dfs ele slo dis
Min. : 0.30 Min. :172.0 Min. : 0.200 Min. : 0.84
1st Qu.: 54.45 1st Qu.:248.0 1st Qu.: 0.525 1st Qu.: 4.20
Median :175.20 Median :395.0 Median : 1.200 Median :22.10
Mean :188.23 Mean :481.6 Mean : 3.497 Mean :22.20
3rd Qu.:301.73 3rd Qu.:782.0 3rd Qu.: 2.875 3rd Qu.:28.57
Max. :453.00 Max. :934.0 Max. :48.000 Max. :69.00
pH har pho nit
Min. :7.700 Min. : 40.00 Min. :0.0100 Min. :0.150
1st Qu.:7.925 1st Qu.: 84.25 1st Qu.:0.1250 1st Qu.:0.505
Median :8.000 Median : 89.00 Median :0.2850 Median :1.600
Mean :8.050 Mean : 86.10 Mean :0.5577 Mean :1.654
3rd Qu.:8.100 3rd Qu.: 96.75 3rd Qu.:0.5600 3rd Qu.:2.425
Max. :8.600 Max. :110.00 Max. :4.2200 Max. :6.200
amm oxy bod
Min. :0.0000 Min. : 4.100 Min. : 1.300
1st Qu.:0.0000 1st Qu.: 8.025 1st Qu.: 2.725
Median :0.1000 Median :10.200 Median : 4.150
Mean :0.2093 Mean : 9.390 Mean : 5.117
3rd Qu.:0.2000 3rd Qu.:10.900 3rd Qu.: 5.275
Max. :1.8000 Max. :12.400 Max. :16.700
summary(spe)
Cogo Satr Phph Babl Thth
Min. :0.00 Min. :0.00 Min. :0.000 Min. :0.000 Min. :0.00
1st Qu.:0.00 1st Qu.:0.00 1st Qu.:0.000 1st Qu.:1.000 1st Qu.:0.00
Median :0.00 Median :1.00 Median :3.000 Median :2.000 Median :0.00
Mean :0.50 Mean :1.90 Mean :2.267 Mean :2.433 Mean :0.50
3rd Qu.:0.75 3rd Qu.:3.75 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:0.75
Max. :3.00 Max. :5.00 Max. :5.000 Max. :5.000 Max. :4.00
Teso Chna Pato Lele
Min. :0.0000 Min. :0.0 Min. :0.0000 Min. :0.000
1st Qu.:0.0000 1st Qu.:0.0 1st Qu.:0.0000 1st Qu.:0.000
Median :0.0000 Median :0.0 Median :0.0000 Median :1.000
Mean :0.6333 Mean :0.6 Mean :0.8667 Mean :1.433
3rd Qu.:0.7500 3rd Qu.:1.0 3rd Qu.:2.0000 3rd Qu.:2.000
Max. :5.0000 Max. :3.0 Max. :4.0000 Max. :5.000
Sqce Baba Albi Gogo Eslu
Min. :0.000 Min. :0.000 Min. :0.0 Min. :0.000 Min. :0.000
1st Qu.:1.000 1st Qu.:0.000 1st Qu.:0.0 1st Qu.:0.000 1st Qu.:0.000
Median :2.000 Median :0.000 Median :0.0 Median :1.000 Median :1.000
Mean :1.867 Mean :1.433 Mean :0.9 Mean :1.833 Mean :1.333
3rd Qu.:3.000 3rd Qu.:3.000 3rd Qu.:1.0 3rd Qu.:3.750 3rd Qu.:2.000
Max. :5.000 Max. :5.000 Max. :5.0 Max. :5.000 Max. :5.000
Pefl Rham Legi Scer Cyca
Min. :0.0 Min. :0.0 Min. :0.0000 Min. :0.0 Min. :0.0000
1st Qu.:0.0 1st Qu.:0.0 1st Qu.:0.0000 1st Qu.:0.0 1st Qu.:0.0000
