library("sf")
library("terra")
library("dplyr")
library("readr")
library("ggplot2")
library("PerformanceAnalytics")
library("pastecs")
library("car")
library("psych")
options(scipen = 999)Multivariate Modelle
Einstieg Multivariate Modelle / Habitatselektionsmodell
Libraries laden
Aufgabe 1
Einlesen des Gesamtdatensatzes für die Multivariate Analyse von Moodle
- Sichtung des Datensatzes, der Variablen und der Datentypen
- Kontrolle wieviele Rehe in diesem Datensatz enthalten sind
Musterlösung
DF_mod <- read_delim("datasets/fallstudie_n/Aufgabe4_Datensatz_Habitatnutzung_Modelle_241028.csv", delim = ";")
str(DF_mod)
class(DF_mod$time_of_day)
table(DF_mod$id)
DF_mod |>
group_by(id) |>
summarize(anzahl = n())
length(unique(DF_mod$id))Aufgabe 2
Unterteilung des Datensatzes in Teildatensätze entsprechend der Tageszeit
Musterlösung
DF_mod_night <- DF_mod |>
filter(time_of_day == "night")
DF_mod_day <- DF_mod |>
filter(time_of_day == "day")
# Kontrolle
table(DF_mod_night$time_of_day)
##
## night
## 3964
table(DF_mod_day$time_of_day)
##
## day
## 3964Aufgabe 3
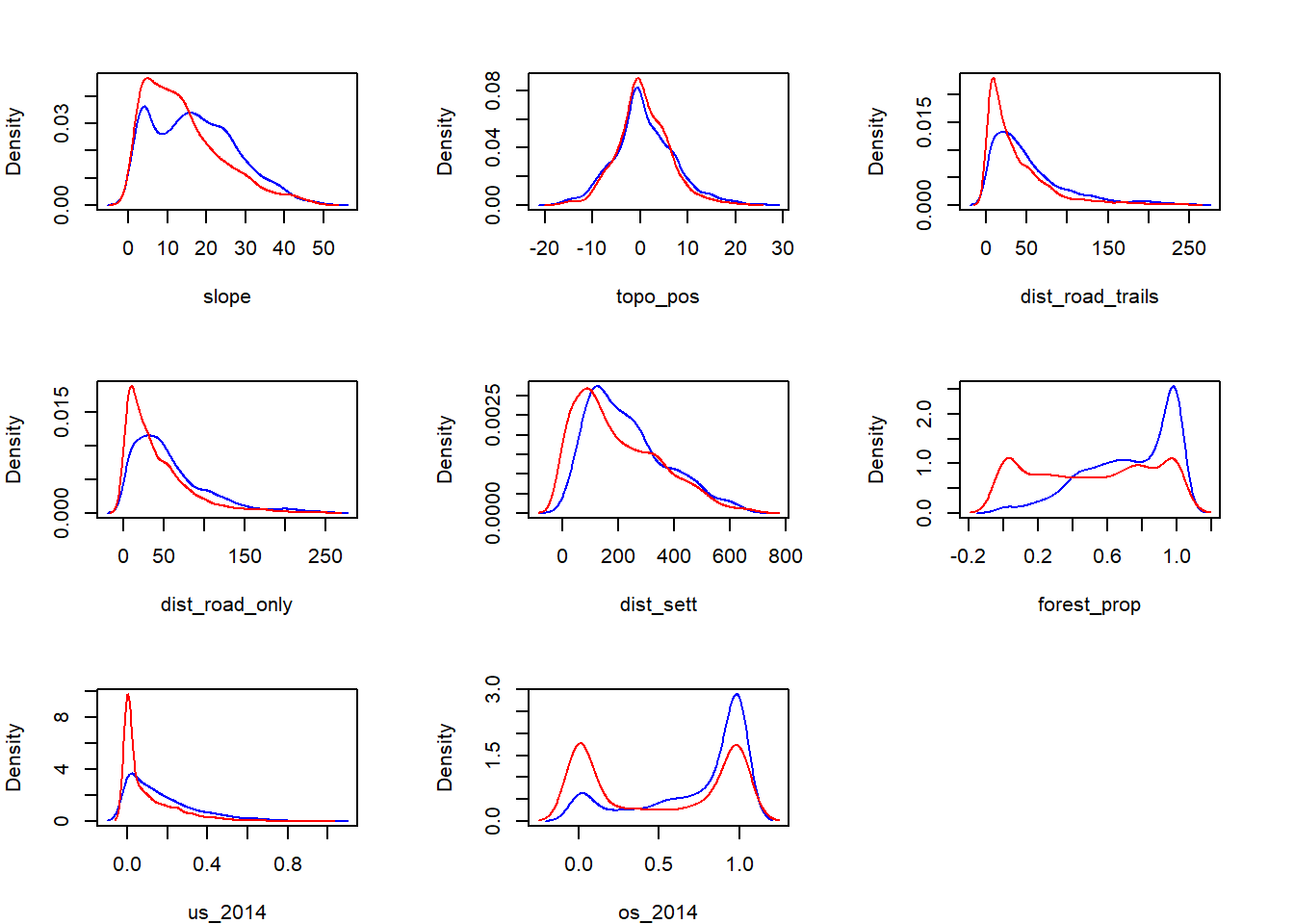
Erstellen von Density Plots der Präsenz / Absenz in Abhängigkeit der unabhängigen Variablen. Diese Übung dient einer ersten groben Einschätzung der Wirkung der Umweltvariablen auf die abhängige Variable (Präsenz/Absenz in unserem Fall)
# Ein Satz Density Plots für den Tagesdatensatz und einer für den Nachtdatensatz
par(mfrow = c(3, 3), mar = c(4, 4, 3, 3)) # Vorbereitung Raster für Plots
# innerhalb des for()-loops die Nummern der gewünschten Spalten einstellen
for (i in 5:12) {
