Lesen Sie den Datensatz steprasen_ukraine.csv in R ein. Dieser enthält Pflanzenartenzahlen (Species_richness) von 199 10 m² grossen Plots (Vegetationsaufnahmen) von Steppenrasen in der Ukraine sowie zahlreiche Umweltvariablen, deren Bedeutung und Einheiten im Kopf der ExcelTabelle angegeben sind.
Ermitteln Sie ein minimal adäquates Modell, das den Artenreichtum in den Plots durch die Umweltvariablen erklärt.
Bitte erklären und begründen Sie die einzelnen Schritte, die Sie unternehmen, um zu diesem Ergebnis zu kommen. Dazu erstellen Sie bitte ein mit Quarto generiertes html-Dokument, in das Sie Schritt für Schritt den verwendeten R-Code, die dazu gehörigen Ausgaben von R, Ihre Interpretation derselben und die sich ergebenden Schlussfolgerungen für das weitere Vorgehen dokumentieren.
Dieser Ablauf sollte insbesondere beinhalten:
Überprüfen der Datenstruktur nach dem Einlesen: welches sind die abhängige(n) und welches die unabängige(n) Variablen, sind alle Variablen für die Analyse geeignet?
Explorative Datenanalyse
Definition eines globalen Modelles und dessen Reduktion zu einem minimal adäquaten Modell
Durchführen der Modelldiagnostik für dieses
Generieren aller Zahlen, Statistiken und Tabellen, die für eine wiss. Ergebnisdarstellung benötigt werden
Formulieren Sie abschliessend einen Methoden- und Ergebnisteil (ggf. incl. adäquaten Abbildungen) zu dieser Untersuchung in der Form einer wissenschaftlichen Arbeit (ausformulierte schriftliche Zusammenfassung, mit je einem Absatz von ca. 60-100 Worten, resp. 3-8 Sätzen für den Methoden- und Ergebnisteil). D. h. alle wichtigen Informationen sollten enthalten sein, unnötige Redundanz dagegen vermieden werden.
Zu erstellen sind (1) Ein quarto generiertes html-Dokument mit begründetem Lösungsweg (Kombination aus R-Code, R Output und dessen Interpretation) und (2) ausformulierter Methoden- und Ergebnisteil (für eine wiss. Arbeit).
Man erkennt, dass alle Spalten bis auf die erste mit der Plot ID numerisch (num) sind. Wir können nun die Variable “PlotID” als rownames setzten
# Setze erste Spalte (colum) als rownamesukr <- ukr |>column_to_rownames(var ="PlotID")
Nun steht die abhängige Variable in Spalte 1 und die Prediktorvariablen in den Spalten 2 bis 19 stehen.
summary(ukr)
Species_richness Altitude Inclination Heat_index
Min. :14.00 Min. : 73.0 Min. : 1.00 Min. :-0.94000
1st Qu.:34.00 1st Qu.:140.0 1st Qu.:12.00 1st Qu.:-0.15500
Median :40.00 Median :166.0 Median :19.00 Median : 0.01000
Mean :40.23 Mean :161.7 Mean :19.28 Mean : 0.01603
3rd Qu.:47.50 3rd Qu.:188.0 3rd Qu.:25.00 3rd Qu.: 0.21500
Max. :67.00 Max. :251.0 Max. :48.00 Max. : 0.85000
Microrelief Grazing_intensity Litter Stones_and_rocks
Min. : 0.000 Min. :0.0000 Min. : 0.00 Min. : 0.000
1st Qu.: 2.500 1st Qu.:0.0000 1st Qu.: 3.50 1st Qu.: 0.000
Median : 5.000 Median :1.0000 Median : 7.00 Median : 0.500
Mean : 7.126 Mean :0.9296 Mean :12.16 Mean : 3.994
3rd Qu.: 7.000 3rd Qu.:2.0000 3rd Qu.:13.50 3rd Qu.: 4.000
Max. :100.000 Max. :3.0000 Max. :90.00 Max. :68.000