Median :0.5 Median :0.0 Median :0.0000 Median :0.0 Median :0.0000
Mean :1.2 Mean :1.1 Mean :0.9667 Mean :0.7 Mean :0.8333
3rd Qu.:2.0 3rd Qu.:2.0 3rd Qu.:1.7500 3rd Qu.:1.0 3rd Qu.:1.0000
Max. :5.0 Max. :5.0 Max. :5.0000 Max. :5.0 Max. :5.0000
Titi Abbr Icme Gyce Ruru
Min. :0.0 Min. :0.0000 Min. :0.0 Min. :0.000 Min. :0.0
1st Qu.:0.0 1st Qu.:0.0000 1st Qu.:0.0 1st Qu.:0.000 1st Qu.:0.0
Median :1.0 Median :0.0000 Median :0.0 Median :0.000 Median :1.0
Mean :1.5 Mean :0.8667 Mean :0.6 Mean :1.267 Mean :2.1
3rd Qu.:3.0 3rd Qu.:1.0000 3rd Qu.:0.0 3rd Qu.:2.000 3rd Qu.:5.0
Max. :5.0 Max. :5.0000 Max. :5.0 Max. :5.000 Max. :5.0
Blbj Alal Anan
Min. :0.000 Min. :0.0 Min. :0.00
1st Qu.:0.000 1st Qu.:0.0 1st Qu.:0.00
Median :0.000 Median :0.0 Median :0.00
Mean :1.033 Mean :1.9 Mean :0.90
3rd Qu.:1.750 3rd Qu.:5.0 3rd Qu.:1.75
Max. :5.000 Max. :5.0 Max. :5.00
# Die Dataframes env und spe enthalten die Umwelt- respective die Artdatenlibrary("vegan")
Die PCA wird im Package vegan mit dem Befehl rda ausgeführt, wobei in diesem scale = TRUE gesetzt werden muss, da die Umweltdaten mit ganz unterschiedlichen Einheiten und Wertebereichen daherkommen
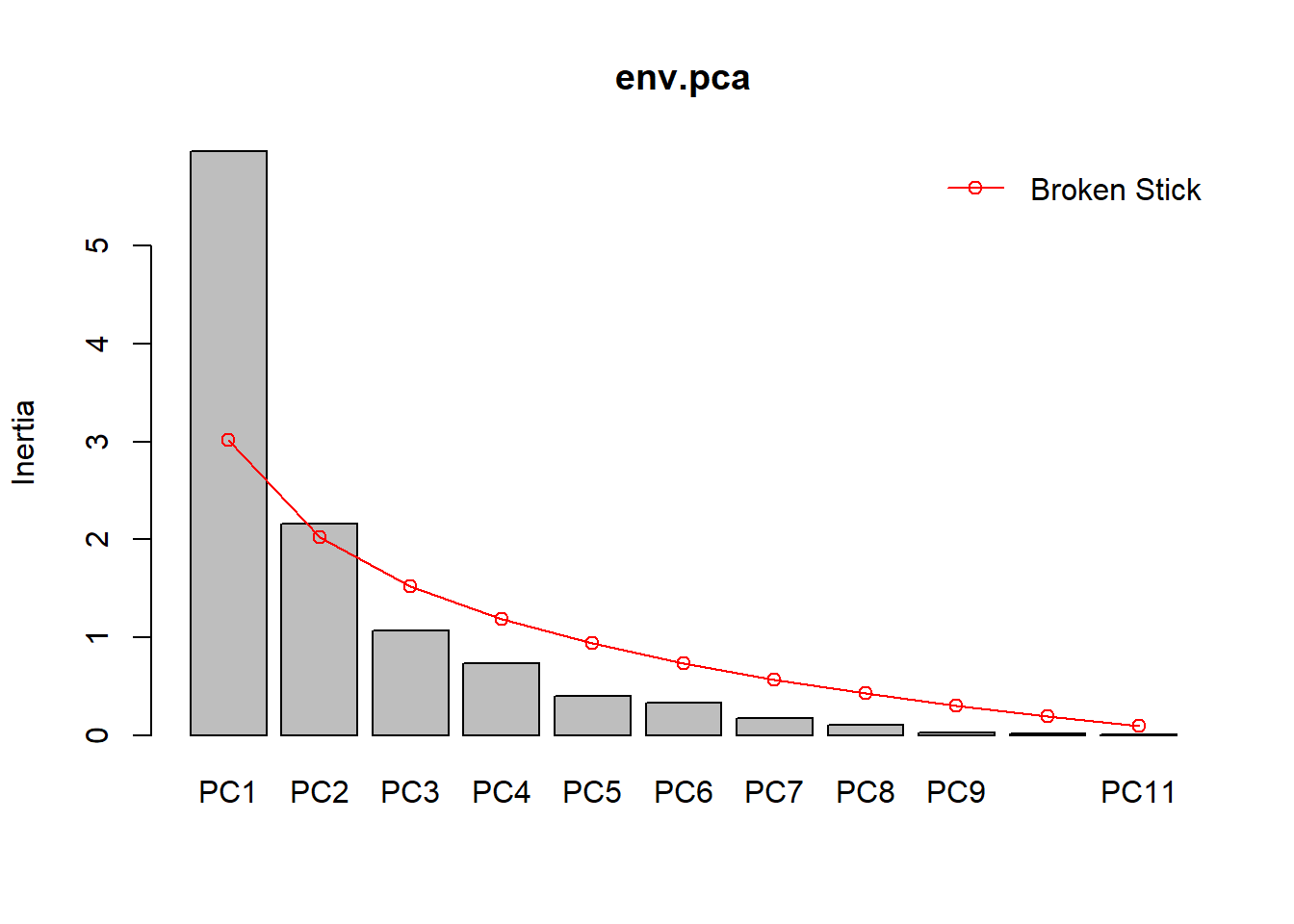
# Hier das ausführliche Summary mit den Art- und Umweltkorrelationen auf den ersten sechs Achsenscreeplot(env.pca, bstick =TRUE, npcs =length(env.pca$CA$eig))
# Visualisierung der Anteile erklärter Varianz, auch im Vergleich zu einem Broken-Stick-Modell
Die Anteile fallen steil ab. Nur die ersten vier Achsen erklären jeweils mehr als 5 % (und zusammen über 90 %)
Das Broken-stick-Modell würde sogar nur die ersten beiden Achsen als relevant vorschlagen
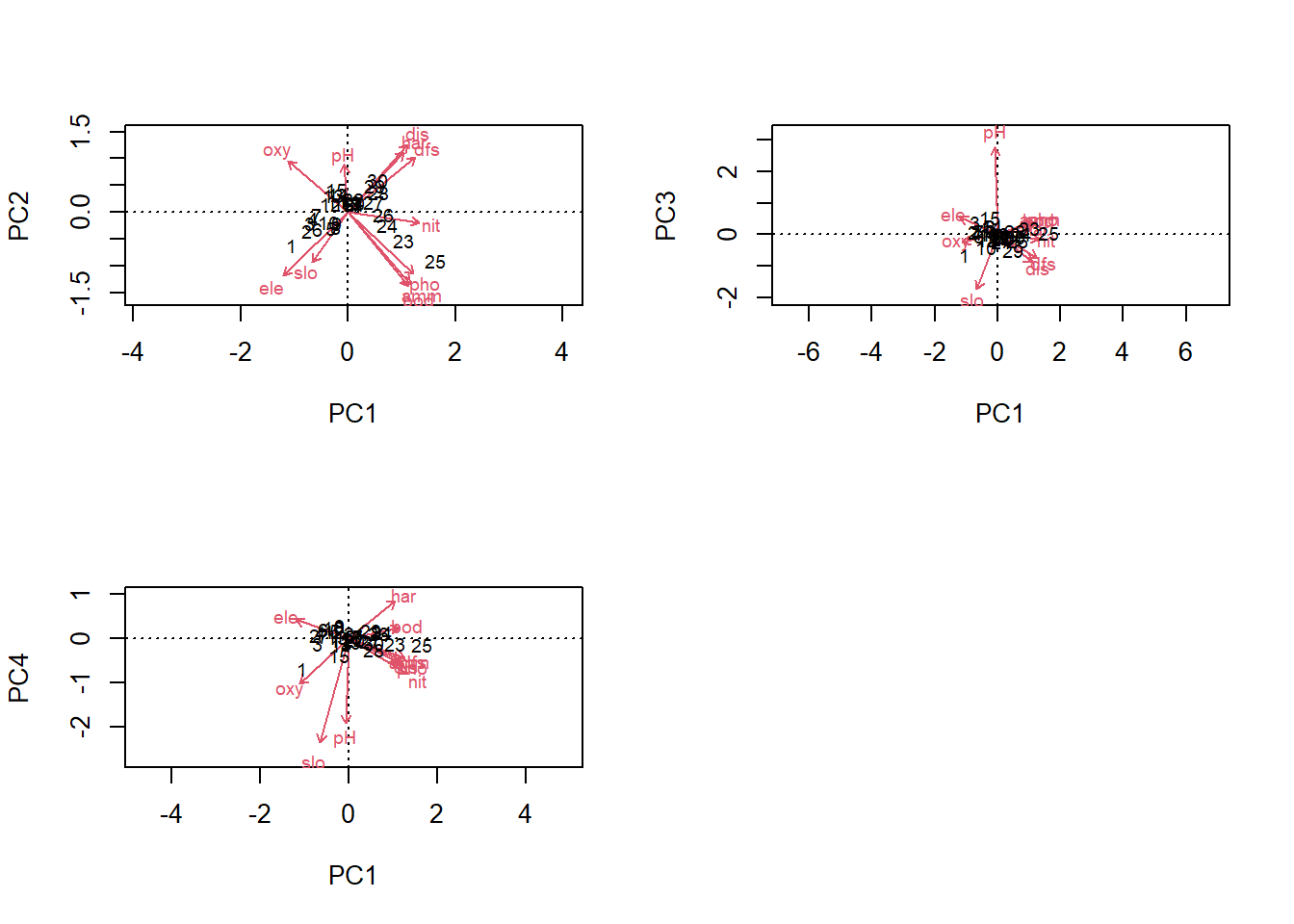
Da die Relevanz für das Datenmuster in den Umweltdaten nicht notwendig die Relevanz für die Erklärung der Artenzahlen ist, nehmen wir ins globale Modell grosszügig die ersten vier Achsen rein (PC1-PC4) Die Bedeutung der Achsen (benötigt man später für die Interpretation!) findet man in den “species scores” (da so, wie wir die PCA hier gerechnet haben, die Umweltdaten die Arten sind. Zusätzlich oder alternative kann man sich die ersten vier Achsen auch visualisieren, indem man PC2 vs. PC1 (ohne choices), PC3 vs. PC1 oder PC4 vs. PC1 plottet.
