Statistik 2
Einführung in lineare Modelle, ein- und mehrfaktorielle Varianzanalysen (ANOVAs)
In Statistik 2 lernen die Studierenden die Voraussetzungen und die praktische Anwendung “einfacher” linearer Modelle in R (sowie teilweise ihrer “nicht-parametrischen” bzw. “robusten” Äquivalente). Am Anfang steht die Varianzanalyse (ANOVA) als Verallgemeinerung des t-Tests, einschliesslich post-hoc-Tests und mehrfaktorieller ANOVA. Dann geht es um die Voraussetzungen parametrischer (und nicht-parametrischer) Tests und Optionen, wenn diese verletzt sind.
Lernziele
Ihr…
- wisst, welche Voraussetzungen parametrische (und nicht-parametrische) Tests haben und welche Alternativen euch bei wesentlichen Verletzungen zur Verfügung stehen;
- könnt eine ANOVA in R durchführen, versteht ihre Ergebnisse und könnt diese adäquat in Text und Abbildungen dokumentieren; und
- versteht, was eine Interaktion in einer mehrfaktoriellen ANOVA ist.
Einfaktorielle Varianzanalyse (One-Way ANOVA)
Die Idee dahinter
Eine ANOVA (Analysis of variance) ist die Verallgemeinerung des t-Tests für mehr als zwei Gruppen (Factor levels). Auch hier wollen wir wissen, ob/wie sich die Mittelwerte der abhängigen Variablen zwischen den Gruppen unterscheiden. Varianzanalyse heisst das Verfahren, weil der statistische Test zur Beantwortung der Frage das Verhältnis zweier Varianzen testet. Was es mit den zwei Varianzen auf sich hat, ist im Folgenden erklärt.
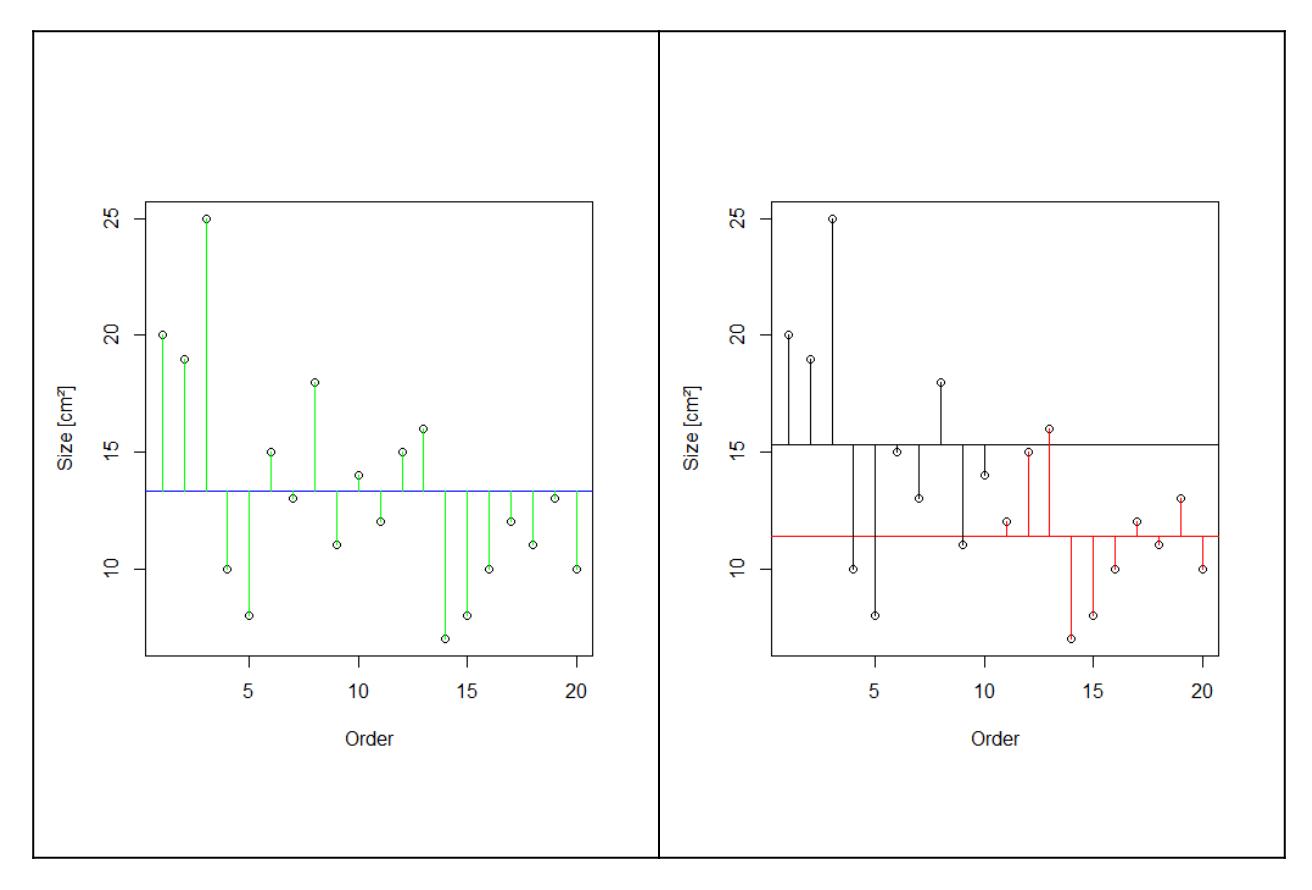
Gehen wir zurück zu unserem Blumenbeispiel. Die Idee der ANOVA ist, dass die Mittelwerte der Blütengrössen der beiden Sorten dann verschieden sind, wenn die Summe der Abweichungen (Residuen) vom Gesamtmittelwert “signifikant” grösser ist als die Summe der Abweichungen von den Sortenmittelwerten. Das ist in der folgenden Abbildung veranschaulicht. Die Punkte stellen die 20 Messwerte der Blütengrössen dar, wobei sie in der rechten Teilabbildung nach Sorten gruppiert sind. Der Gesamtmittelwert links und die beiden Sortenmittelwerte rechts sind als horizontale Linien dargestellt. Die vertikalen Linien sind die Residuen, also die Abweichung der beobachteten von