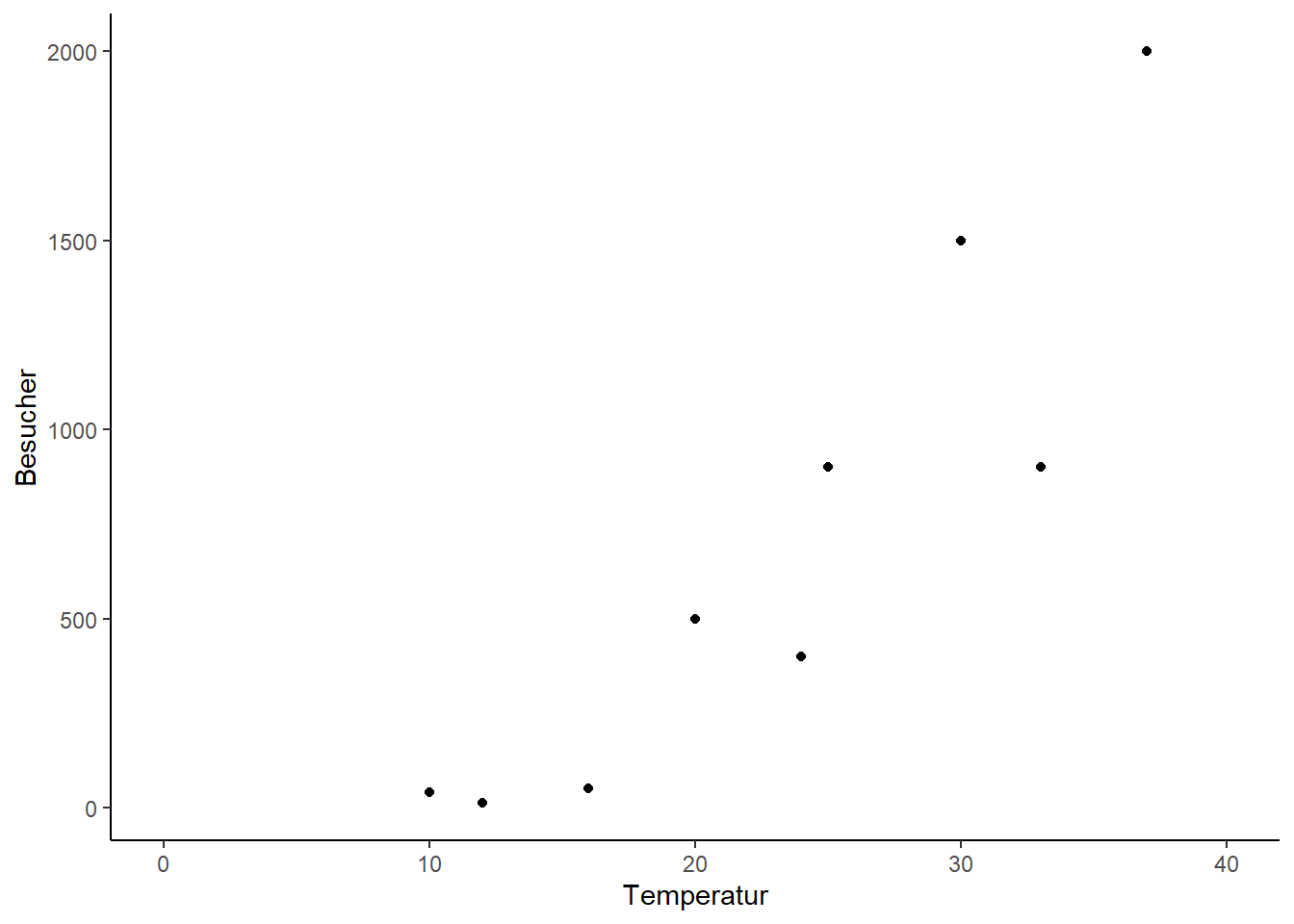
# GLMs definieren und anschauen# ist dasselbe wie ein LMglm_gaussian <-glm(Besucher ~ Temperatur, family ="gaussian", data = strand) summary(glm_gaussian)
Call:
glm(formula = Besucher ~ Temperatur, family = "gaussian", data = strand)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -855.01 290.54 -2.943 0.021625 *
Temperatur 67.62 11.80 5.732 0.000712 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for gaussian family taken to be 97138.03)
Null deviance: 3871444 on 8 degrees of freedom
Residual deviance: 679966 on 7 degrees of freedom
AIC: 132.63
Number of Fisher Scoring iterations: 2
Poisson Regression
# Poisson passt besser zu den Daten glm_poisson <-glm(Besucher ~ Temperatur, family ="poisson", data = strand) summary(glm_poisson)
Call:
glm(formula = Besucher ~ Temperatur, family = "poisson", data = strand)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.500301 0.056920 61.49 <2e-16 ***
Temperatur 0.112817 0.001821 61.97 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 6011.8 on 8 degrees of freedom
Residual deviance: 1113.7 on 7 degrees of freedom
AIC: 1185.1
Number of Fisher Scoring iterations: 5
Rücktranformation der Werte auf die orginale Skale (Hier Exponentialfunktion da family=possion als Link-Funktion den natürlichen Logarithmus (log) verwendet) Besucher = exp(3.50 + 0.11 Temperatur/°C)
# So kann man auf die Coefficients des Modells "extrahieren" und dann mit[] auswählenglm_poisson$coefficients
(Intercept) Temperatur
3.5003009 0.1128168
exp(glm_poisson$coefficients[1])# Anzahl besucher bei 0°C
(Intercept)
33.12542
exp(glm_poisson$coefficients[1] +30* glm_poisson$coefficients[2]) # Anzahl besucher bei 30°C
(Intercept)
977.3102
# Test Overdispersionp_load("performance")check_overdispersion(glm_poisson)
# Overdispersion test
dispersion ratio = 149.683
Pearson's Chi-Squared = 1047.778
p-value = < 0.001
-> Es liegt Overdispersion vor. Darum quasipoisson wählen.
