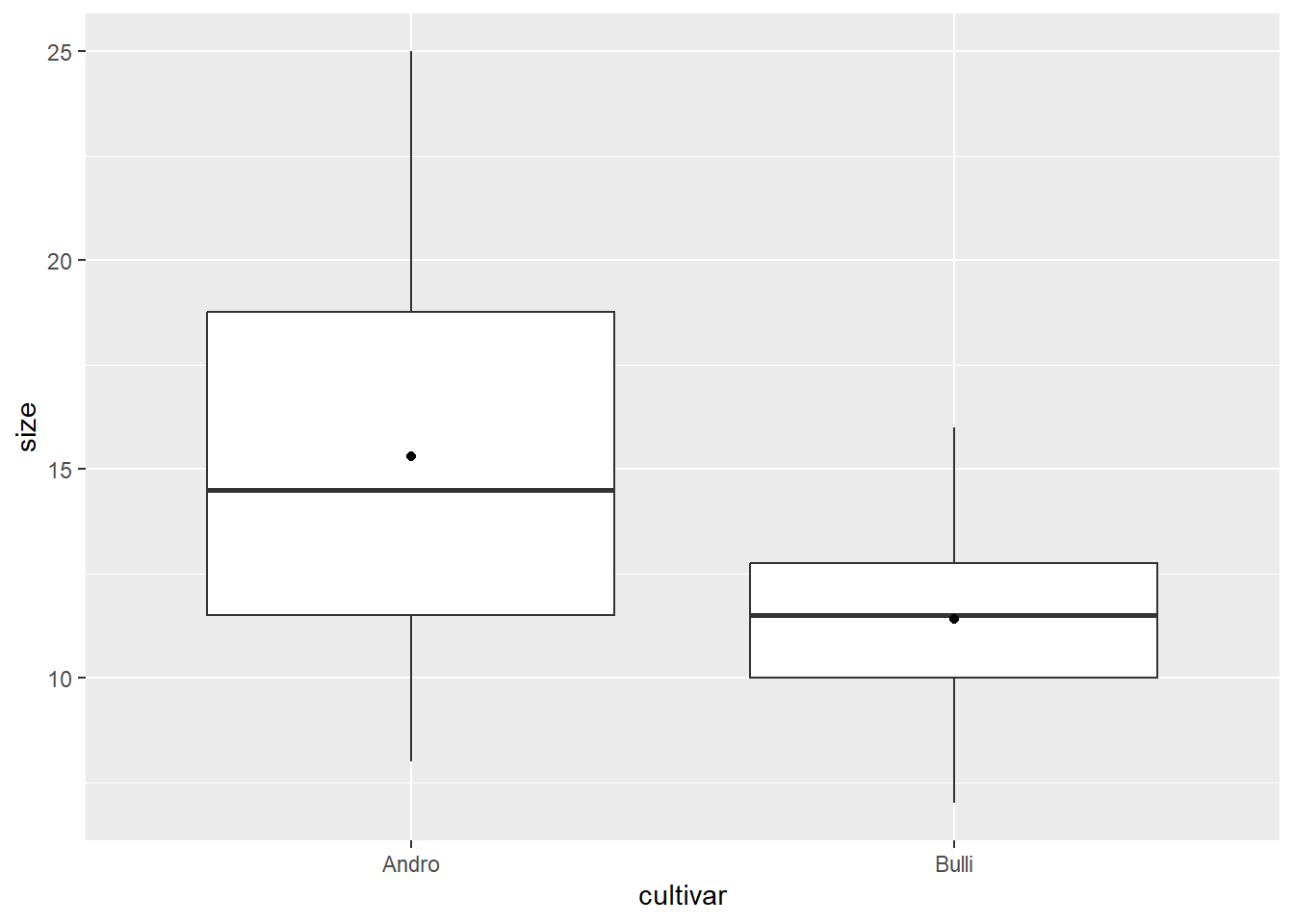
Two Sample t-test
data: size by cultivar
t = 2.0797, df = 18, p-value = 0.05212
alternative hypothesis: true difference in means between group Andro and group Bulli is not equal to 0
95 percent confidence interval:
-0.03981237 7.83981237
sample estimates:
mean in group Andro mean in group Bulli
15.3 11.4
# ANOVA ausführenaov_1 <-aov(size ~ cultivar, data = blume)aov_1
Call:
aov(formula = size ~ cultivar, data = blume)
Terms:
cultivar Residuals
Sum of Squares 76.05 316.50
Deg. of Freedom 1 18
Residual standard error: 4.193249
Estimated effects may be unbalanced
summary(aov_1)
Df Sum Sq Mean Sq F value Pr(>F)
cultivar 1 76.0 76.05 4.325 0.0521 .