den durch das Modell vorhergesagten Werten. Zusammen ergeben sie den Anteil der Varianz, welcher durch das jeweilige statistische Modell nicht erklärt wird. Das Modell links nimmt an, dass die Blüten einheitlich gross sind, unabhängig von der Sorte, während das komplexere Modell rechts unterschiedliche Mittelwerte abhängig von der Sorte annimmt.
Varianz ist ein Mass für die Streuung von Werten um ihren Mittelwert. Mathematisch wird die Varianz wie folgt berechnet:
(Summe der Abweichungsquadrate = Sum of squares = SS)
Abweichungsquadrate sind dabei die quadrierten Werte der grünen (bzw. schwarzen und roten) vertikalen Linien in der obigen Abbildung. Die Distanzen werden quadriert, so dass negative Abweichungen gleichermassen zählen. Würde man nur die unquadrierten Werte aufsummieren, wäre das Ergebnis immer 0, da die horizontale Linie (der Mittelwert) ja so gelegt wurde, dass die positiven und negativen Abweichungen betragsmässig gleich sind. Ein zentraler Punkt der Varianzanalyse ist, dass sich die Gesamtsumme der Abweichungsquadrate (Total sum of squares) als die Summe zweier Teile (SSE und SSA) darstellen lässt:
Praktische Durchführung
Schauen wir das zunächst beim Blumen-Datensatz an.
head(blume) cultivar size
1 a 20
2 a 19
3 a 25
4 a 10
[…]
11 b 8
12 b 12
13 b 9Schauen wir uns zunächst noch einmal das Ergebnis als “normalen” t-Test an:
t.test(size~cultivar, var.equal = TRUE, data = blume)Two Sample t-test
data: size by cultivar
t = 2.0797, df = 18, p-value = 0.05212
alternative hypothesis: true difference in means between group a and group b is not equal to 0
95 percent confidence interval:
-0.03981237 7.83981237
sample estimates:
mean in group a mean in group b
15.3 11.4Nun nehmen wir dieselben Daten und analysieren sie mit einer Varianzanalyse. Der Befehl dazu ist aov (was für analysis of variance steht). Man kann sich die Ergebnisse der ANOVA mit summary und summary.lm anzeigen lassen und bekommt jeweils unterschiedliche Informationen (die wir beide benötigen):
aov_1 <- aov(size ~ cultivar, data = blume)
summary(aov_1) Df Sum Sq Mean Sq F value Pr(>F)
cultivar 1 76.0 76.05 4.325 0.0521 .
