Der Datensatz polis.csv beschreibt für 19 Inseln im Golf von Kalifornien, ob Eidechsen der Gattung Uta vorkommen (presence/absence: PA) in Abhängigkeit von der Form der Inseln (Verhältnis Umfang zu Fläche: RATIO
Bitte prüft mit einer logistischen Regression, ob und ggf. wie die Inselform die Präsenz der Eidechsen beinflusst
ISLAND RATIO PA
Angeldlg: 1 Min. : 0.21 Min. :0.0000
Bahiaan : 1 1st Qu.: 5.86 1st Qu.:0.0000
Bahiaas : 1 Median :15.17 Median :1.0000
Blanca : 1 Mean :18.74 Mean :0.5263
Bota : 1 3rd Qu.:23.20 3rd Qu.:1.0000
Cabeza : 1 Max. :63.16 Max. :1.0000
(Other) :13
Man erkennt, dass polis 19 Beobachtungen von drei Parametern enthält, wobei ISLAND ein Faktor mit den Inselnamen ist, während RATIO metrisch ist und PA nur 0 oder 1 enthält. Prädiktorvariable ist RATIO, abhängige Variable PA, mithin ist das korrekte statistische Verfahren eine logistische Regression (GLM).
# Definition des logistischen Modellsglm_1 <-glm(PA ~ RATIO, family ="binomial", data = polis)summary(glm_1)
Call:
glm(formula = PA ~ RATIO, family = "binomial", data = polis)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.6061 1.6953 2.127 0.0334 *
RATIO -0.2196 0.1005 -2.184 0.0289 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 26.287 on 18 degrees of freedom
Residual deviance: 14.221 on 17 degrees of freedom
AIC: 18.221
Number of Fisher Scoring iterations: 6
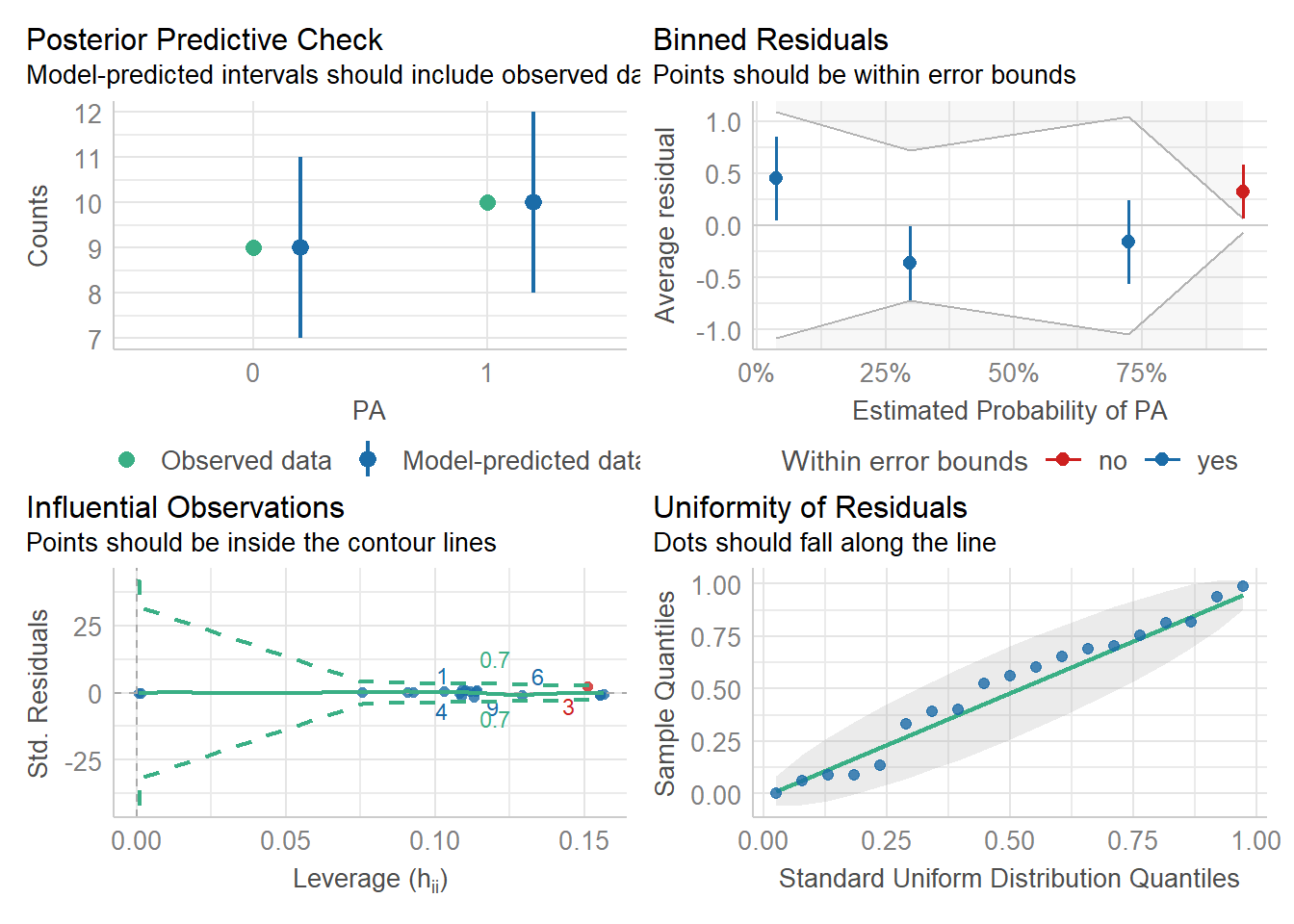