# Berechnung der Artenzahl mittels specnumber; Artenzahl und Scores werden zum Dataframe für die Regressionsanalyse hinzugefügtdoubs <-data.frame(env, scores, species_richness =specnumber(spe))doubs
## Lösung mit lm (alternativ ginge Poisson-glm) und frequentist approach (alternativ ginge Multimodelinference mit AICc)lm.pc.0<-lm(species_richness ~ PC1 + PC2 + PC3 + PC4, data = doubs)summary(lm.pc.0)
Call:
lm(formula = species_richness ~ PC1 + PC2 + PC3 + PC4, data = doubs)
Residuals:
Min 1Q Median 3Q Max
-9.2359 -4.3792 0.4256 4.5453 7.5058
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.5000 0.9869 12.667 2.24e-12 ***
PC1 4.4035 1.2790 3.443 0.00204 **
PC2 6.6729 1.2790 5.217 2.13e-05 ***
PC3 -2.9645 1.2790 -2.318 0.02893 *
PC4 0.1674 1.2790 0.131 0.89694
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.405 on 25 degrees of freedom
Multiple R-squared: 0.6401, Adjusted R-squared: 0.5825
F-statistic: 11.12 on 4 and 25 DF, p-value: 2.55e-05
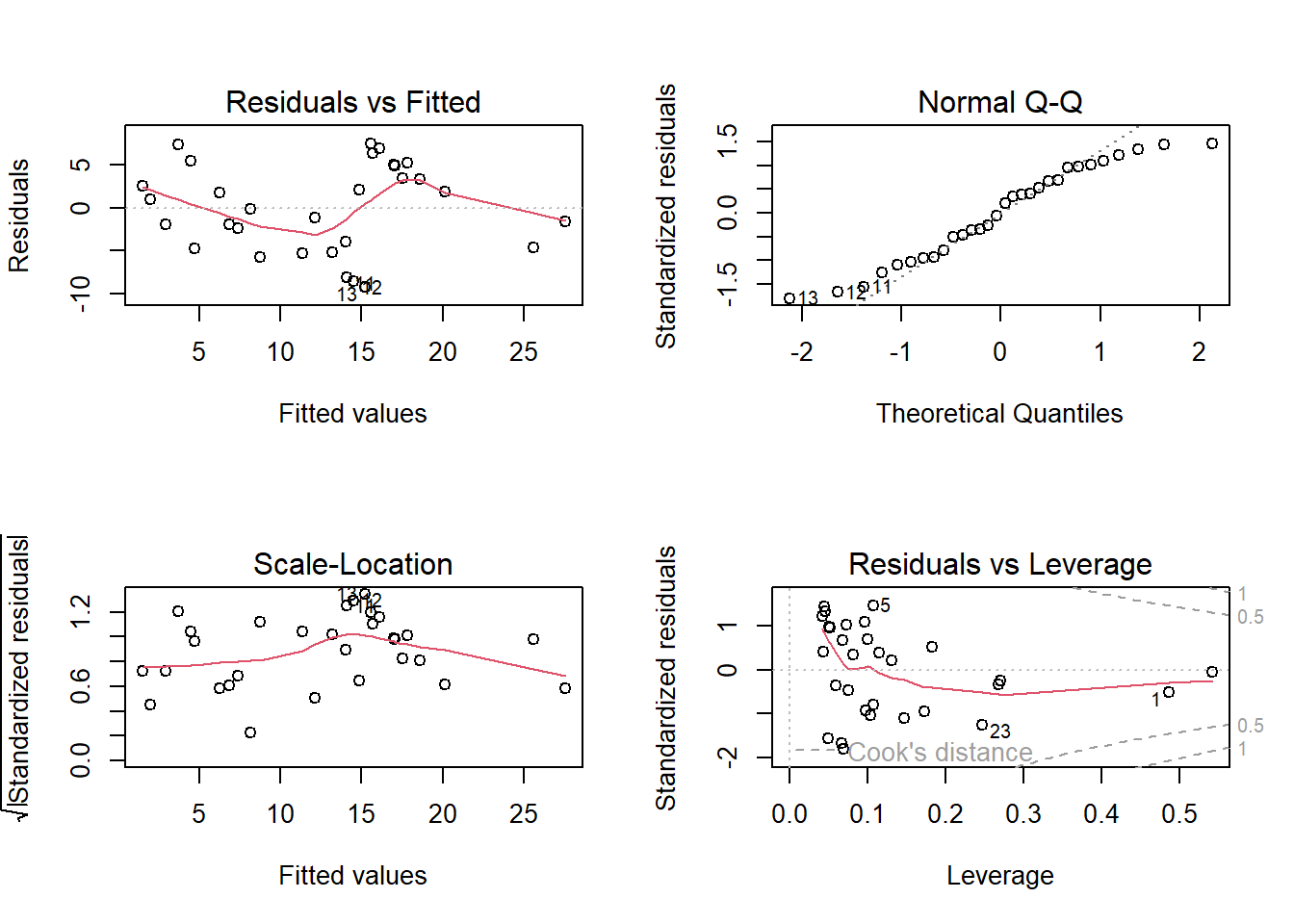
# Modellvereinfachung: PC4 ist nicht signifikant und wird entferntlm.pc.1<-lm(species_richness ~ PC1 + PC2 + PC3, data = doubs)summary(lm.pc.1) # jetzt sind alle Achsen signifikant und werden in das minimal adäquate Modell aufgenommen
Call:
lm(formula = species_richness ~ PC1 + PC2 + PC3, data = doubs)
Residuals:
Min 1Q Median 3Q Max
-9.226 -4.457 0.403 4.545 7.452
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.500 0.968 12.913 8.11e-13 ***
PC1 4.404 1.255 3.510 0.00165 **
PC2 6.673 1.255 5.319 1.45e-05 ***
PC3 -2.965 1.255 -2.363 0.02589 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.302 on 26 degrees of freedom
Multiple R-squared: 0.6399, Adjusted R-squared: 0.5983
F-statistic: 15.4 on 3 and 26 DF, p-value: 5.853e-06
Nicht besonders toll, ginge aber gerade noch. Da wir aber ohnehin Zähldaten haben, können wir es mit einem Poisson-GLM versuchen
Alternativ mit glm
glm.pc.1<-glm(species_richness ~ PC1 + PC2 + PC3 + PC4, family ="poisson", data = doubs)summary(glm.pc.1)
Call:
glm(formula = species_richness ~ PC1 + PC2 + PC3 + PC4, family = "poisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.6063 -1.4535 -0.1915 1.3852 2.2701
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.38447 0.05889 40.491 < 2e-16 ***
PC1 0.39601 0.08240 4.806 1.54e-06 ***
PC2 0.54840 0.07550 7.263 3.78e-13 ***
PC3 -0.15174 0.08345 -1.818 0.069 .
PC4 0.06053 0.09661 0.627 0.531
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 76.312 on 25 degrees of freedom
AIC: 206.97
Number of Fisher Scoring iterations: 5
glm.pc.2<-glm(species_richness ~ PC1 + PC2 + PC3, family ="poisson", data = doubs)summary(glm.pc.2)
Call:
glm(formula = species_richness ~ PC1 + PC2 + PC3, family = "poisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.4821 -1.3539 -0.2734 1.4039 2.2096
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.38670 0.05858 40.742 < 2e-16 ***
PC1 0.38609 0.07941 4.862 1.16e-06 ***
PC2 0.53665 0.07161 7.494 6.70e-14 ***