glm_quasipoisson <-glm(Besucher ~ Temperatur, family ="quasipoisson", data = strand)summary(glm_quasipoisson)
Call:
glm(formula = Besucher ~ Temperatur, family = "quasipoisson",
data = strand)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.50030 0.69639 5.026 0.00152 **
Temperatur 0.11282 0.02227 5.065 0.00146 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 149.6826)
Null deviance: 6011.8 on 8 degrees of freedom
Residual deviance: 1113.7 on 7 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 5
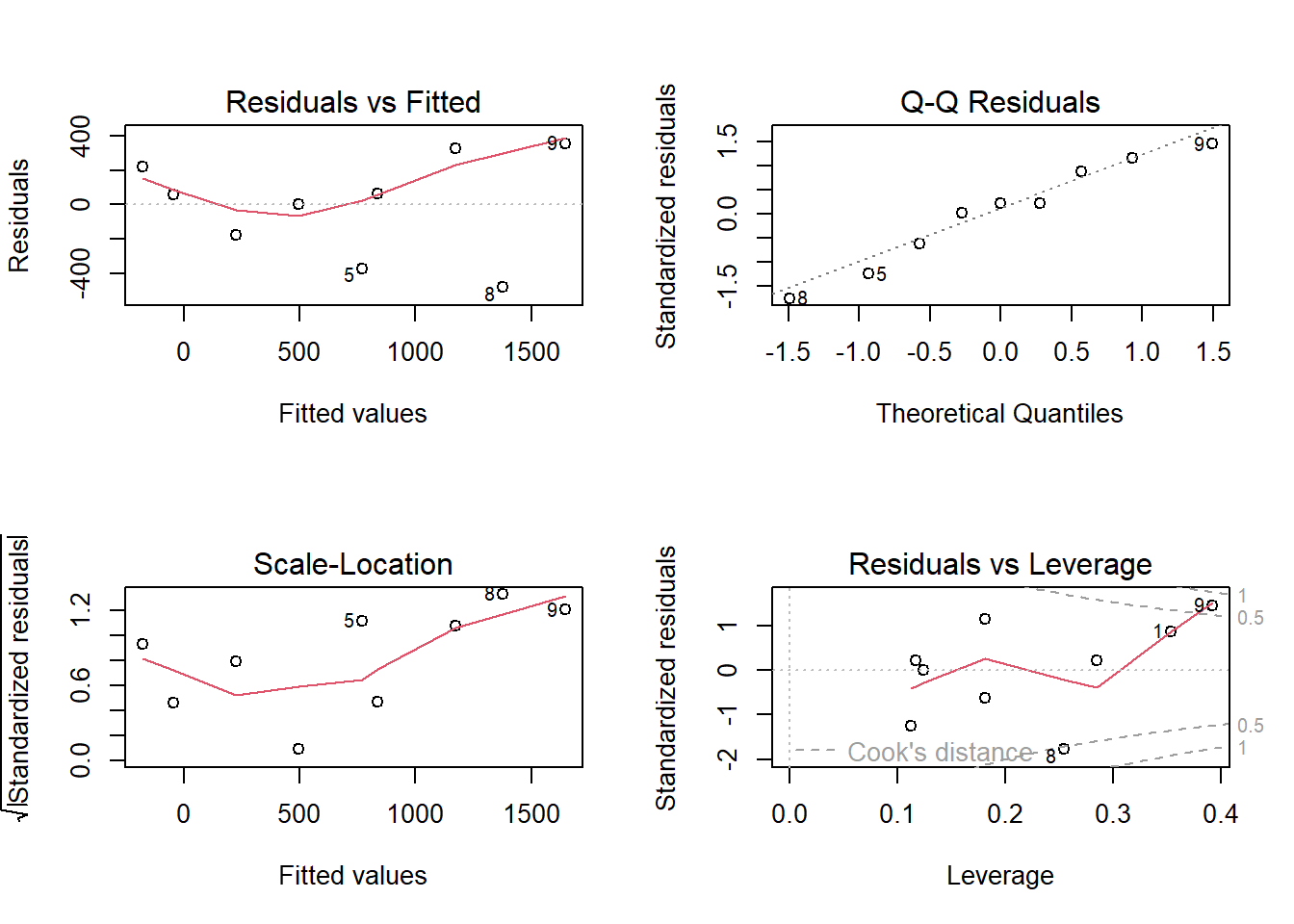
par(mfrow =c(2, 2))plot(glm_gaussian, main ="glm_gaussian")
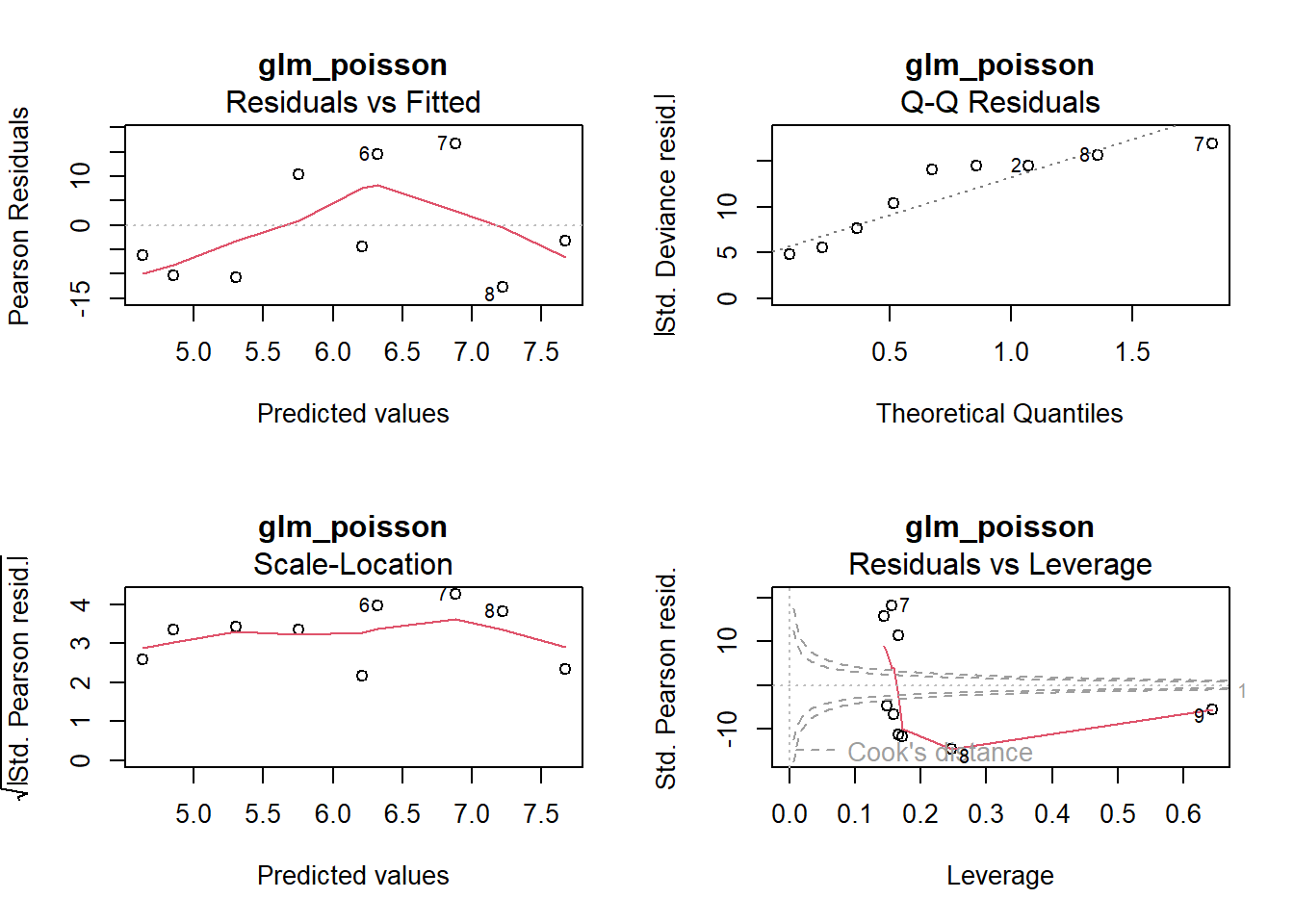
par(mfrow =c(2, 2))plot(glm_poisson, main ="glm_poisson")
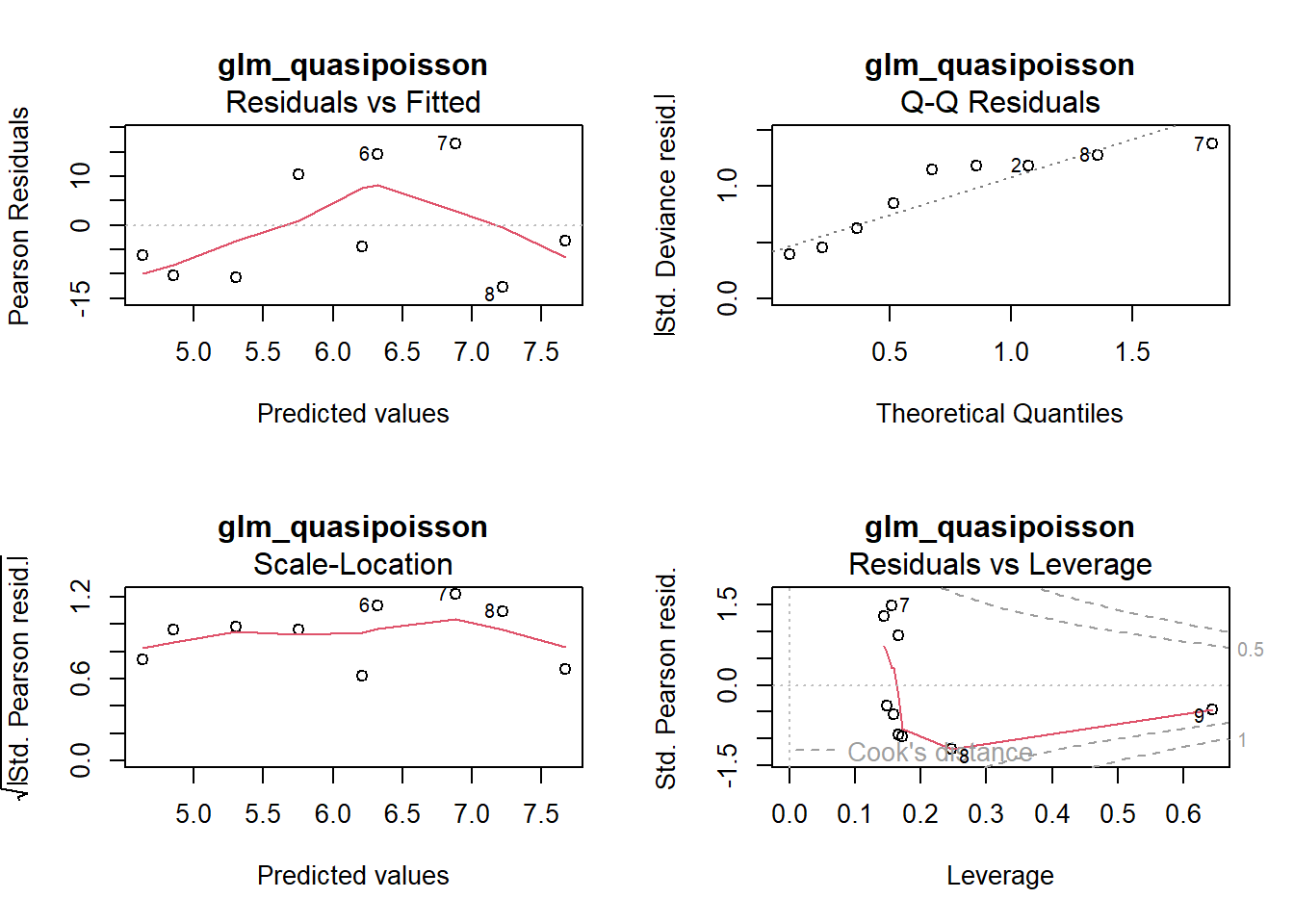
par(mfrow =c(2, 2))plot(glm_quasipoisson, main ="glm_quasipoisson")
-> Die Outputs von glm_poisson und glm_quasipoisson sind bis auf die p-Werte identisch.