Residuals 18 316.5 17.58
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary.lm(aov_1)
Call:
aov(formula = size ~ cultivar, data = blume)
Residuals:
Min 1Q Median 3Q Max
-7.300 -2.575 -0.350 2.925 9.700
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.300 1.326 11.54 9.47e-10 ***
cultivarBulli -3.900 1.875 -2.08 0.0521 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.193 on 18 degrees of freedom
Multiple R-squared: 0.1937, Adjusted R-squared: 0.1489
F-statistic: 4.325 on 1 and 18 DF, p-value: 0.05212
Study: aov_2 ~ "cultivar"
HSD Test for size
Mean Square Error: 19.57778
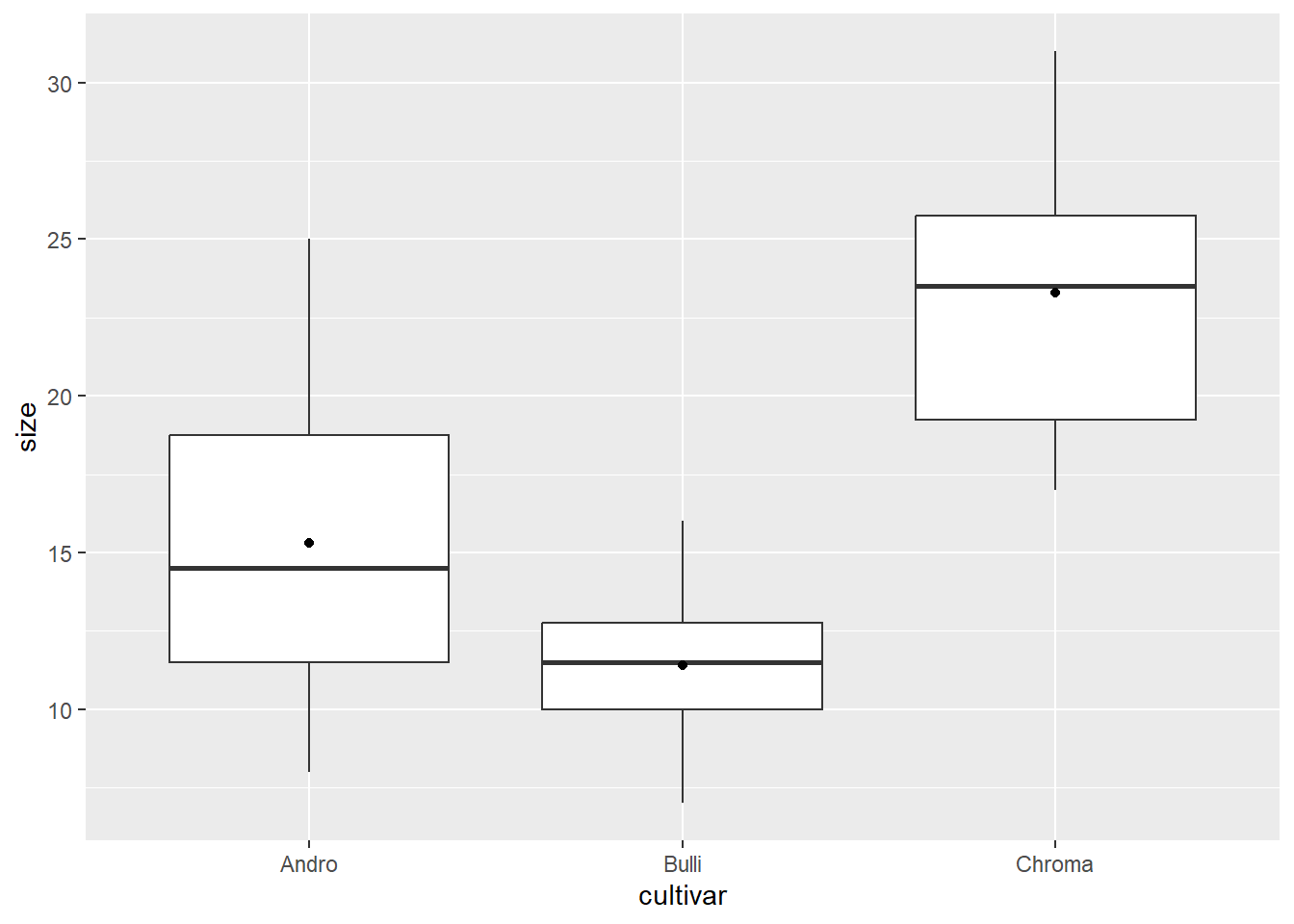
cultivar, means
size std r se Min Max Q25 Q50 Q75
Andro 15.3 5.207900 10 1.399206 8 25 11.50 14.5 18.75
Bulli 11.4 2.836273 10 1.399206 7 16 10.00 11.5 12.75
Chroma 23.3 4.854551 10 1.399206 17 31 19.25 23.5 25.75
Alpha: 0.05 ; DF Error: 27
Critical Value of Studentized Range: 3.506426
Minimun Significant Difference: 4.906213
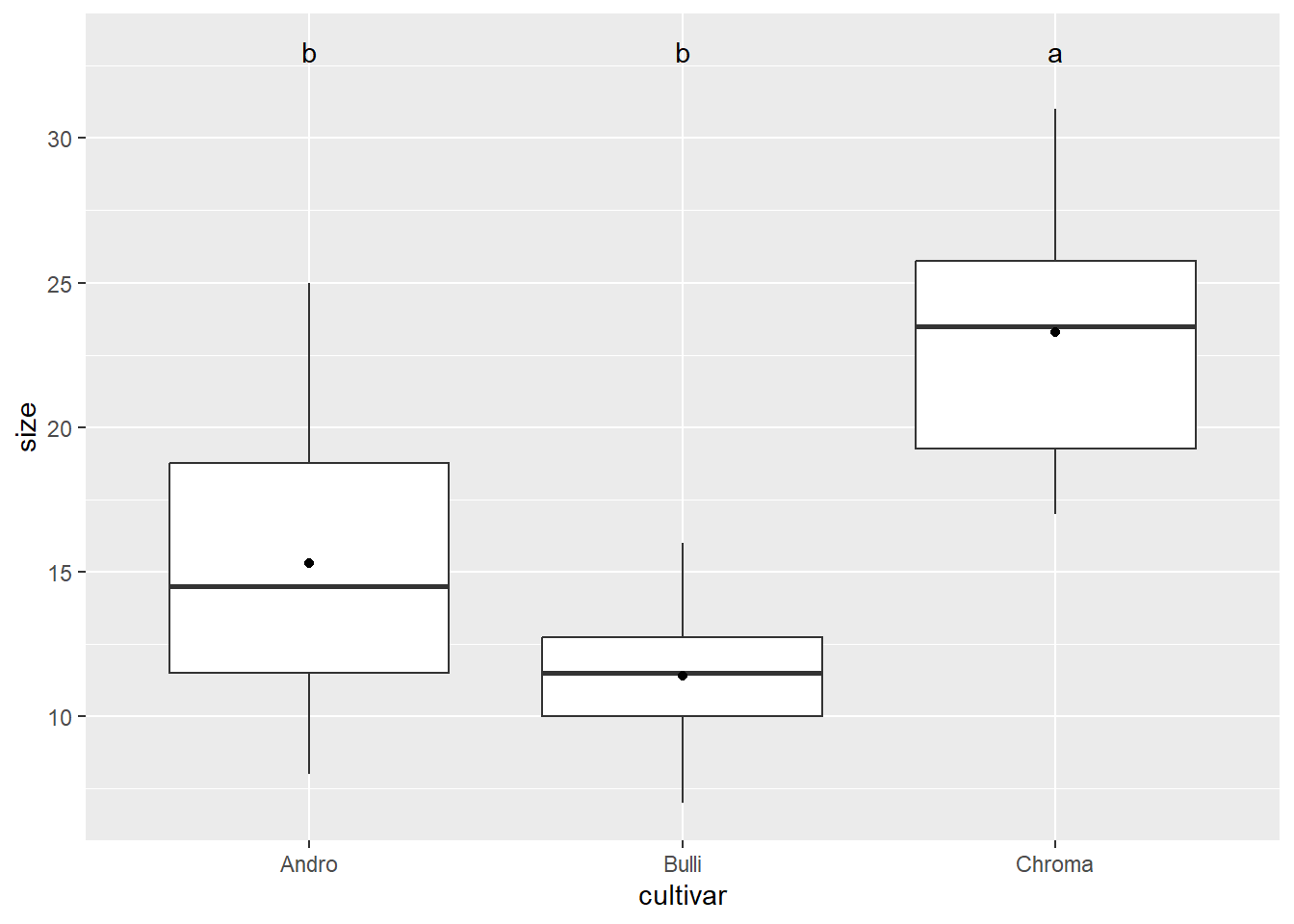
Treatments with the same letter are not significantly different.