PC3 -0.17669 0.07106 -2.486 0.0129 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 76.722 on 26 degrees of freedom
AIC: 205.38
Number of Fisher Scoring iterations: 5
par(mfrow =c(2, 2))plot(glm.pc.2) # sieht nicht besser aus als LM, die Normalverteilung ist sogar schlechter
LM oder GLM sind für die Analyse möglich, Modellwahl nach Gusto. Man muss jetzt noch die Ergebnisse adäquat aus all den erzielten Outputs zusammenstellen (siehe Ergebnistext). In dieser Aufgabe haben wir ja die PC-Achsen als Alternative zur direkten Modellierung mit den originalen Umweltvariablen ausprobiert. Deshalb (war nicht Teil der Aufgabe), kommt hier noch eine Lösung, wie wir es bisher gemacht hätten.
Zum Vergleich die Modellierung mit den Originaldaten
# Korrelationen zwischen Prädiktorencor <-cor(doubs[, 1:11])cor[abs(cor) < .7] <-0cor
Die Korrelationsmatrix betrachtet man am besten in Excel. Es zeigt sich, dass es zwei grosse Gruppen von untereinander hochkorrelierten Variablen gibt: zum einen dfs-ele-dis-har-nit, zum anderen pho-nit-amm-oxy-bod, während slo und pH mit jeweils keiner anderen Variablen hochkorreliert sind. Insofern behalten wir eine aus der ersten Gruppe (ele), eine aus der zweiten Gruppe (pho) und die beiden «unabhängigen».
# Globalmodell (als hinreichend unabhängige Variablen werden ele, slo, pH und pho aufgenommen)lm.orig.1<-lm(species_richness ~ ele + slo + pH + pho, data = doubs)summary(lm.orig.1)
Call:
lm(formula = species_richness ~ ele + slo + pH + pho, data = doubs)
Residuals:
Min 1Q Median 3Q Max
-9.784 -3.265 1.869 3.375 7.664
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 74.19236 47.29223 1.569 0.12926
ele -0.02645 0.00441 -5.997 2.91e-06 ***
slo -0.09597 0.12988 -0.739 0.46684
pH -5.75643 5.84799 -0.984 0.33438
pho -4.09089 1.25657 -3.256 0.00324 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.285 on 25 degrees of freedom
Multiple R-squared: 0.6559, Adjusted R-squared: 0.6009
F-statistic: 11.92 on 4 and 25 DF, p-value: 1.485e-05
# Modellvereinfachung: slo als am wenigsten signifikante Variable gestrichenlm.orig.2<-lm(species_richness ~ ele + pH + pho, data = doubs)summary(lm.orig.2)
Call:
lm(formula = species_richness ~ ele + pH + pho, data = doubs)
Residuals:
Min 1Q Median 3Q Max
-9.446 -3.323 1.485 3.562 8.209
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 66.416530 45.702262 1.453 0.15812
ele -0.027744 0.004011 -6.917 2.41e-07 ***
pH -4.756146 5.639266 -0.843 0.40670
pho -4.068860 1.245202 -3.268 0.00305 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.239 on 26 degrees of freedom
Multiple R-squared: 0.6484, Adjusted R-squared: 0.6079
F-statistic: 15.98 on 3 and 26 DF, p-value: 4.305e-06
# Modellvereinfachung: pH ist immer noch nicht signifikant und wird gestrichenlm.orig.3<-lm(species_richness ~ ele + pho, data = doubs)summary(lm.orig.3)
Call:
lm(formula = species_richness ~ ele + pho, data = doubs)
Residuals:
Min 1Q Median 3Q Max
-9.334 -4.548 1.058 3.717 7.889
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 27.929234 2.490667 11.214 1.15e-11 ***