Modell ist signifikant (p-Wert in Zeile RATIO ist < 0.05). Jetzt müssen wir noch prüfen, ob es auch valide ist:
# Test Overdispersionp_load("performance")check_overdispersion(glm_1)
# Overdispersion test
dispersion ratio = 1.081
p-value = 0.768
# Modelldiagnostik für das gewählte Modell (wenn nicht signifikant, dann OK)1-pchisq(glm_1$deviance, glm_1$df.resid)
[1] 0.6514215
check_model(glm_1)
Ist ok Jetzt brauchen wir noch die Modellgüte (Pseudo-R2):
# Modellgüte (pseudo-R²)r2(glm_1)
# R2 for Logistic Regression
Tjur's R2: 0.521
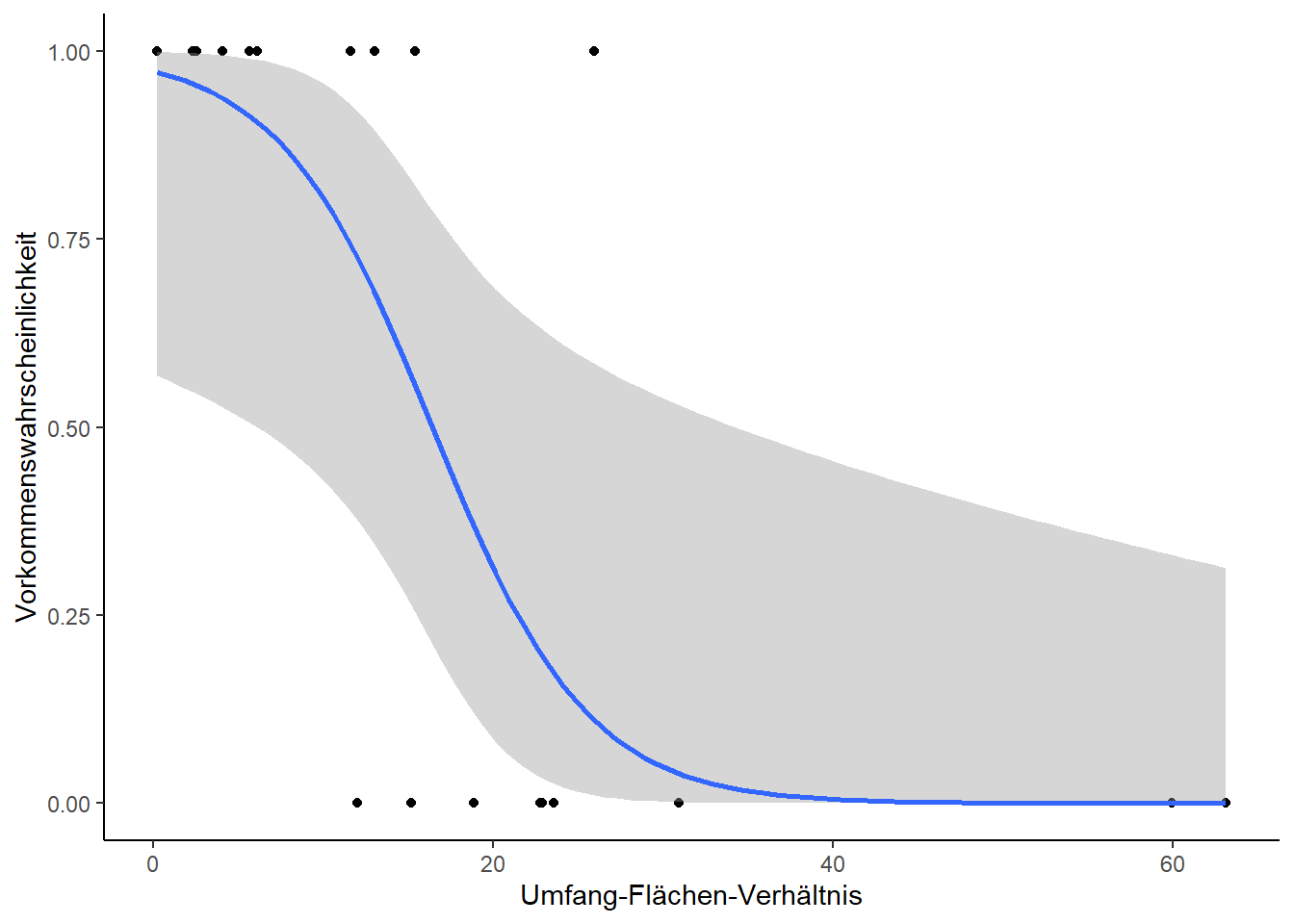
Um zu unser Modell zu interpretieren müssen wir noch in Betracht ziehen, dass wir nicht die Vorkommenswahrscheinlichkeit selbst, sondern logit (Vorkommenswahrscheinlichkeit) modelliert haben. Unser Ergebnis (die beiden Parameterschätzungen von oben, also 3.6061 und -0.2196) muss also zunächst in etwas Interpretierbares übersetzt werden:
# Steilheit der Beziehung in Modellen mit nur einem Parameterexp(glm_1$coef[2])
RATIO
0.8028734
< 1, d. h. Vorkommenswahrscheinlichkeit sinkt mit zunehmender Isolation.
# LD50 für 1-Parameter-Modelle (hier also x-Werte, bei der 50% der Inseln besiedelt sind)-glm_1$coef[1] / glm_1$coef[2]
(Intercept)
16.4242
p_load(MASS)dose.p(glm_1, p =0.5)
Dose SE
p = 0.5: 16.4242 3.055921
Am besten stellen wir auch unsere Funktionsgleichung dar. Dazu müssen wir das „Rohergebnis“ (mit P = Vorkommenswahrscheinlichkeit)