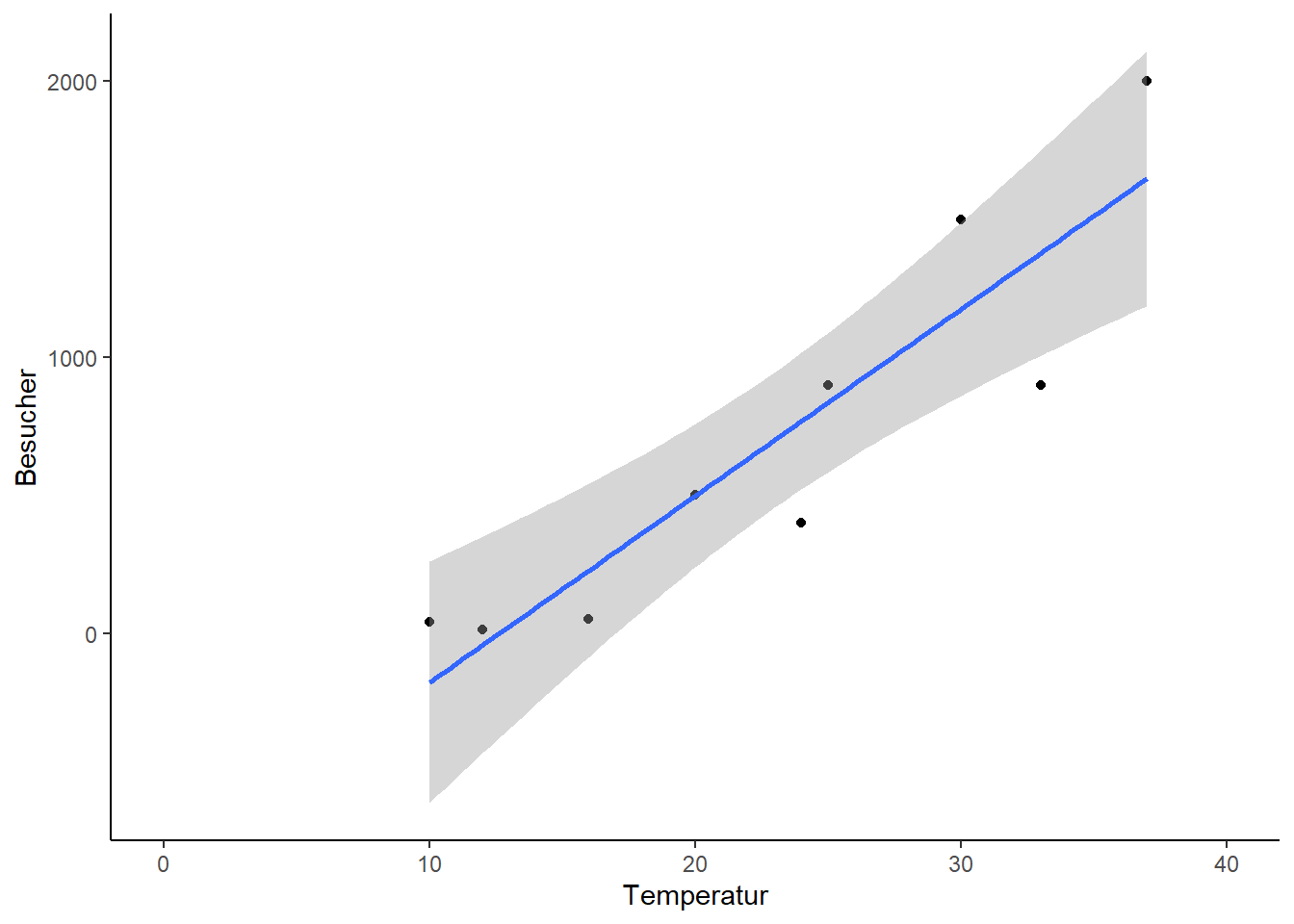
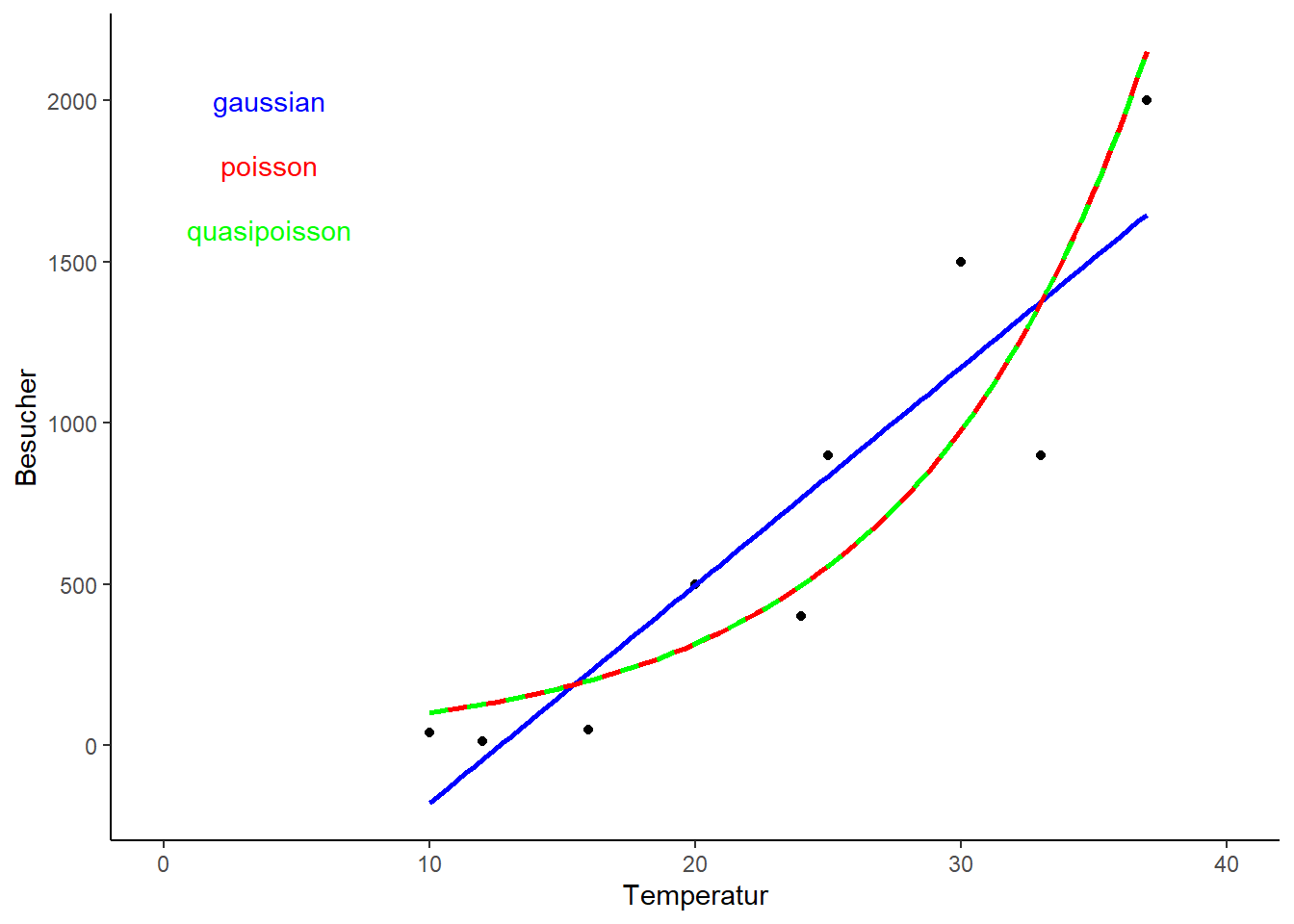
ggplot(data = strand, aes(x = Temperatur, y = Besucher)) +geom_point() +xlim(0, 40) +stat_smooth(method ="lm", color ="blue", se =FALSE) +stat_smooth(method ="glm", method.args =list(family ="poisson"), color ="red", se =FALSE) +stat_smooth(method ="glm", method.args =list(family ="quasipoisson"), color ="green", linetype ="dashed", se =FALSE) +annotate(geom="text", x =4, y =2000, label ="gaussian", color ="blue") +annotate(geom="text", x =4, y =1800, label ="poisson", color ="red") +annotate(geom="text", x =4, y =1600, label ="quasipoisson", color ="green") +theme_classic()
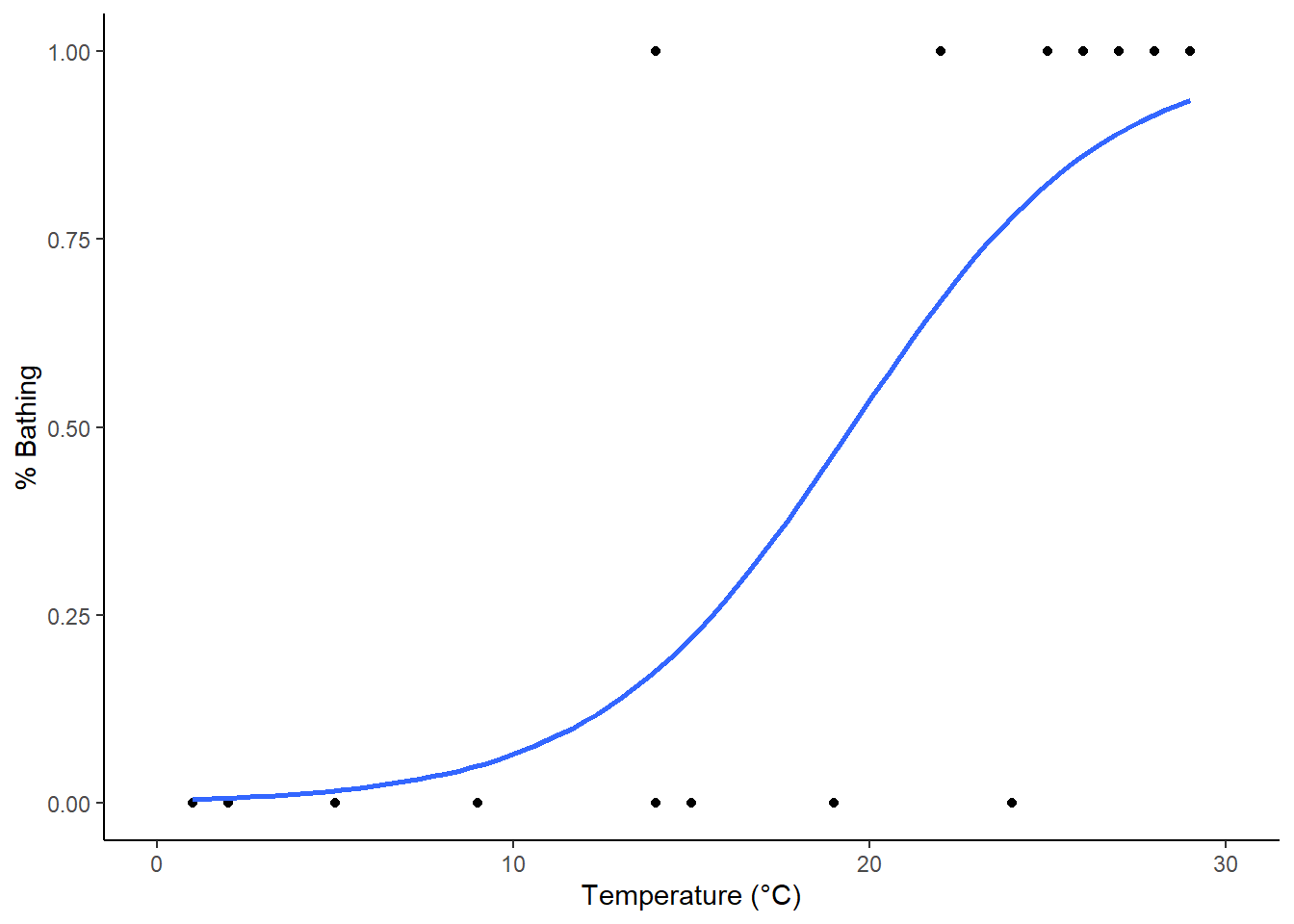
# Logistisches Modell definierenglm_logistic <-glm(badend ~ temperatur, family ="binomial", data = bathing)summary(glm_logistic)
Call:
glm(formula = badend ~ temperatur, family = "binomial", data = bathing)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -5.4652 2.8501 -1.918 0.0552 .