Residuals 18 316.5 17.58summary.lm(aov_1)[…]
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 15.300 1.326 11.54 9.47e-10 ***
cultivarb -3.900 1.875 -2.08 0.0521 .Beim ersten Output (summary) sehen wir eine typische “ANOVA-Tabelle” wie man sie als Ergebnis linearer Modelle erhält. Die Bedeutung der Abkürzungen ist wie folgt:
- Df = Degrees of freedom (Freiheitsgrade)
- Sum Sq = Sum of squares (Summe der Abweichungsquadrate)
- Mean Sq = Sum of squares / degrees of freedom (Quotient der beiden Werte)
- F value = Mean Sq (Treatment) / Mean Sq (Residuals) (Quotient der beiden mittleren Abweichungsquadrate)
- Pr(>F) = Probability to obtain a more extreme F value under the null hypothesis (p-Wert)
Der F-Wert ist das Verhältnis der durch die Variable und die Residuen erklärten Varianzen (Mean squares), also . Der F-Wert (4.33) entsprichtdem quadrierte t-Wert (–2.08) aus der unteren Tabelle. Der p-Wert (0.052) in der obigen Tabelle ist also genau der gleiche wie im t-Test, was die Äquivalenz von ANOVA und t-Test zeigt. Dieser p-Wert steht für die Nullhypothese, dass sich die beiden Sorten nicht in ihrer Blütengrösse unterscheiden.
Derselbe p-Wert taucht im summary.lm-Output unten in der zweiten Zeile auf. Aber für was steht der extrem kleine p-Wert in der ersten Zeile des summary.lm-Outputs (9.47 x 10–10)? In der Zeile steht (Intercept), also Achsenabschnitt. Hier ist der vorhergesagte Mittelwert für die erste Sorte (Cultivar a) gemeint. Die Nullhypothese zu dieser Zeile ist, dass die Blütengrösse dieser Sorte = 0 ist. Da Blütengrössen immer positive Werte haben (nie negativ und für eine existierende Blüte auch nie 0), ist das keine sinnvolle/relevante Nullhypothese. In den allermeisten Fällen bezieht sich der p-Wert in der ersten Zeile eines summary.lm-Outputs auf eine unsinnige/irrelevante Nullhypothese und wir können ihn ignorieren.
Eine weitere wichtige Information liefert uns die zweite Tabelle aber noch: die Effektgrösse und richtung. Dazu müssen wir in die Spalte Estimates schauen, welche die sogenannten Parameterschätzungen enthält. Im Falle einer ANOVA enthält die (Intercept)-Zeile den geschätzten Mittelwert für die alphabetisch erste Kategorie (bei uns also Cultivar a), währen das Estimate in der Zeile cultivarb für den Unterschied im Mittelwert von Cultivar b vs. Cultivar a steht, hier steht also die biologisch relevante Information, sprich: die Blüten von Cultivar b sind im Mittel 3.9 cm2 kleiner als jene von Cultivar a. Allerdings sind wir uns dieser Aussage nicht besonders sicher, da sie statistisch nur marginal signifikant ist ().
Wenn wir eine “echte” ANOVA mit drei oder mehr Kategorien durchführen, die also nicht mehr mit dem t-Test analysiert werden kann, sieht der Output vergleichbar aus, nur hat sich die Zahl der Freiheitsgrade in der ersten Zeile erhöht (immer Zahl der Kategorien – 1, bei 3 Kategorien also 2).