ele -0.027463 0.003976 -6.908 2.01e-07 ***
pho -3.951980 1.230833 -3.211 0.00341 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.211 on 27 degrees of freedom
Multiple R-squared: 0.6388, Adjusted R-squared: 0.6121
F-statistic: 23.88 on 2 and 27 DF, p-value: 1.07e-06
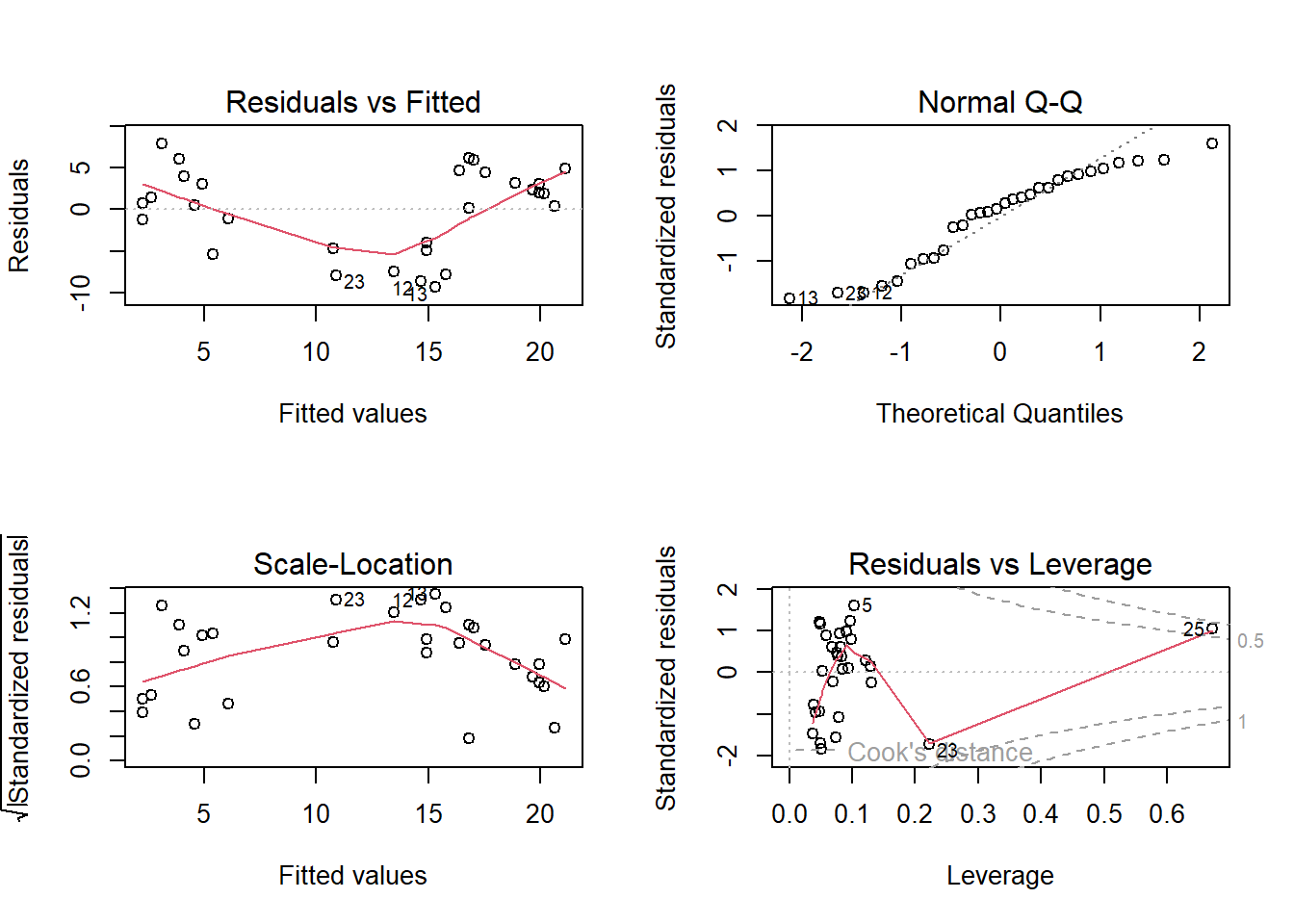
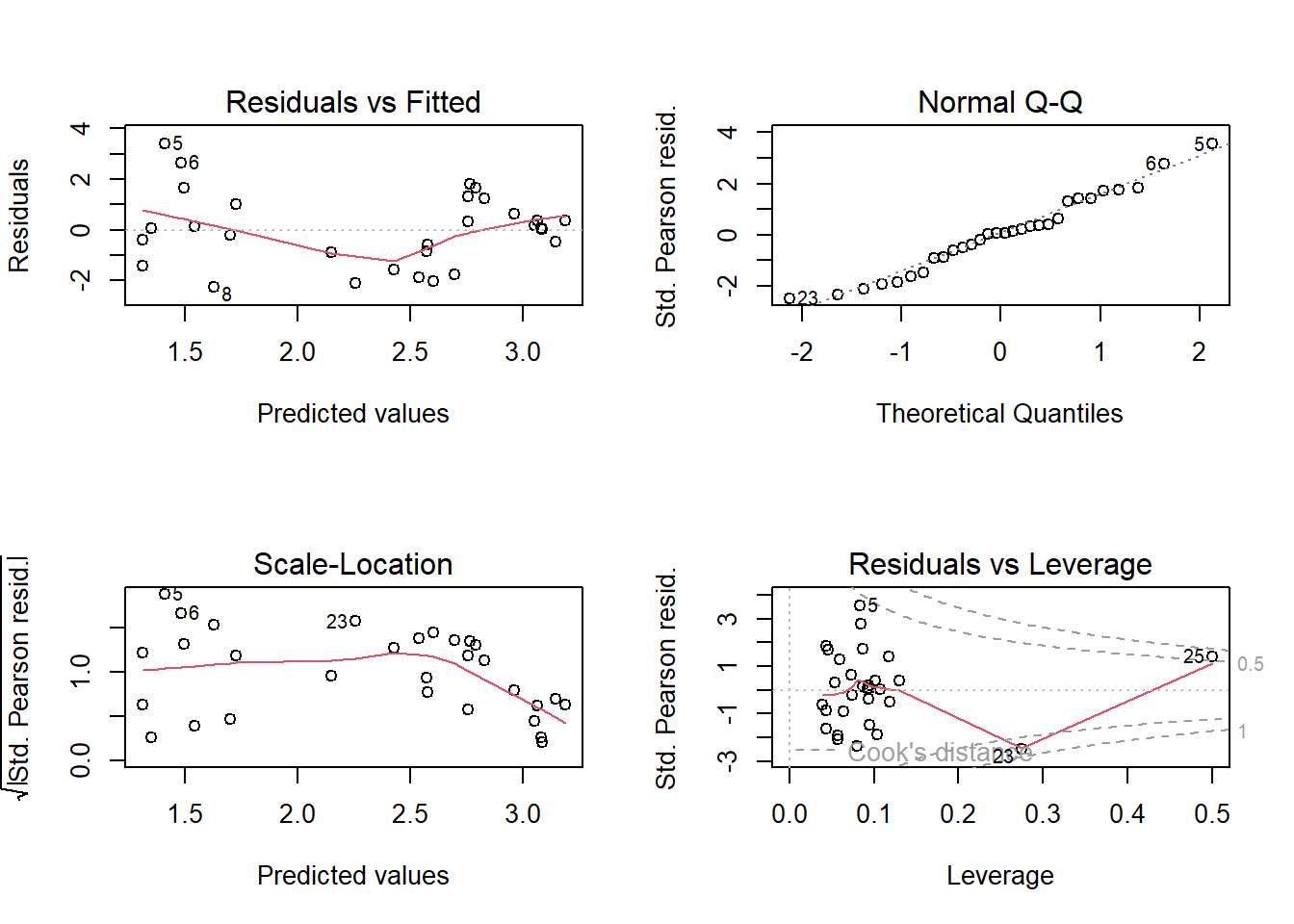
# Modelldiagnostikpar(mfrow =c(2, 2))plot(lm.orig.3) # nicht so gut, besonders die Bananenform in der linken obereren Abbildung
# Nach Modellvereinfachung bleiben zwei signifikante Variablen, ele und pho.# Da das nicht so gut aussieht, versuchen wir es mit dem theoretisch angemesseneren Modell, einem Poisson-GLM.# Versuch mit glmglm.orig.1<-glm(species_richness ~ ele + pho + pH + slo, family ="poisson", data = doubs)summary(glm.orig.1)
Call:
glm(formula = species_richness ~ ele + pho + pH + slo, family = "poisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.3800 -0.7094 0.1622 0.8079 2.4435
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.855498 2.550786 3.080 0.00207 **
ele -0.002277 0.000321 -7.094 1.3e-12 ***
pho -0.362280 0.082384 -4.397 1.1e-05 ***
pH -0.506330 0.316934 -1.598 0.11013
slo -0.054200 0.027685 -1.958 0.05026 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 55.128 on 25 degrees of freedom
AIC: 185.79
Number of Fisher Scoring iterations: 5
glm.orig.2<-glm(species_richness ~ ele + pho + slo, family ="poisson", data = doubs)summary(glm.orig.2)
Call:
glm(formula = species_richness ~ ele + pho + slo, family = "poisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.3902 -0.8159 0.2153 0.8648 2.4389
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.7819203 0.1356022 27.890 < 2e-16 ***
ele -0.0023363 0.0003167 -7.377 1.62e-13 ***
pho -0.3563681 0.0835094 -4.267 1.98e-05 ***
slo -0.0446686 0.0246618 -1.811 0.0701 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 57.752 on 26 degrees of freedom
AIC: 186.41
Number of Fisher Scoring iterations: 5
glm.orig.3<-glm(species_richness ~ ele + pho, family ="poisson", data = doubs)summary(glm.orig.3)
Call:
glm(formula = species_richness ~ ele + pho, family = "poisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.1946 -0.9256 0.0642 0.8567 2.8093
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.8381921 0.1342437 28.591 < 2e-16 ***
ele -0.0026994 0.0002795 -9.658 < 2e-16 ***
pho -0.3525967 0.0829766 -4.249 2.14e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 63.336 on 27 degrees of freedom
AIC: 190
Number of Fisher Scoring iterations: 5
plot(glm.orig.3)
# Das sieht deutlich besser aus als beim LM. Wir müssen aber noch prüfen, ob evtl. Overdispersion vorliegt.library("AER")dispersiontest(glm.orig.3) # signifikante Überdispersion
Overdispersion test
data: glm.orig.3
z = 2.1816, p-value = 0.01457
alternative hypothesis: true dispersion is greater than 1
sample estimates:
dispersion
1.967504
# Ja, es gibt signifikante Overdispersion (obwohl der Dispersionparameter sogar unter 2 ist, also nicht extrem). Wir können nun entweder quasipoisson oder negativebinomial nehmen.glmq.orig.3<-glm(species_richness ~ ele + pho, family ="quasipoisson", data = doubs)summary(glmq.orig.3)
Call:
glm(formula = species_richness ~ ele + pho, family = "quasipoisson",
data = doubs)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.1946 -0.9256 0.0642 0.8567 2.8093
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.8381921 0.1996453 19.225 < 2e-16 ***
ele -0.0026994 0.0004157 -6.494 5.81e-07 ***
pho -0.3525967 0.1234016 -2.857 0.00813 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 2.211722)
Null deviance: 179.812 on 29 degrees of freedom
Residual deviance: 63.336 on 27 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 5
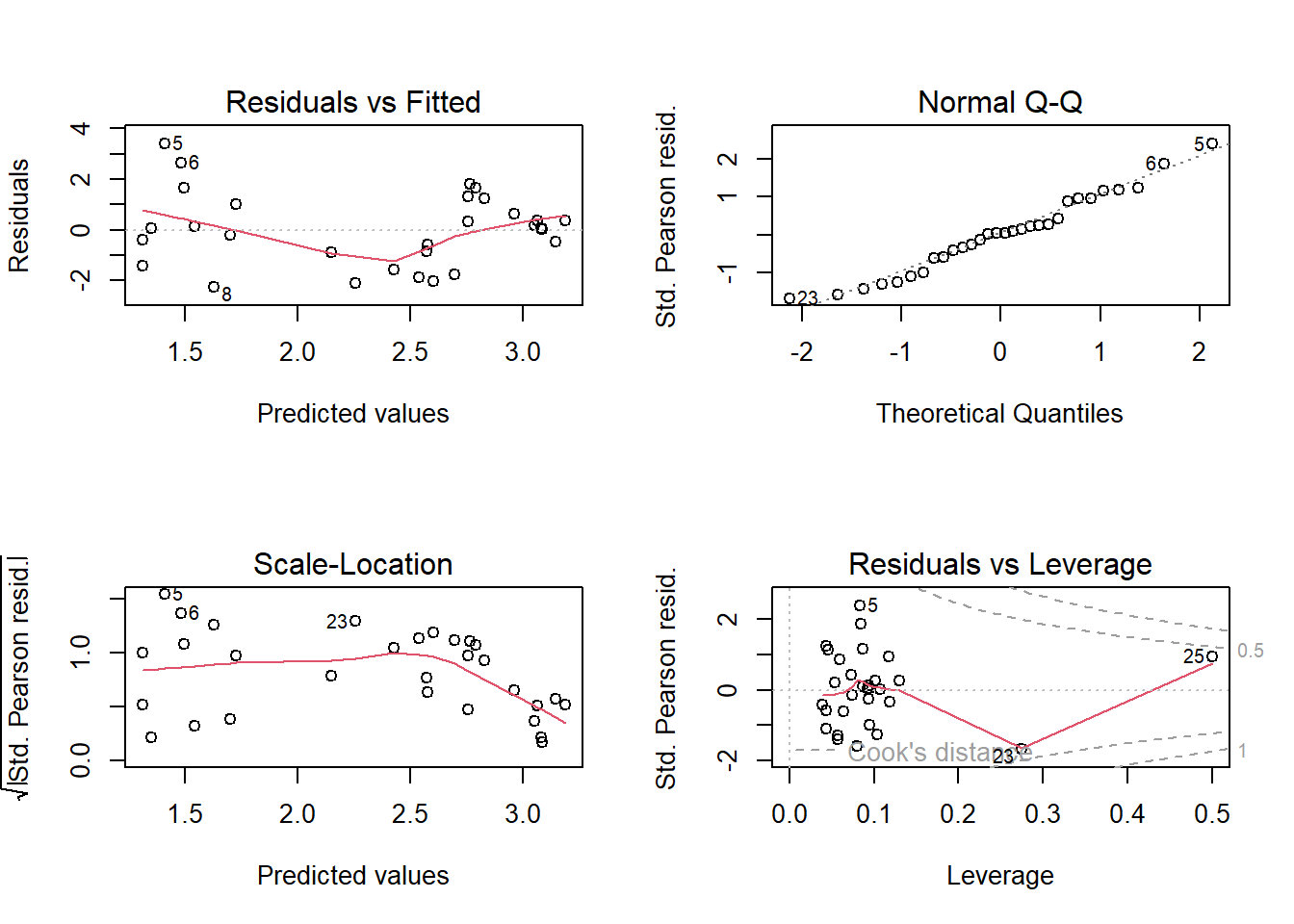
# Parameterschätzung bleiben gleich, aber Signifikanzen sind niedriger als beim GLM ohne Overdispersion.plot(glmq.orig.3)
Sieht gut aus, wir hätten hier also unser finales Modell.
Im Vergleich der beiden Vorgehensweisen (PC-Achsen vs. Umweltdaten direkt) scheint in diesem Fall die direkte Modellierung der Umweltachsen informativer: Man kommt mit zwei Prädiktoren aus, die jeweils direkt für eine der Hauptvariablen stehen – Meereshöhe und Phosphor – zugleich aber jeweils eine grössere Gruppe von Variablen mit hohen Korrelationen inkludieren, im ersten Fall Variablen, die sich im Flusslauf von oben nach unten systematisch ändern, im zweiten Masse der Nährstoffbelastung des Gewässers. Bei der PCA-Lösung kamen drei signifikante Komponenten heraus, die allerdings nicht so leicht zu interpretieren sind. Dies insbesondere, weil in diesem Fall auf der Ebene PC2 vs. PC1 die Mehrzahl der Umweltparameter ungefähr in 45-Grad-Winkeln angeordnet sind. Im allgemeinen Fall kann aber die Nutzung von PC-Achsen durchaus eine gute Lösung sein.
Quellcode
---date: 2023-11-14lesson: Stat6thema: Einführung in "multivariate" Methodenindex: 3format: html: code-tools: source: trueknitr: opts_chunk: collapse: false---# Stat6: Lösung- Download dieses Lösungsscript via "\</\>Code" (oben rechts)- [Lösungstext als Download](Statistik_Loesungstext_6.1.pdf)```{r}#| eval: trueload("datasets/stat5-8/Doubs.RData")summary(env)summary(spe)# Die Dataframes env und spe enthalten die Umwelt- respective die Artdatenlibrary("vegan")```Die PCA wird im Package vegan mit dem Befehl rda ausgeführt, wobei in diesem scale = TRUE gesetzt werden muss, da die Umweltdaten mit ganz unterschiedlichen Einheiten und Wertebereichen daherkommen```{r}env.pca <-rda(env, scale =TRUE)env.pca# In env.pca sieht man, dass es bei 11 Umweltvariablen logischerweise 11 orthogonale Principle Components gibtsummary(env.pca, axes =0)# Hier sieht man auch die Übersetzung der Eigenvalues in erklärte Varianzen der einzelnen Principle Componentssummary(env.pca)# Hier das ausführliche Summary mit den Art- und Umweltkorrelationen auf den ersten sechs Achsenscreeplot(env.pca, bstick =TRUE, npcs =length(env.pca$CA$eig))# Visualisierung der Anteile erklärter Varianz, auch im Vergleich zu einem Broken-Stick-Modell```- Die Anteile fallen