dp <- DF_mod_day |> filter(pres_abs == 1) |> pull(i)
dp <- density(dp)
da <- DF_mod_day |> filter(pres_abs == 0) |> pull(i)
da <- density(da)
plot(0, 0, type = "l",
xlim = range(c(dp$x, da$x)),
ylim = range(dp$y, da$y),
xlab = names(DF_mod_day[i]),
ylab = "Density"
)
lines(dp$x, dp$y, col = "blue") # Präsenz = used
lines(da$x, da$y, col = "red") # Absenz = available
}
Aufgabe 4
Testen eurer erklärenden Variablen auf Normalverteilung (nur kontinuierliche)
Musterlösung
# klassischer Weg mit shapiro-wilk (vergl. Stats-Skript der Theorielektionen)
# mehrere Spalten, verschiedenene statistische Kenngrössen werden angezeigt. Normalverteilung: Wert ganz unten. p>0.05 = ja
round(stat.desc(DF_mod_day[5:12], basic = F, norm = T),3)
## slope topo_pos dist_road_trails dist_road_only dist_sett
## median 13.706 0.233 29.866 35.056 180.966
## mean 15.356 0.733 42.619 47.657 211.911
## SE.mean 0.163 0.093 0.668 0.690 2.359
## CI.mean.0.95 0.319 0.183 1.309 1.353 4.624
## var 105.214 34.574 1767.202 1888.047 22051.998
## std.dev 10.257 5.880 42.038 43.452 148.499
## coef.var 0.668 8.020 0.986 0.912 0.701
## skewness 0.733 0.278 1.872 1.632 0.721
## skew.2SE 9.425 3.578 24.071 20.976 9.269
## kurtosis -0.092 0.748 4.033 2.994 -0.174
## kurt.2SE -0.594 4.807 25.933 19.254 -1.119
## normtest.W 0.942 0.990 0.807 0.843 0.945
## normtest.p 0.000 0.000 0.000 0.000 0.000
## forest_prop us_2014 os_2014
## median 0.655 0.059 0.785
## mean 0.598 0.119 0.594
## SE.mean 0.005 0.002 0.007
## CI.mean.0.95 0.010 0.005 0.013
## var 0.110 0.023 