size groups
Chroma 23.3 a
Andro 15.3 b
Bulli 11.4 b
posthoc
$statistics
MSerror Df Mean CV MSD
19.57778 27 16.66667 26.54807 4.906213
$parameters
test name.t ntr StudentizedRange alpha
Tukey cultivar 3 3.506426 0.05
$means
size std r se Min Max Q25 Q50 Q75
Andro 15.3 5.207900 10 1.399206 8 25 11.50 14.5 18.75
Bulli 11.4 2.836273 10 1.399206 7 16 10.00 11.5 12.75
Chroma 23.3 4.854551 10 1.399206 17 31 19.25 23.5 25.75
$comparison
NULL
$groups
size groups
Chroma 23.3 a
Andro 15.3 b
Bulli 11.4 b
attr(,"class")
[1] "group"
# Darstellung der Ergebnisse mit Post-Hoc-Labels über Boxplots# Labels des Posthoc-Tests extrahierenlabels <- posthoc$groupslabels$cultivar <-rownames(labels)# In Plot darstellenggplot(blume2, aes(cultivar, size)) +geom_boxplot() +geom_text(data = labels, aes(x = cultivar, y =33, label = groups)) +stat_summary(fun = mean, geom ="point")
cultivar house size
1 Andro yes 20
2 Andro yes 19
3 Andro yes 25
4 Andro yes 10
5 Andro yes 8
6 Andro yes 15
7 Andro yes 13
8 Andro yes 18
9 Andro yes 11
10 Andro yes 14
11 Andro no 12
12 Andro no 15
13 Andro no 16
14 Andro no 7
15 Andro no 8
16 Andro no 10
17 Andro no 12
18 Andro no 11
19 Andro no 13
20 Andro no 10
21 Bulli yes 30
22 Bulli yes 19
23 Bulli yes 31
24 Bulli yes 23
25 Bulli yes 18
26 Bulli yes 25
27 Bulli yes 26
28 Bulli yes 24
29 Bulli yes 17
30 Bulli yes 20
31 Bulli no 10
32 Bulli no 12
33 Bulli no 11
34 Bulli no 13
35 Bulli no 10
36 Bulli no 25
37 Bulli no 12
38 Bulli no 30
39 Bulli no 26
40 Bulli no 13
41 Chroma yes 15
42 Chroma yes 13
43 Chroma yes 18
44 Chroma yes 11
45 Chroma yes 14
46 Chroma yes 25
47 Chroma yes 39
48 Chroma yes 38
49 Chroma yes 28
50 Chroma yes 24