steil ab. Nur die ersten vier Achsen erklären jeweils mehr als 5 % (und zusammen über 90 %)- Das Broken-stick-Modell würde sogar nur die ersten beiden Achsen als relevant vorschlagen- Da die Relevanz für das Datenmuster in den Umweltdaten nicht notwendig die Relevanz für die Erklärung der Artenzahlen ist, nehmen wir ins globale Modell grosszügig die ersten vier Achsen rein (PC1-PC4)Die Bedeutung der Achsen (benötigt man später für die Interpretation!) findet man in den “species scores” (da so, wie wir die PCA hier gerechnet haben, die Umweltdaten die Arten sind. Zusätzlich oder alternative kann man sich die ersten vier Achsen auch visualisieren, indem man PC2 vs. PC1 (ohne choices), PC3 vs. PC1 oder PC4 vs. PC1 plottet.```{r}par(mfrow =c(2, 2))biplot(env.pca, scaling =1)biplot(env.pca, choices =c(1, 3), scaling =1)biplot(env.pca, choices =c(1, 4), scaling =1)```- PC1 steht v.a. für Nitrat (positiv), Sauerstoff (negativ)- PC2 steht v.a. für pH (positiv)- PC3 steht v.a. für pH (positiv) und slo (negativ)- PC4 steht v.a. für pH (negativ) und slo (negativ)```{r}# Wir extrahieren nun die ersten vier PC-Scores aller Aufnahmeflächenscores <-scores(env.pca, c(1:4), display =c("sites"))scores# Berechnung der Artenzahl mittels specnumber; Artenzahl und Scores werden zum Dataframe für die Regressionsanalyse hinzugefügtdoubs <-data.frame(env, scores, species_richness =specnumber(spe))doubsstr(doubs)## Lösung mit lm (alternativ ginge Poisson-glm) und frequentist approach (alternativ ginge Multimodelinference mit AICc)lm.pc.0<-lm(species_richness ~ PC1 + PC2 + PC3 + PC4, data = doubs)summary(lm.pc.0)# Modellvereinfachung: PC4 ist nicht signifikant und wird entferntlm.pc.1<-lm(species_richness ~ PC1 + PC2 + PC3, data = doubs)summary(lm.pc.1) # jetzt sind alle Achsen signifikant und werden in das minimal adäquate Modell aufgenommen# Modelldiagnostik/Modellvalidierungpar(mfrow =c(2, 2))plot(lm.pc.1)```Nicht besonders toll, ginge aber gerade noch. Da wir aber ohnehin Zähldaten haben, können wir es mit einem Poisson-GLM versuchen**Alternativ mit glm**```{r}glm.pc.1<-glm(species_richness ~ PC1 + PC2 + PC3 + PC4, family ="poisson", data = doubs)summary(glm.pc.1)glm.pc.2<-glm(species_richness ~ PC1 + PC2 + PC3, family ="poisson", data = doubs)summary(glm.pc.2)par(mfrow =c(2, 2))plot(glm.pc.2) # sieht nicht besser aus als LM, die Normalverteilung ist sogar schlechter```LM oder GLM sind für die Analyse möglich, Modellwahl nach Gusto. Man muss jetzt noch die Ergebnisse adäquat aus all den erzielten Outputs zusammenstellen (siehe Ergebnistext). In dieser Aufgabe haben wir ja die PC-Achsen als Alternative zur direkten Modellierung mit den originalen Umweltvariablen ausprobiert. Deshalb (war nicht Teil der Aufgabe), kommt hier noch eine Lösung, wie wir es bisher gemacht hätten.