation
Df Sum Sq Mean Sq F value Pr(>F)
irrigation 1 8278 8278 17.59 0.0247 *
Residuals 3 1412 471
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: block:irrigation:density
Df Sum Sq Mean Sq F value Pr(>F)
density 2 1758 879.2 3.784 0.0532 .
irrigation:density 2 2747 1373.5 5.912 0.0163 *
Residuals 12 2788 232.3
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
fertilizer 2 1977 988.7 11.924 7.28e-05 ***
irrigation:fertilizer 2 953 476.7 5.749 0.00605 **
Residuals 44 3648 82.9
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Jetzt muss man nur noch herausfinden, wie irrigation und fertilizer wirken und wie die Interaktionen aussehen. Bei multiplen ANOVAs macht man das am besten visuell:
# Visualisierung der Ergebnisse
boxplot(yield ~ fertilizer, data = splityield)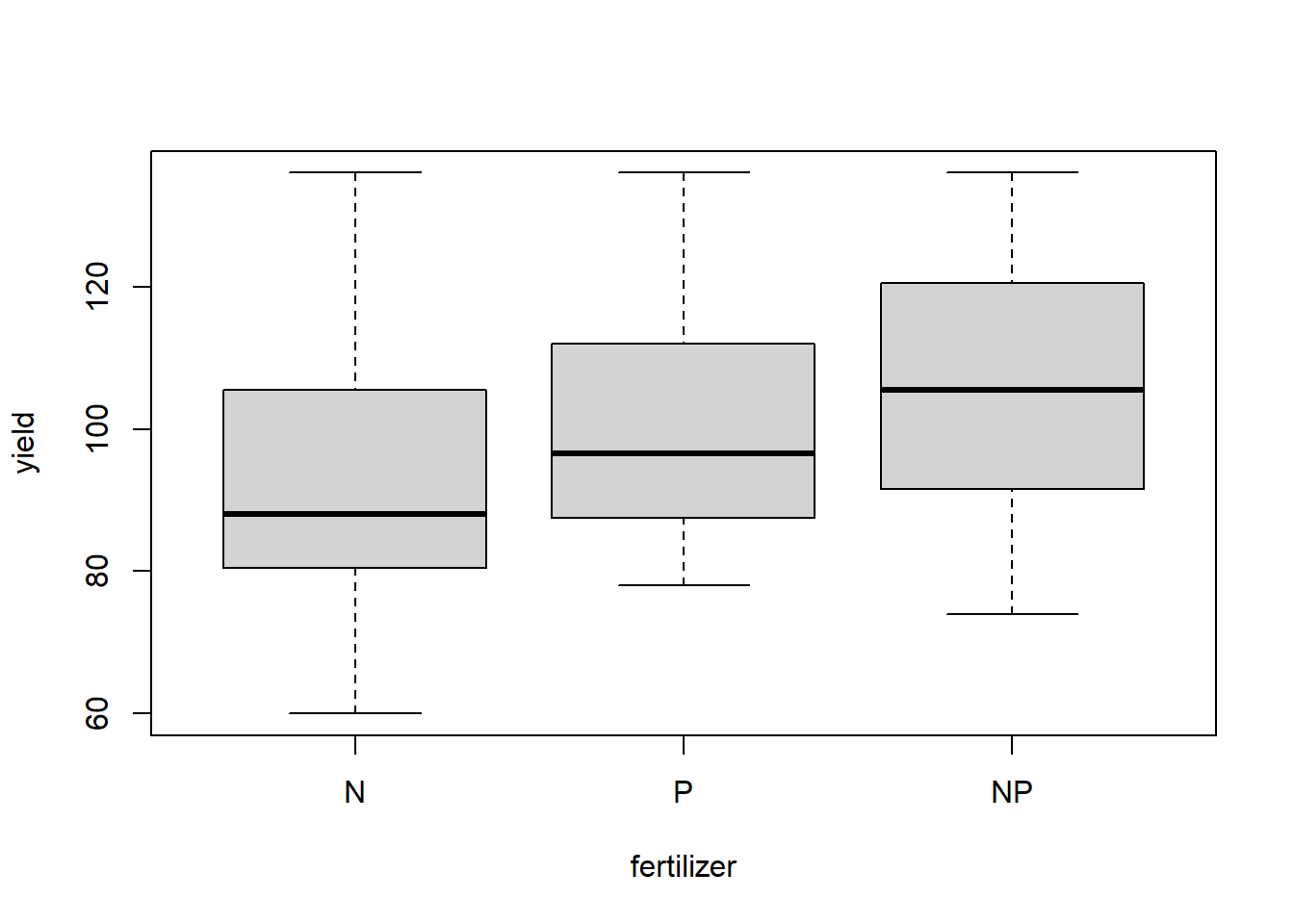