51 Chroma no 10
52 Chroma no 12
53 Chroma no 11
54 Chroma no 13
55 Chroma no 10
56 Chroma no 9
57 Chroma no 2
58 Chroma no 4
59 Chroma no 7
60 Chroma no 13
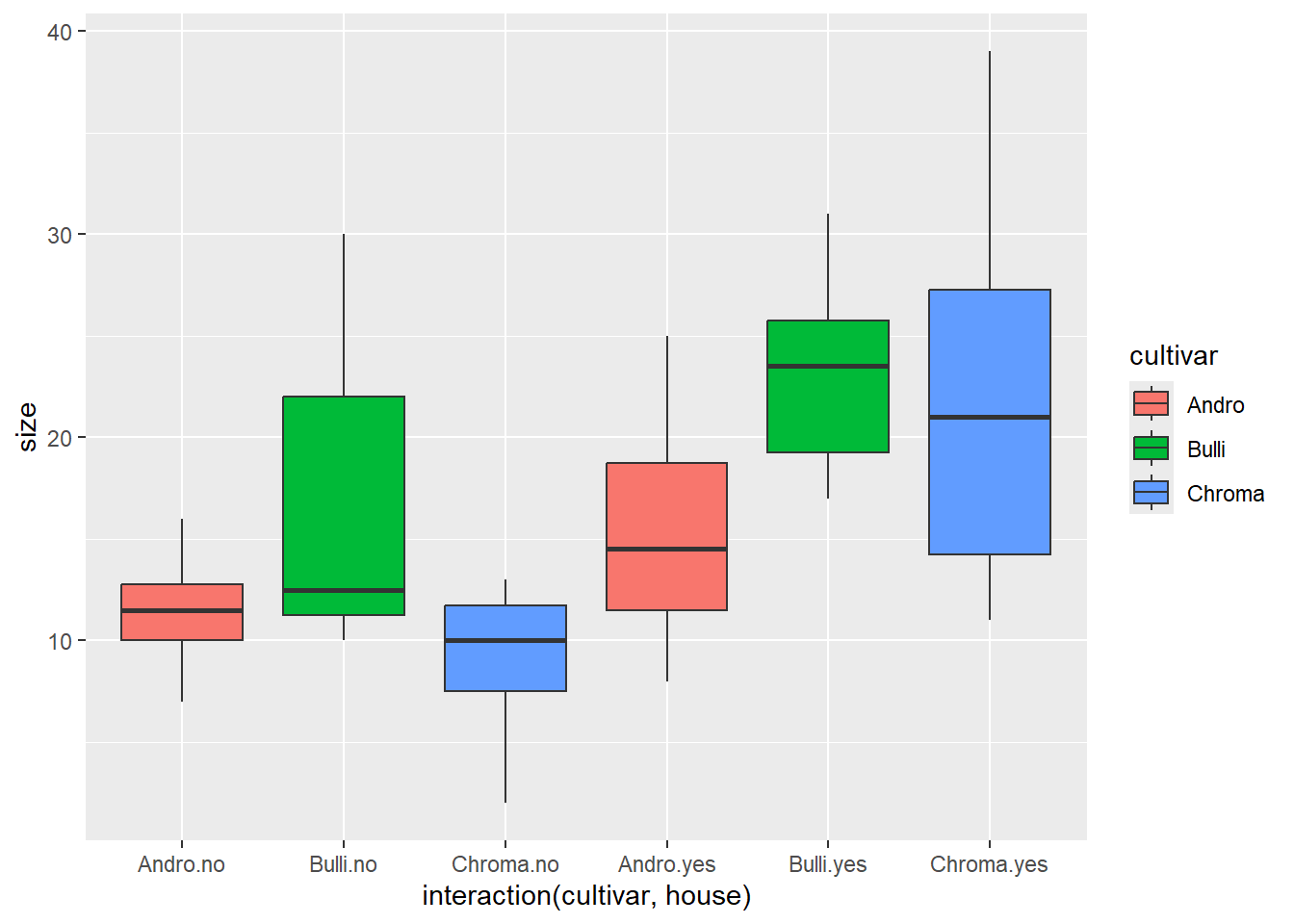
# Daten mit Boxplots anschauenggplot(blume3, aes(x =interaction(cultivar, house), y = size, fill = cultivar)) +geom_boxplot()
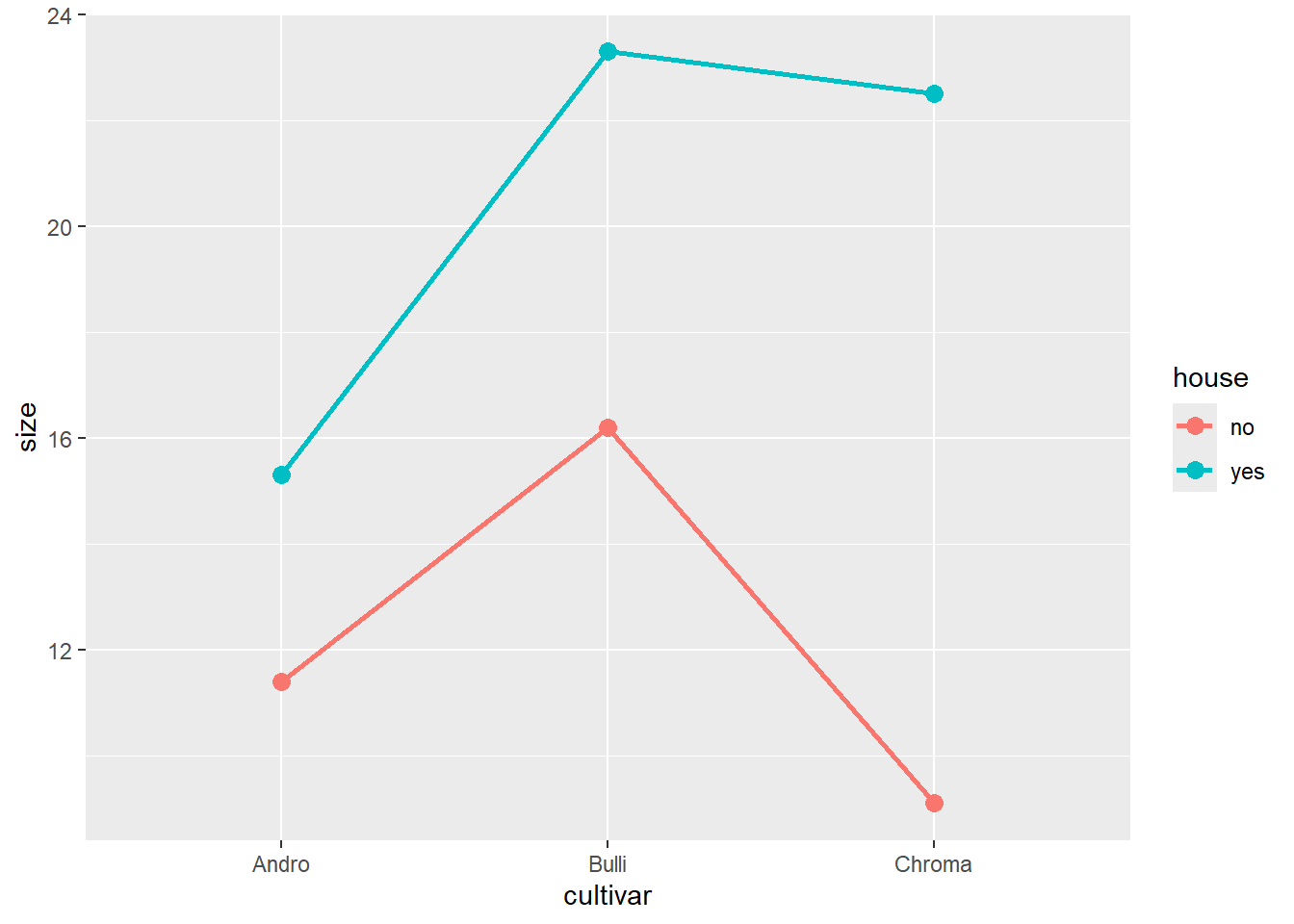
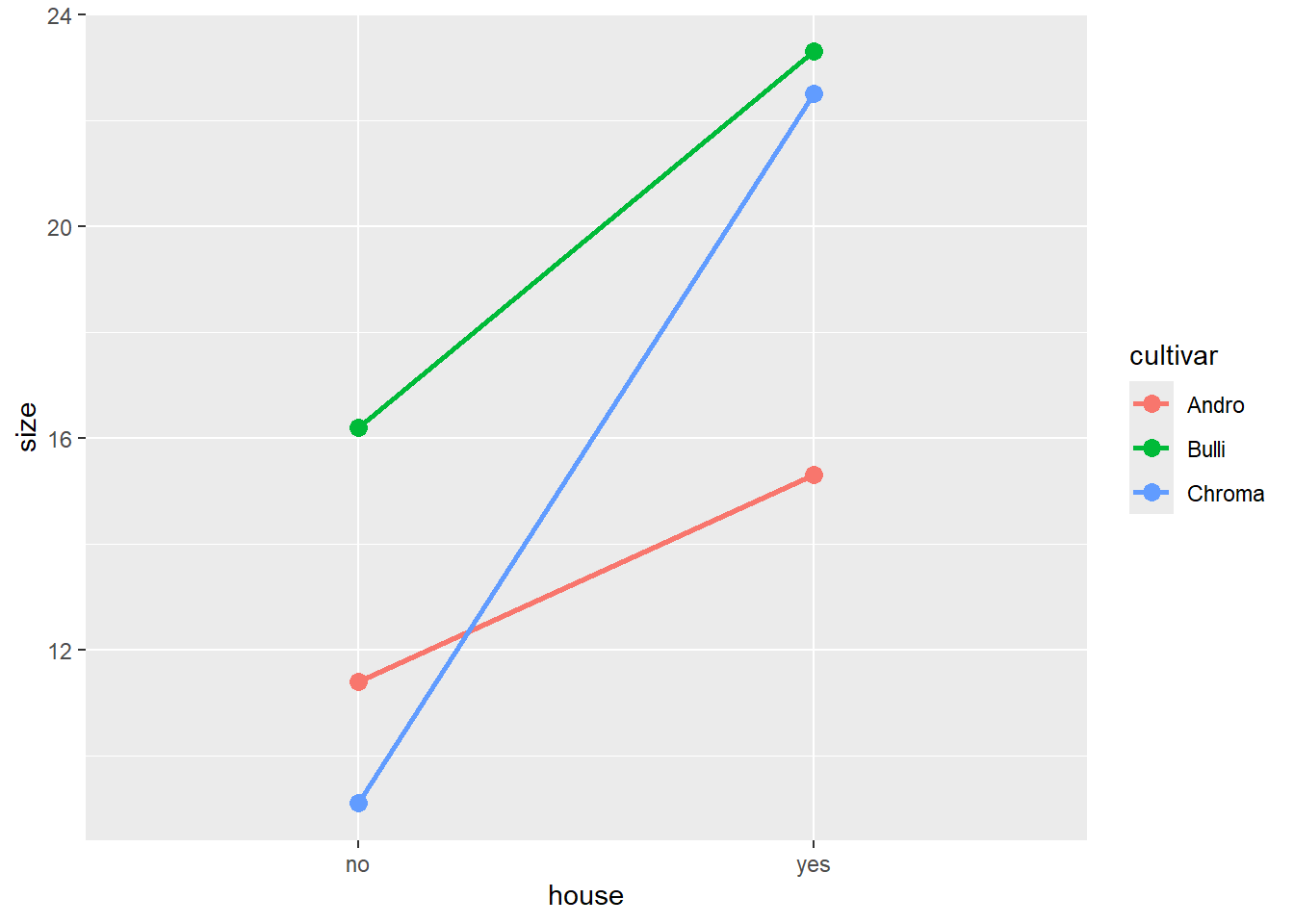
aov_3 <-aov(size ~ cultivar + house, data = blume3)summary(aov_3)
Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 417.1 208.5 5.005 0.01 *
house 1 992.3 992.3 23.815 9.19e-06 ***
Residuals 56 2333.2 41.7
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
aov_4a <-aov(size ~ cultivar + house + cultivar:house, data = blume3)summary(aov_4a)
Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 417.1 208.5 5.364 0.0075 **
house 1 992.3 992.3 25.520 5.33e-06 ***
cultivar:house 2 233.6 116.8 3.004 0.0579 .
Residuals 54 2099.6 38.9
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# Kurzschreibweise: "*" bedeutet, dass Interaktion zwischen cultivar und house eingeschlossen wirdaov_4b <-aov(size ~ cultivar * house, data = blume3)summary(aov_4b)
Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 417.1 208.5 5.364 0.0075 **
house 1 992.3 992.3 25.520 5.33e-06 ***
cultivar:house 2 233.6 116.8 3.004 0.0579 .
Residuals 54 2099.6 38.9
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary.lm(aov_4b)
Call:
aov(formula = size ~ cultivar * house, data = blume3)
Residuals:
Min 1Q Median 3Q Max
-11.500 -4.325 -0.300 3.075 16.500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.400 1.972 5.781 3.81e-07 ***
cultivarBulli 4.800 2.789 1.721 0.0909 .