**Zum Vergleich die Modellierung mit den Originaldaten**```{r}#| eval: false# Korrelationen zwischen Prädiktorencor <-cor(doubs[, 1:11])cor[abs(cor) < .7] <-0cor```Die Korrelationsmatrix betrachtet man am besten in Excel.Es zeigt sich, dass es zwei grosse Gruppen von untereinander hochkorrelierten Variablen gibt: zum einen dfs-ele-dis-har-nit, zum anderen pho-nit-amm-oxy-bod, während slo und pH mit jeweils keiner anderen Variablen hochkorreliert sind. Insofern behalten wir eine aus der ersten Gruppe (ele), eine aus der zweiten Gruppe (pho) und die beiden «unabhängigen».```{r}# Globalmodell (als hinreichend unabhängige Variablen werden ele, slo, pH und pho aufgenommen)lm.orig.1<-lm(species_richness ~ ele + slo + pH + pho, data = doubs)summary(lm.orig.1)# Modellvereinfachung: slo als am wenigsten signifikante Variable gestrichenlm.orig.2<-lm(species_richness ~ ele + pH + pho, data = doubs)summary(lm.orig.2)# Modellvereinfachung: pH ist immer noch nicht signifikant und wird gestrichenlm.orig.3<-lm(species_richness ~ ele + pho, data = doubs)summary(lm.orig.3)# Modelldiagnostikpar(mfrow =c(2, 2))plot(lm.orig.3) # nicht so gut, besonders die Bananenform in der linken obereren Abbildung# Nach Modellvereinfachung bleiben zwei signifikante Variablen, ele und pho.# Da das nicht so gut aussieht, versuchen wir es mit dem theoretisch angemesseneren Modell, einem Poisson-GLM.# Versuch mit glmglm.orig.1<-glm(species_richness ~ ele + pho + pH + slo, family ="poisson", data = doubs)summary(glm.orig.1)glm.orig.2<-glm(species_richness ~ ele + pho + slo, family ="poisson", data = doubs)summary(glm.orig.2)glm.orig.3<-glm(species_richness ~ ele + pho, family ="poisson", data = doubs)summary(glm.orig.3)plot(glm.orig.3)# Das sieht deutlich besser aus als beim LM. Wir müssen aber noch prüfen, ob evtl. Overdispersion vorliegt.library("AER")dispersiontest(glm.orig.3) # signifikante Überdispersion# Ja, es gibt signifikante Overdispersion (obwohl der Dispersionparameter sogar unter 2 ist, also nicht extrem). Wir können nun entweder quasipoisson oder negativebinomial nehmen.glmq.orig.3<-glm(species_richness ~ ele + pho, family ="quasipoisson", data = doubs)summary(glmq.orig.3)# Parameterschätzung bleiben gleich, aber Signifikanzen sind niedriger als beim GLM ohne Overdispersion.plot(glmq.orig.3)```Sieht gut aus, wir hätten hier also unser finales Modell.Im Vergleich der beiden Vorgehensweisen (PC-Achsen vs. Umweltdaten direkt) scheint in diesem Fall die direkte Modellierung der Umweltachsen informativer: Man kommt mit zwei Prädiktoren aus, die jeweils direkt für eine der Hauptvariablen stehen – Meereshöhe und Phosphor – zugleich aber jeweils eine grössere Gruppe von Variablen mit hohen Korrelationen inkludieren, im ersten Fall Variablen, die sich im Flusslauf von oben nach unten systematisch ändern, im zweiten Masse der Nährstoffbelastung des Gewässers. Bei der PCA-Lösung kamen drei signifikante Komponenten heraus, die allerdings nicht so leicht zu interpretieren sind. Dies insbesondere, weil in diesem Fall auf der Ebene PC2 vs. PC1 die Mehrzahl der Umweltparameter ungefähr in 45-Grad-Winkeln angeordnet sind. Im allgemeinen Fall kann aber die Nutzung von PC-Achsen durchaus eine gute Lösung sein.