temperatur 0.2805 0.1350 2.077 0.0378 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 20.728 on 14 degrees of freedom
Residual deviance: 10.829 on 13 degrees of freedom
AIC: 14.829
Number of Fisher Scoring iterations: 6
# Test Overdispersioncheck_overdispersion(glm_logistic)
# Overdispersion test
dispersion ratio = 1.120
p-value = 0.808
# Modeldiagnostik (godness of fit test, wenn nicht signifikant, dann OK)1-pchisq(glm_logistic$deviance, glm_logistic$df.resid)
[1] 0.6251679
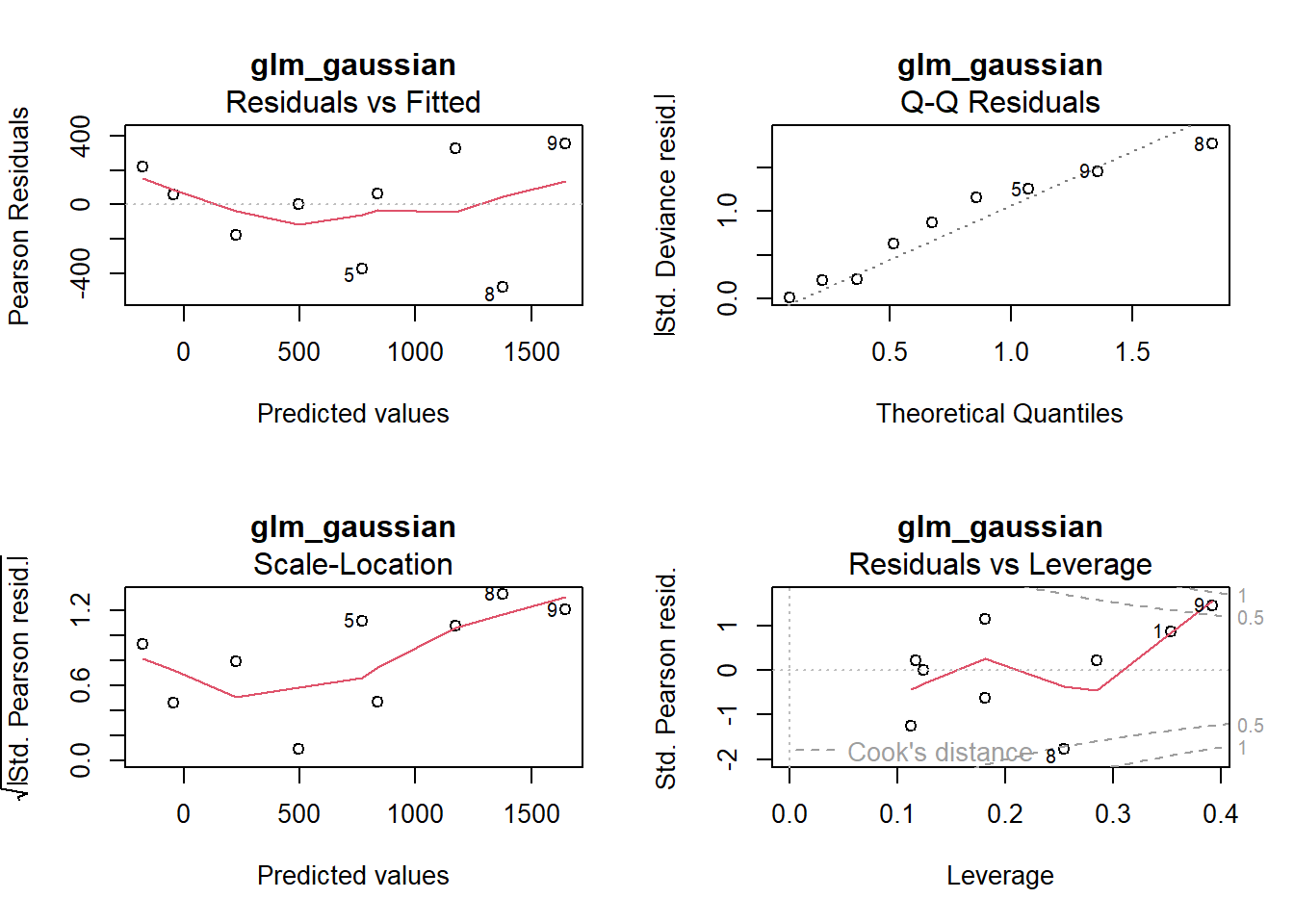
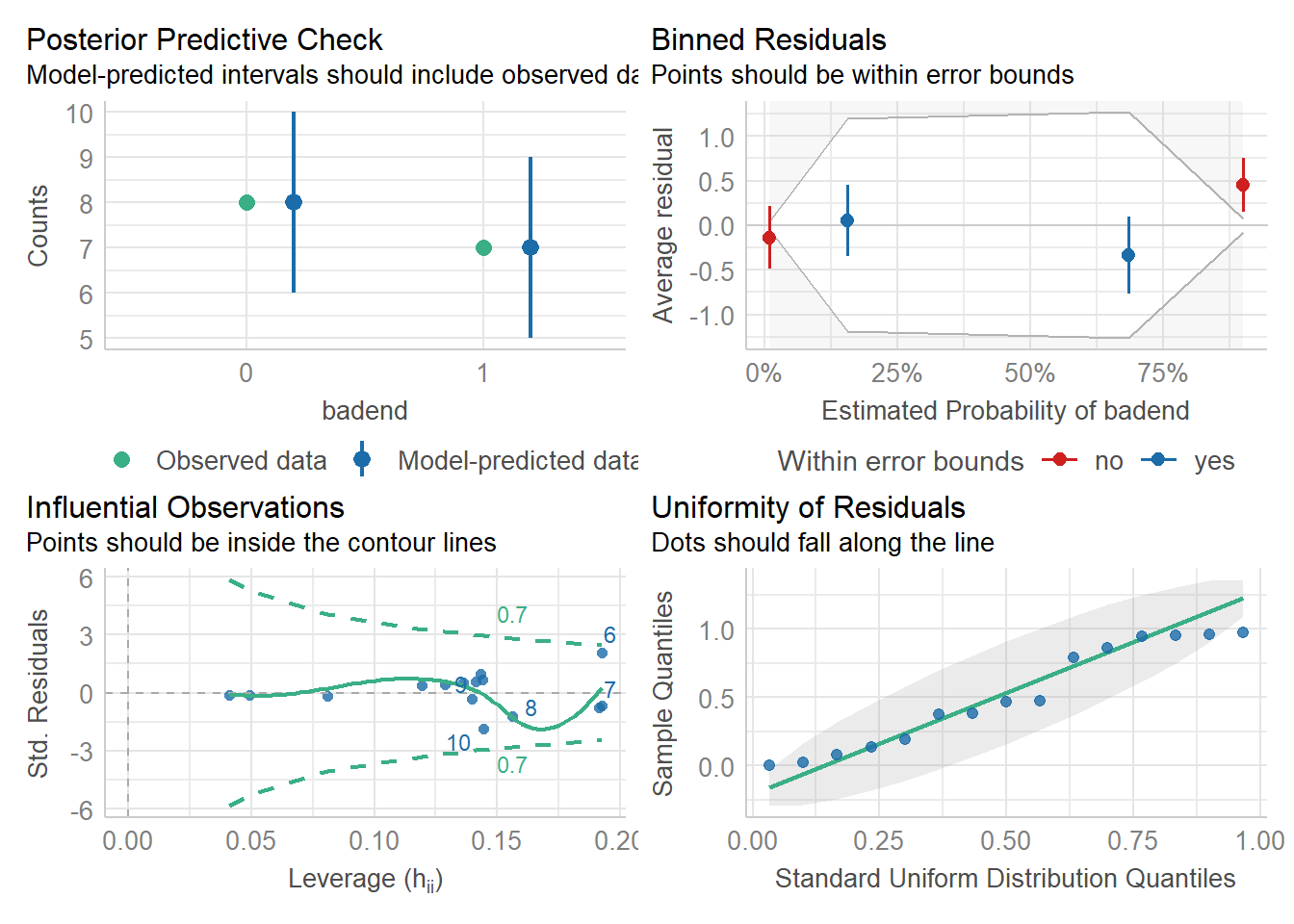
# Modeldiagnostik mit funktion "check_model"check_model(glm_logistic)
# Modelresultate# pseudo-R²r2(glm_logistic)
# R2 for Logistic Regression
Tjur's R2: 0.538