Gravel Fine_soil pH Conductivity
Min. : 0.000 Min. : 0.00 Min. :4.890 Min. : 40.0
1st Qu.: 0.000 1st Qu.: 2.00 1st Qu.:7.240 1st Qu.:148.5
Median : 0.000 Median : 5.00 Median :7.420 Median :171.0
Mean : 2.984 Mean : 7.02 Mean :7.286 Mean :162.3
3rd Qu.: 3.000 3rd Qu.:10.00 3rd Qu.:7.545 3rd Qu.:189.5
Max. :40.000 Max. :38.00 Max. :7.790 Max. :232.0
CaCO3 N_total C_org CN_ratio
Min. : 0.0042 Min. :0.0700 Min. : 1.040 Min. : 6.04
1st Qu.: 0.4306 1st Qu.:0.2000 1st Qu.: 2.850 1st Qu.:12.24
Median : 4.6578 Median :0.2700 Median : 3.560 Median :12.95
Mean : 7.4757 Mean :0.2788 Mean : 3.689 Mean :13.48
3rd Qu.:13.0002 3rd Qu.:0.3300 3rd Qu.: 4.400 3rd Qu.:14.02
Max. :35.2992 Max. :0.9500 Max. :11.300 Max. :27.42
Temperature Temperature_range Precipitation
Min. :78.00 Min. :326.0 Min. :577.0
1st Qu.:82.00 1st Qu.:328.0 1st Qu.:583.0
Median :84.00 Median :329.0 Median :592.0
Mean :84.82 Mean :328.6 Mean :596.4
3rd Qu.:88.00 3rd Qu.:330.0 3rd Qu.:602.5
Max. :92.00 Max. :331.0 Max. :630.0
Da es sich bei Artenzahlen um Zähldaten handelt, müsste man theoretisch ein glm mit Poisson-Verteilung rechnen; bei einem Mittelwert, der hinreichend von Null verschieden ist (hier: ca. 40), ist eine Poisson-Verteilung aber praktisch nicht von einer Normalverteilung zu unterscheiden und wir können uns den Aufwand auch sparen).
cor <-cor(ukr[, 2:19])cor[abs(cor)<0.7] <-0cor
Die Korrelationsanalyse dient dazu, zu entscheiden, ob die Prädiktorvariablen hinreichend voneinander unabhängig sind, um alle in das globale Modell hinein zu nehmen. Bei Pearson’s Korrelationskoeffizienten r, die betragsmässig grösser als 0.7 sind, würde es problematisch. Alternativ hätten wir auch den VIF (Variance Inflation Factor) als Kriterium für den möglichen Ausschluss von Variablen aus dem globalen Modell nehmen können.
Wenn man auf cor nun doppel-klickt und es in einem separaten Fenster öffnet, sieht man, wo es problematische Korrelationen zwischen Variablenpaaren gibt. Es sind dies Altitude vs. Temperature und N.total vs. C.org. Wir müssen aus jedem dieser Paare jetzt eine Variable rauswerfen, am besten jene, die weniger gut interpretierbar ist. Ich entscheide mich dafür Temperature statt Altitude (weil das der direktere ökologische Wirkfaktor ist) und C.org statt N.total zu behalten (weil es in der Literatur mehr Daten zum Humusgehalt als zum N-Gehalt gibt, damit eine bessere Vergleichbarkeit erzielt wird). Die Aussagen, die wir für die beibehaltene Variable erzielen, stehen aber +/- auch für die entfernte.
Das Problem ist aber, dass wir immer noch 16 Variablen haben, was einen sehr leistungsfähigen Rechner oder sehr lange Rechenzeit erfordern würde. Wir sollten also unter 15 Variablen kommen. Wir könnten uns jetzt überlegen, welche uns ökologisch am wichtigsten sind, oder ein noch strengeres Kriterium bei r verwenden, etwa 0.6
Entsprechend „werfen“ wir auch noch die folgenden Variablen „raus“: Temperature.range (positiv mit Temperature), Precipitation (negativ mit Temperature) sowie Conductivity (positiv mit pH).