0.175
## std.dev 0.332 0.150 0.419
## coef.var 0.555 1.258 0.705
## skewness -0.405 1.647 -0.425
## skew.2SE -5.202 21.181 -5.467
## kurtosis -1.116 2.924 -1.572
## kurt.2SE -7.174 18.800 -10.106
## normtest.W 0.910 0.793 0.781
## normtest.p 0.000 0.000 0.000
# empfohlener Weg
ggplot(DF_mod_day, aes(slope)) +
geom_histogram(aes(y = after_stat(density)), color = "black", fill = "white") +
stat_function(fun = dnorm, args = list(mean = mean(DF_mod_day$slope, na.rm = T), sd = sd(DF_mod_day$slope, na.rm = T)), color = "black", linewidth = 1)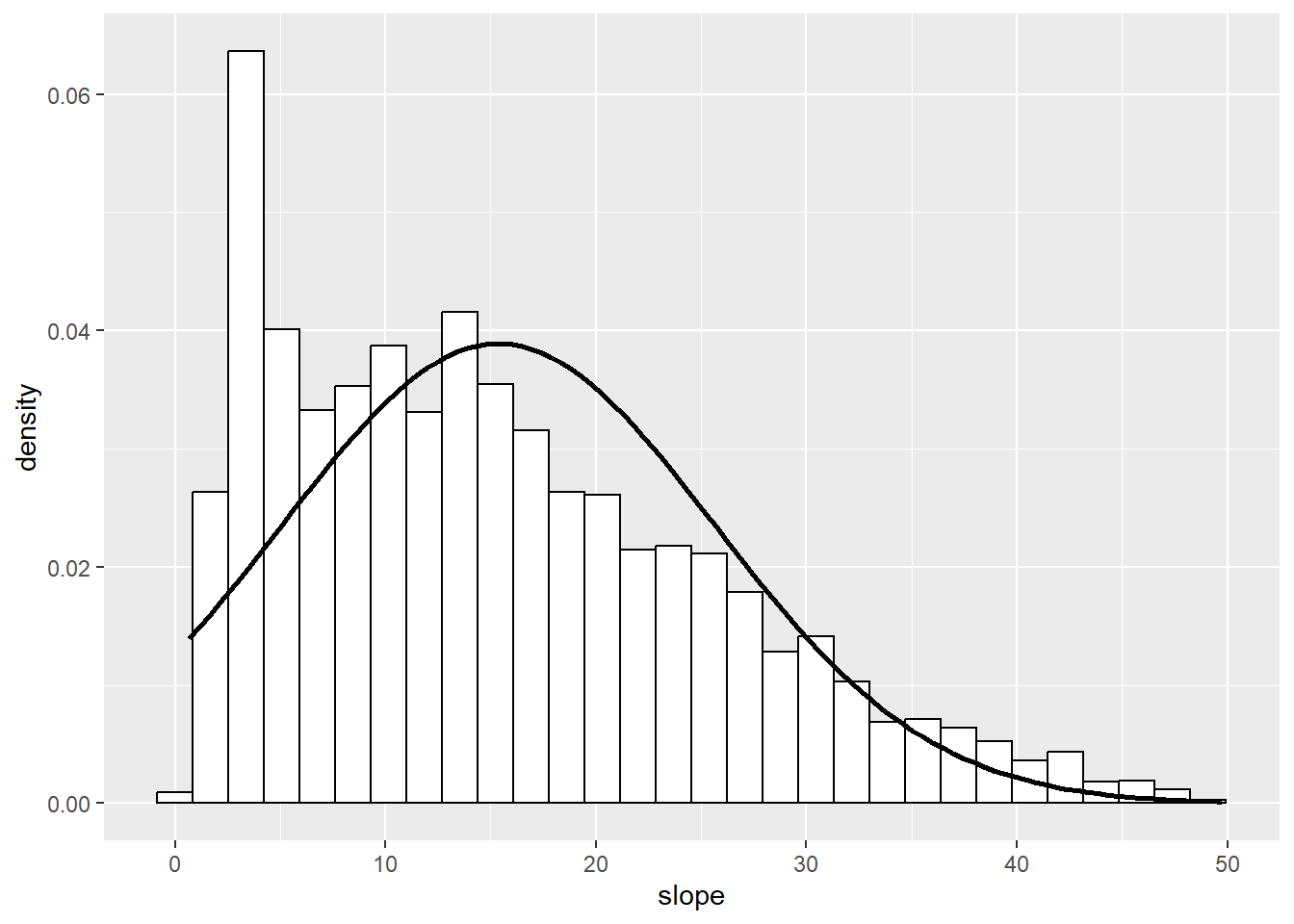
Musterlösung
# Aufgabe 4: die Verteilung bei einem Teildatensatz zu testen reicht,
# denn die verwendeten Kreise sind die selben am Tag und in der Nacht,
# nur die Nutzung durch das Reh nichtAufgabe 5
Explorative Analysen der Variablen mit Scatterplots / Scatterplotmatrizen
- Zu Scatterplots und Scatterplotmatrizen gibt es viele verschiedene Funktionen / Packages, schaut im Internet und sucht euch eines welches euch passt.
- Testen der Korrelation zwischen den Variablen (Parametrisch oder nicht-parametrische Methode? Ausserdem: gewisse Scatterplotmatrizen zeigen euch die Koeffizenten direkt an)
Musterlösung
pairs.panels(DF_mod_day[5:12],
method = "pearson", # correlation method
hist.col = "#00AFBB",
density = TRUE, # show density plots
ellipses = TRUE # show correlation ellipses
)
Musterlösung
# Aufgabe 5: die Korrelation bei einem Teildatensatz zu testen reicht,
# denn die verwendeten Kreise sind die selben am Tag und in der Nacht,
# nur die Nutzung durch das Reh nicht.