# Steilheit der Beziehung (relative Änderung der odds bei x + 1 vs. x)exp(glm_logistic$coefficients[2])
temperatur
1.323807
# LD50 (also hier: Temperatur, bei der 50% der Touristen baden)-glm_logistic$coefficients[1] / glm_logistic$coefficients[2]
(Intercept)
19.48311
# oderp_load("MASS")dose.p(glm_logistic, p =0.5)
Dose SE
p = 0.5: 19.48311 2.779485
# Vorhersagenpredicted <-predict(glm_logistic, type ="response")# Konfusionsmatrixkm <-table(bathing$badend, predicted >0.5)km
sex dose ndead ntotal
female:6 Min. : 1.0 Min. : 0.00 Min. :20
male :6 1st Qu.: 2.0 1st Qu.: 3.50 1st Qu.:20
Median : 6.0 Median : 9.50 Median :20
Mean :10.5 Mean : 9.25 Mean :20
3rd Qu.:16.0 3rd Qu.:13.75 3rd Qu.:20
Max. :32.0 Max. :20.00 Max. :20
Die Insektiziddosen wurden als Zweierpotenzen gewählt (d.h. jede Dosis ist doppelt so hoch wie die vorhergehende Dosis). Da wir von einer multiplikativen Wirkung der Dosis ausgehen, ist es vorteilhaft, die Werte mit einem Logarithmus mit Basis 2 zu logarithmieren.
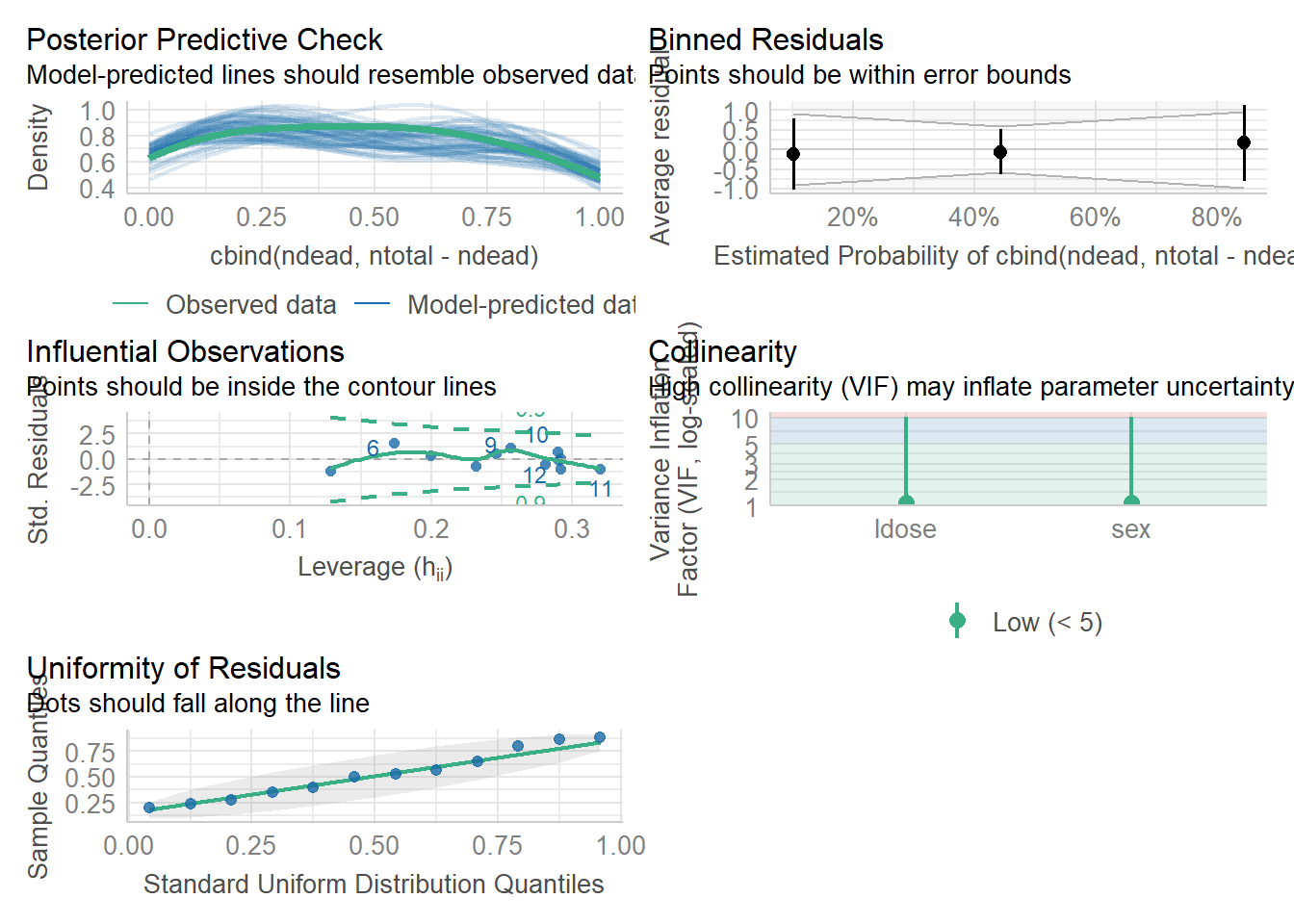
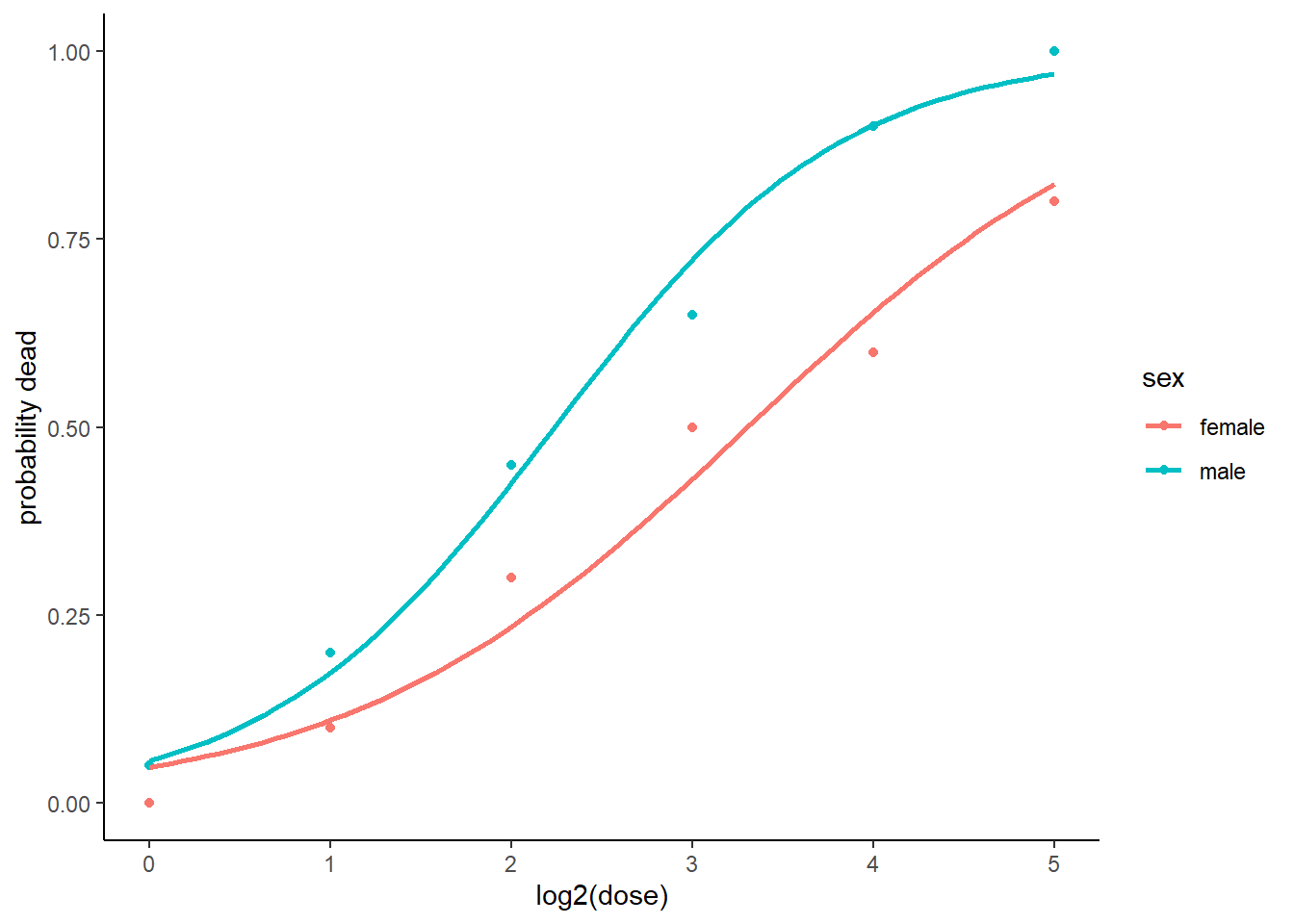
budworm$ldose <-log2(budworm$dose)# Das Modell kann auf zwei verschiedene Varianten spezifiziert werden glm_binomial <-glm( cbind( ndead, ntotal-ndead) ~ ldose*sex, family = binomial, data = budworm)glm_binom <-glm(ndead/ntotal ~ ldose*sex, family = binomial, weights = ntotal, data = budworm)coef(glm_binomial)