cultivarChroma -2.300 2.789 -0.825 0.4131
houseyes 3.900 2.789 1.399 0.1677
cultivarBulli:houseyes 3.200 3.944 0.811 0.4207
cultivarChroma:houseyes 9.500 3.944 2.409 0.0194 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.236 on 54 degrees of freedom
Multiple R-squared: 0.439, Adjusted R-squared: 0.3871
F-statistic: 8.451 on 5 and 54 DF, p-value: 5.86e-06
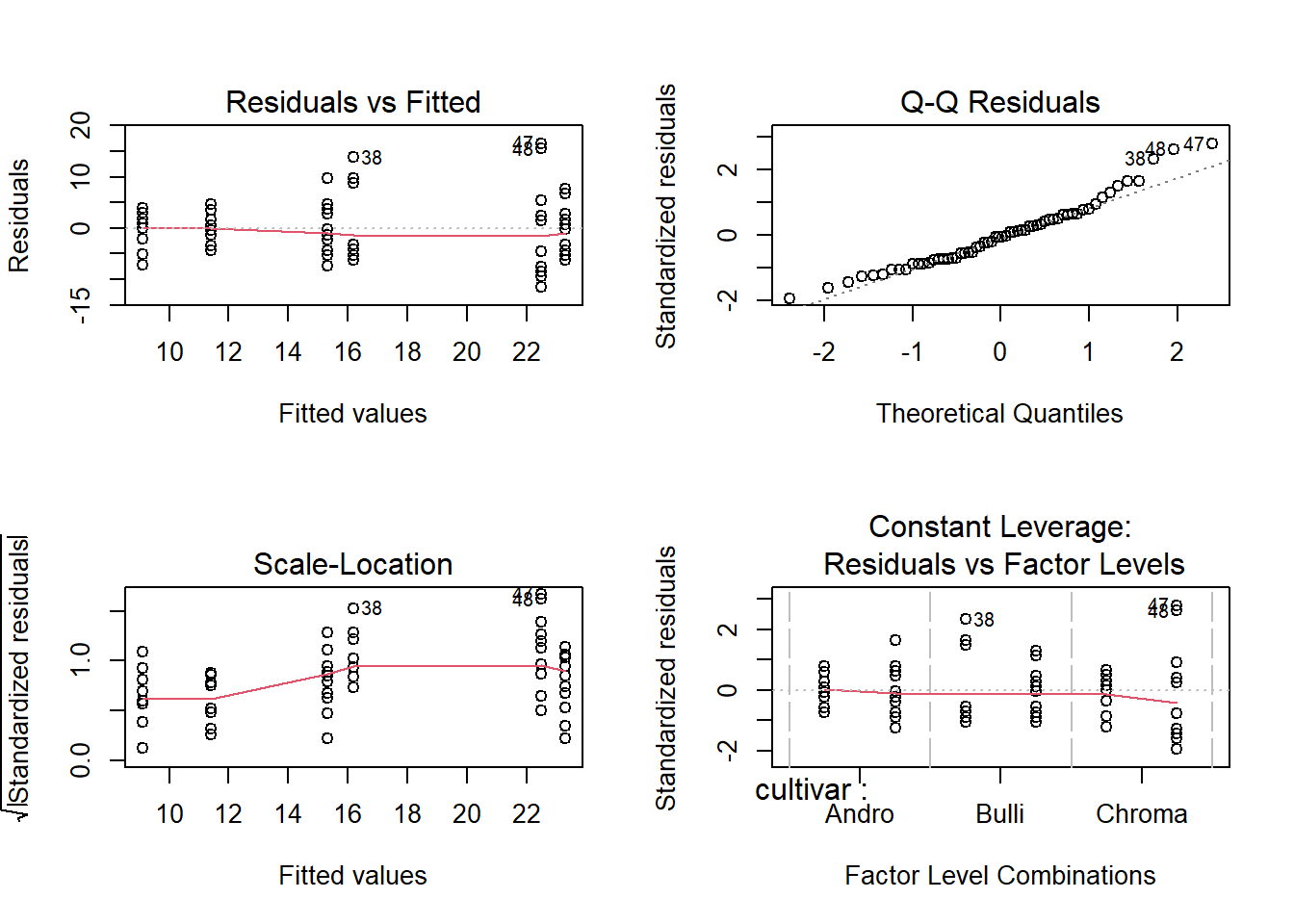
# 4 Plots in einem Fensterpar(mfrow =c(2, 2))plot(aov_4b)
Nicht-parametrische Alternativen, wenn Modellannahmen massiv verletzt sind
# Nicht-parametrische Alternative zu t-Testlibrary(coin)wilcox_test(size ~ cultivar, data = blume)
Asymptotic Wilcoxon-Mann-Whitney Test
data: size by cultivar (Andro, Bulli)
Z = 1.7445, p-value = 0.08106
alternative hypothesis: true mu is not equal to 0
Kruskal-Wallis-Test bei starken Abweichungen von der Normalverteilung, aber ähnlichen Varianzen
# Zum Vergleich normale ANOVA noch malsummary(aov_2)
Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 736.1 368.0 18.8 7.68e-06 ***
Residuals 27 528.6 19.6
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# Kruskal-Wallis-Testkruskal_test(size ~ cultivar, data = blume2)
Asymptotic Kruskal-Wallis Test
data: size by cultivar (Andro, Bulli, Chroma)
chi-squared = 16.686, df = 2, p-value = 0.0002381
library("FSA")# Post-Hoc mit korrigierten p-Werte nach Bejamini-HochbergdunnTest(size ~ cultivar, method ="bh", data = blume2)