boxplot(yield ~ irrigation, data = splityield)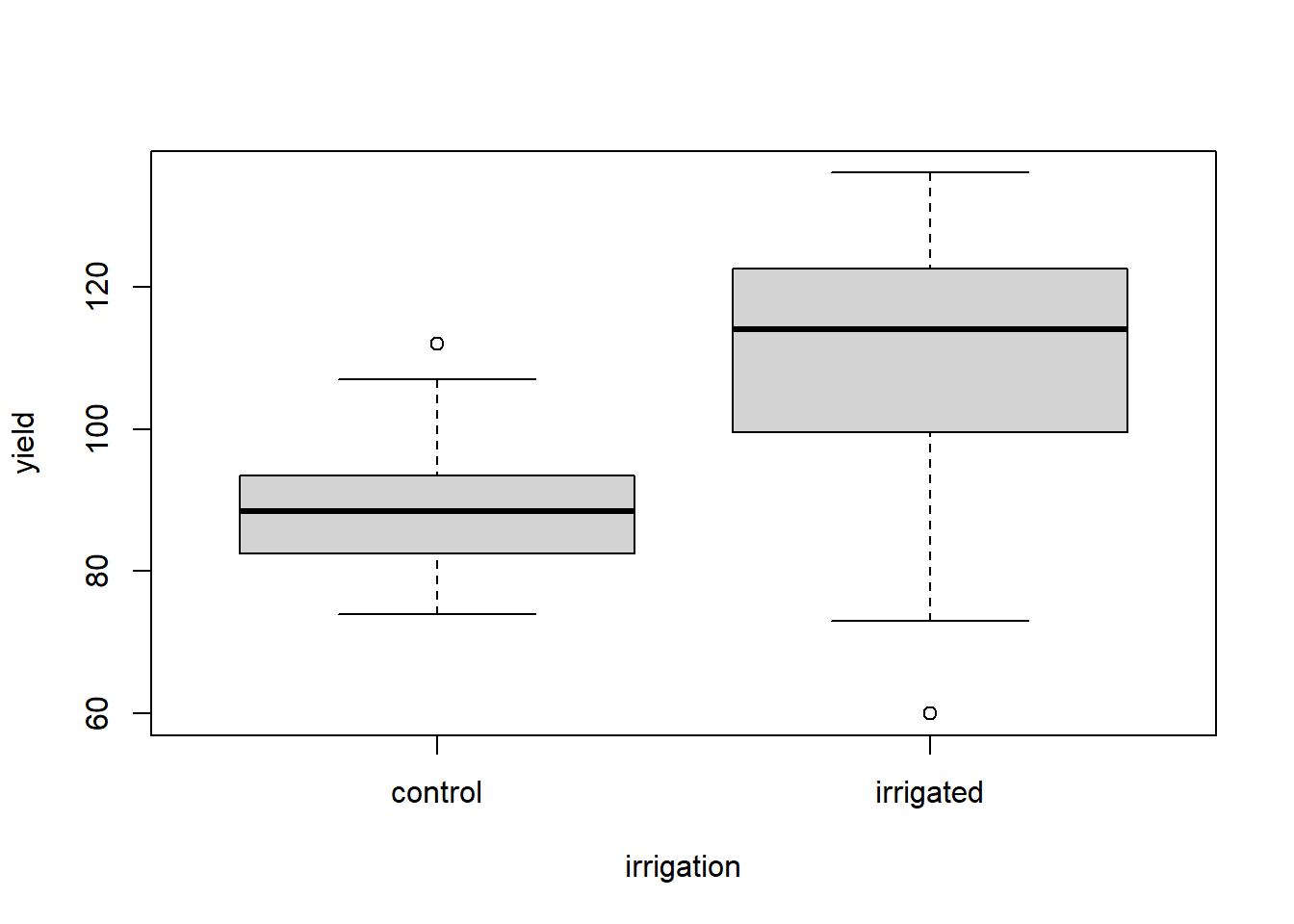
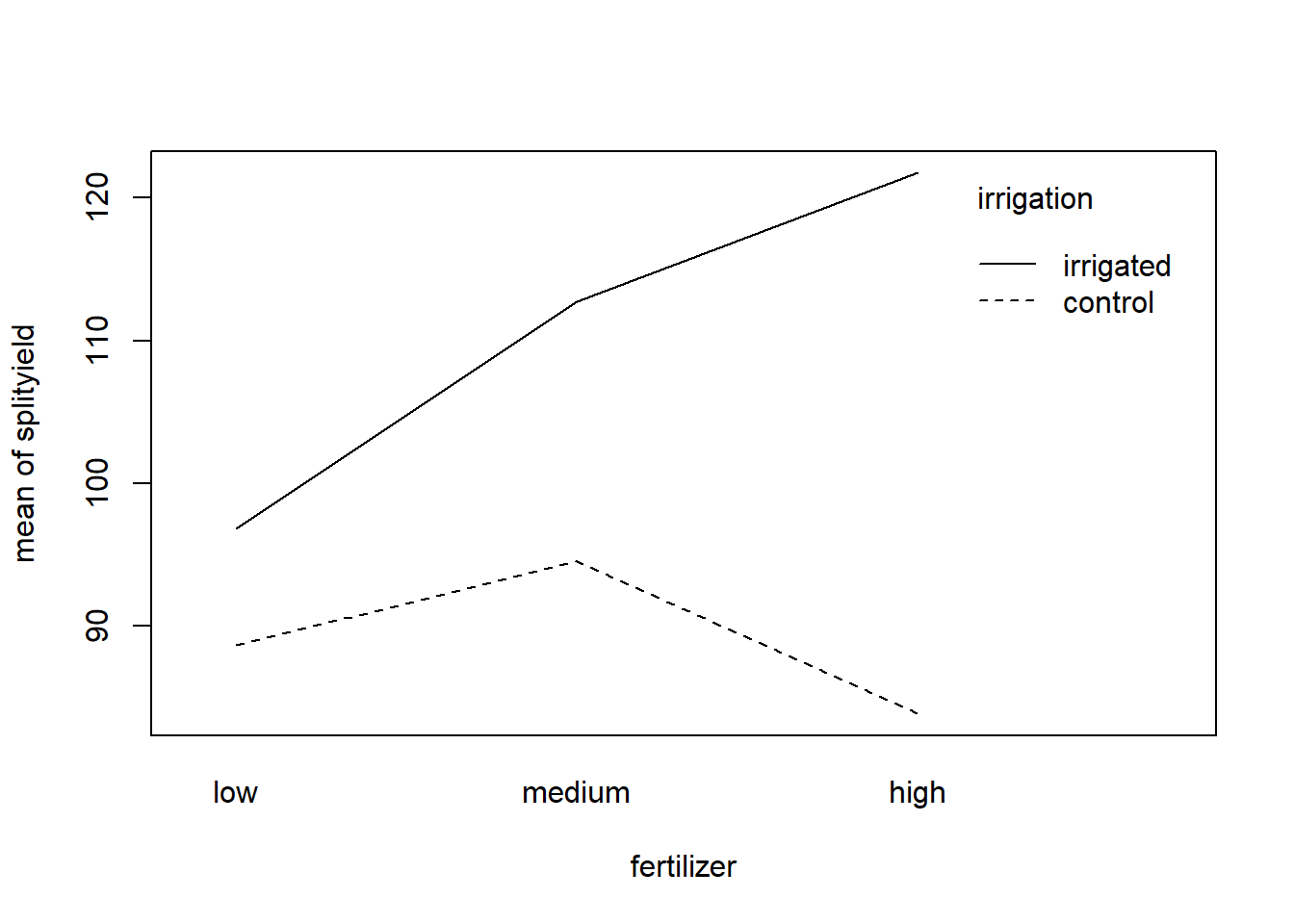
interaction.plot(splityield$fertilizer, splityield$irrigation, splityield$yield,
xlab = "fertilizer", ylab = "mean of splityield", trace.label = "irrigation"
)
interaction.plot(splityield$density, splityield$irrigation, splityield$yield,
xlab = "fertilizer", ylab = "mean of splityield", trace.label = "irrigation"
)