Nun können wir das globale Modell definieren, indem wir alle verbleibenden Variablen aufnehmen, das sind 13. (Wenn das nicht eh schon so viele wären, dass es uns an die Grenze der Rechenleistung bringt, hätten wir auch noch darüber nachdenken können, einzelne quadratische Terme oder Interaktionsterme zu berücksichtigen).
Nun gibt es im Prinzip zwei Möglichkeiten, vom globalen (vollen) Modell zu einem minimal adäquaten Modell zu kommen. (1) Der Ansatz der „frequentist statistic“, in dem man aus dem vollen Modell so lange schrittweise Variablen entfernt, bis nur noch signifikante Variablen verbleiben. (2) Den informationstheoretischen Ansatz, bei dem alle denkbaren Modelle berechnet und verglichen werden (also alle möglichen Kombinationen von 13,12,…, 1, 0 Parametern). Diese Lösung stelle ich im Folgenden vor:
Jetzt bekommen wir die besten der insgesamt 8192 möglichen Modelle gelistet mit ihren Parameterschätzungen und ihrem AICc.
Das beste Modell umfasst 5 Parameter (CaCO3, CN.ratio, Grazing.intensity. Heat.index, Litter). Allerdings ist das nächstbeste Modell (mit 6 Parametern) nur wenig schlechter (delta AICc = 0.71), was sich in fast gleichen (und zudem sehr niedrigen) Akaike weights bemerkbar macht. Nach dem Verständnis des Information theoretician approach, sollte man in einer solchen Situation nicht das eine „beste“ Modell benennen, sondern eine Aussage über die Gruppe der insgesamt brauchbaren Modelle treffen. Hierzu kann man (a) Importance der Parameter über alle Modelle hinweg berechnen (= Summe der Akaike weights aller Modelle, die den betreffenden Parameter enthalten) und/oder (b) ein nach Akaike weights gemitteltes Modell berechnen.
# Importance values der Variablensw(allmodels)
Heat_index Litter CaCO3 CN_ratio Grazing_intensity
Sum of weights: 1.00 0.92 0.82 0.73 0.68
N containing models: 4096 4096 4096 4096 4096
Stones_and_rocks Temperature Microrelief Gravel Fine_soil
Sum of weights: 0.43 0.39 0.33 0.31 0.31
N containing models: 4096 4096 4096 4096 4096
C_org pH Inclination
Sum of weights: 0.30 0.26 0.26
N containing models: 4096 4096 4096
Demnach ist Heat.index die wichtigste Variable (in 100% aller relevanten Modelle), während ferner Litter, CaCO3, CN_ratio und Grazing_intensity in mehr als 50% der relevanten Modelle enthalten sind.
# Modelaveraging (Achtung: dauert mit 13 Variablen einige Minuten)avgmodel <-model.avg(allmodels)summary(avgmodel)
Aus dem gemittelten Modell können wir die Richtung der Beziehung (positiv oder negativ) und ggf. die Effektgrössen (wie verändert sich die Artenzahl, wenn die Prädiktorvariable um eine Einheit zunimmt?) ermitteln.
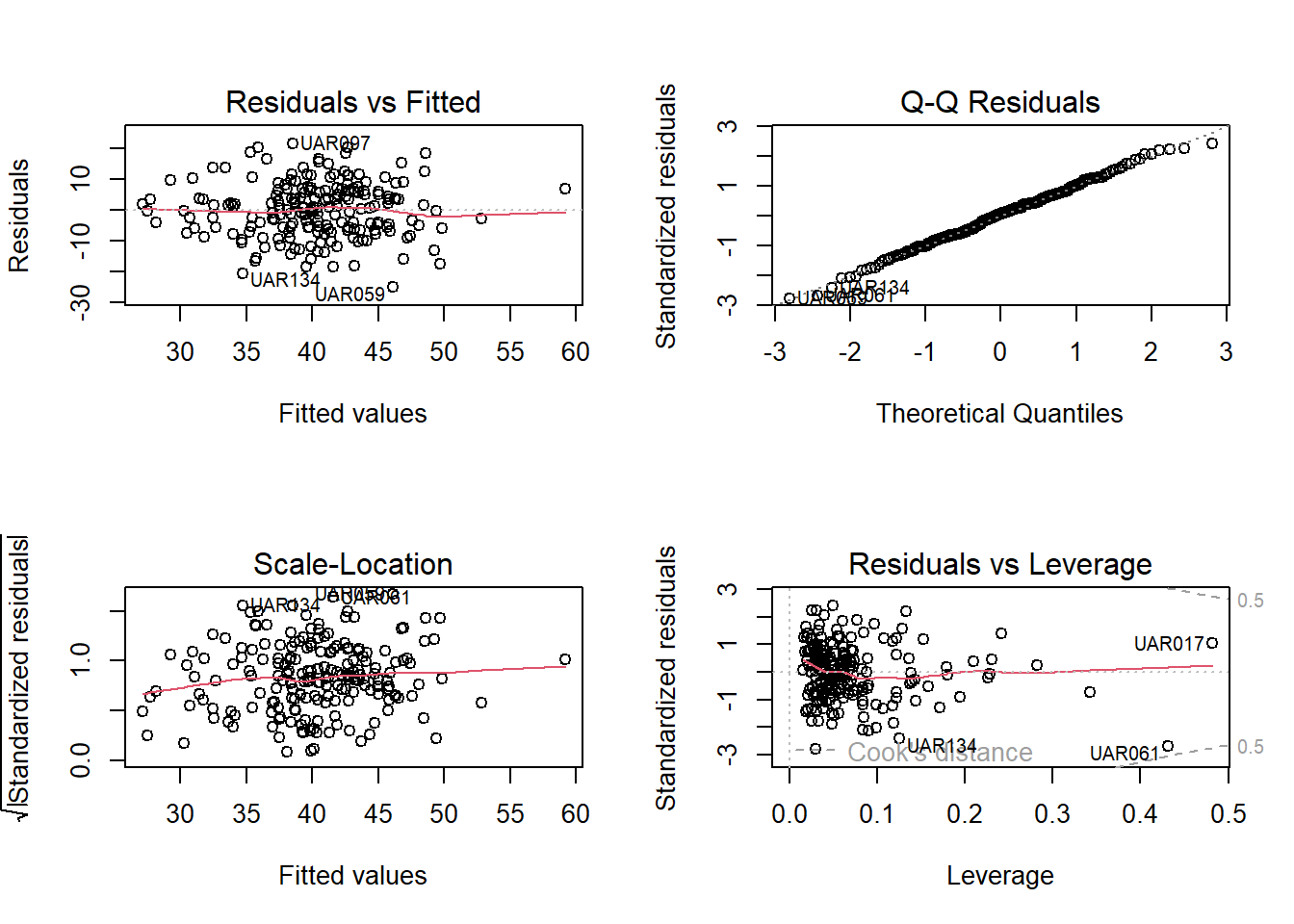
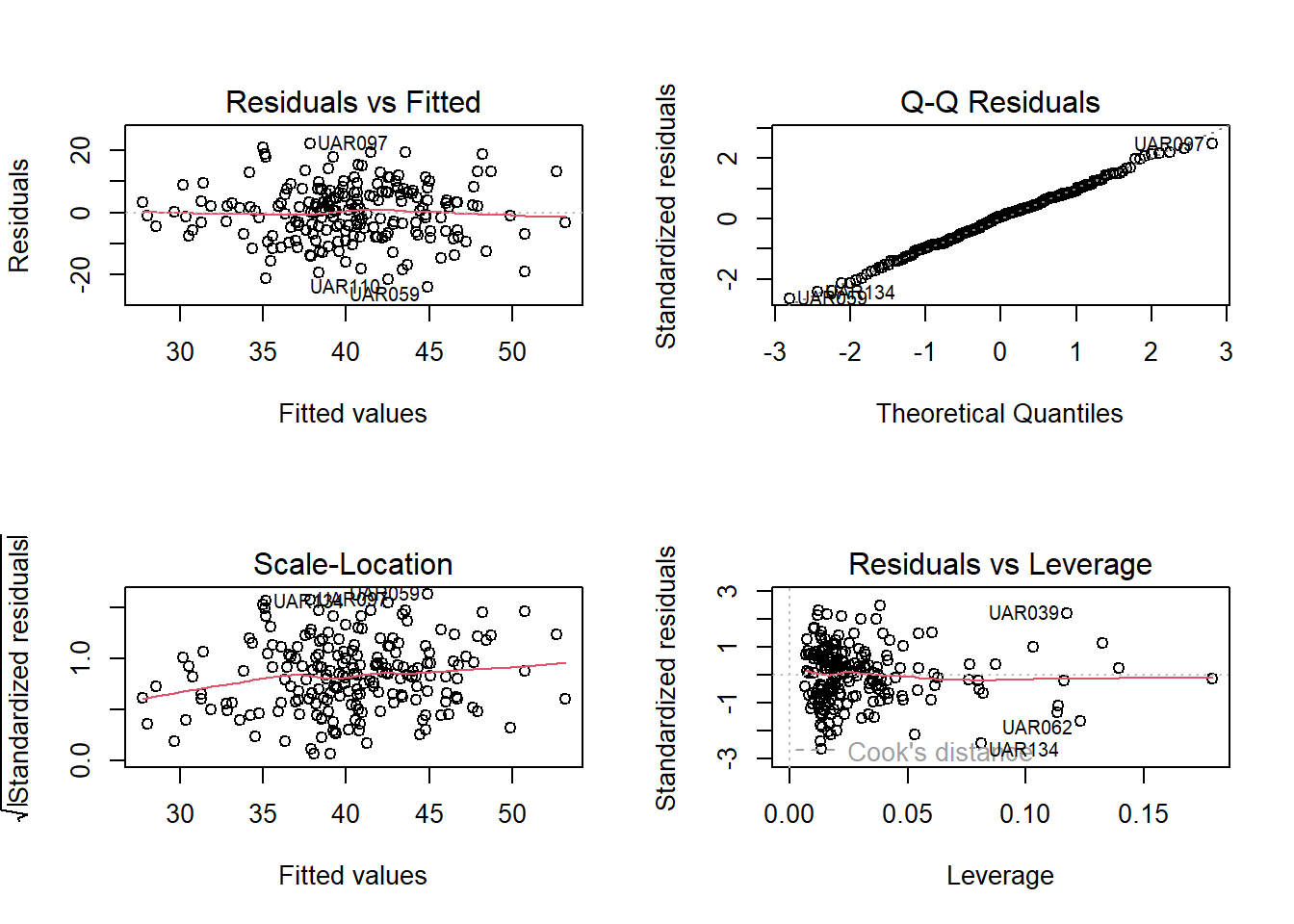
# Modelldiagnostik nicht vergessenpar(mfrow =c(2, 2))plot(global_model)
Wie immer kommt am Ende die Modelldiagnostik. Wir können uns entweder das globale Modell oder das Modell mit den 5 Variablen mit importance > 50% anschauen. Das Bild sieht fast identisch aus und zeigt keinerlei problematische Abweichungen, d. h. links oben weder ein Keil, noch eine Banane, rechts oben eine nahezu perfekte Gerade.