aov_2 <- aov(size ~ cultivar, data = blume2)
summary(aov_2) Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 736.1 368.0 18.8 7.68e-06 ***
Residuals 27 528.6 19.6In diesem Fall gibt es also höchstsignifikante Unterschiede in der Blütengrösse zwischen den drei Sorten. Wir könnten das Ergebnis kurz und prägnant wie folgt wiedergeben:
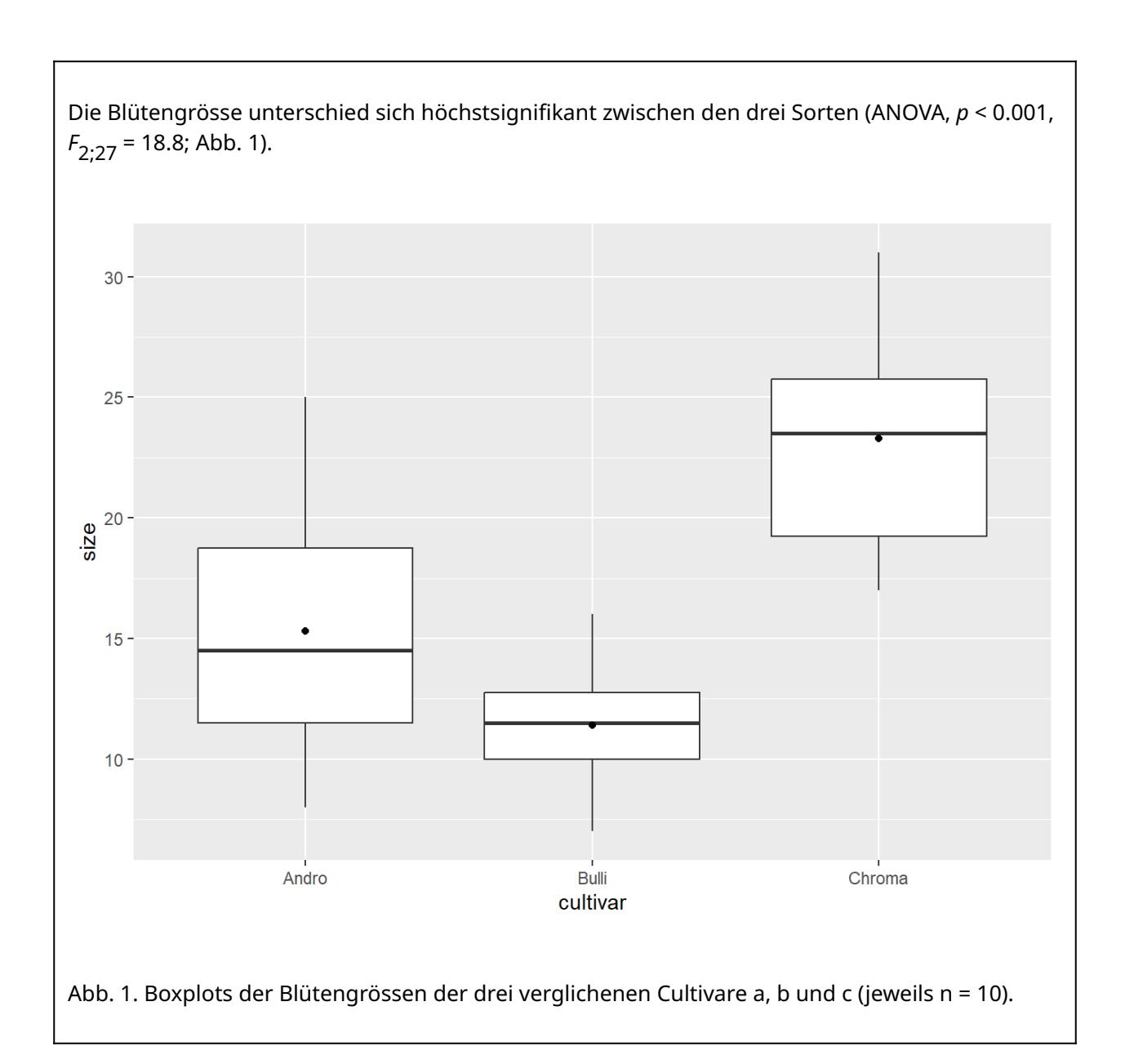
Zwei Anmerkungen: (1) Bei drei und mehr Kategorien kann man im Text nicht mehr effizient schreiben, welche Sorte sich wie von welcher anderen unterscheidet, deshalb bietet sich hier eher eine Visualisierung an (sofern die ANOVA insgesamt ein signifikantes Muster anzeigt). (2) Wenn man den F-Wert angeben möchte, so muss man im Subskript nachgestellt die Freiheitsgrade im Zähler (2) und im Nenner (27) angeben, die man der ANOVA-Tabelle entnehmen kann.
Post-hoc-Test (Tukey)
Aufgrund der vorhergehenden ANOVA wissen wir nun, dass es insgesamt ein signifikantes Muster gibt, dass also nicht alle drei Sorten der gleichen Grundgesamtheit angehören. Was wir nicht wissen, ist, welche Sorte sich von welcher anderen unterscheidet, und ggf. wie stark. Wenn die ANOVA insgesamt signifikant ist, muss das längst nicht heissen, dass jede Sorte sich von jeder anderen unterscheidet. Nun könnte man auf die Idee kommen, einfach für jedes Sortenpaar einen t-Test durchzuführen. Das Problem ist, dass man dann u. U. ziemlich viele Tests mit denselben Daten macht, und da summieren sich die Typ I-Fehlerraten schnell auf, sprich: bei vielen Tests werden rein zufällig manche ein signifikantes Ergebnis ergeben (mit α = 0.05 wird 5 % Irrtum zugelassen, d. h. im Durchschnitt liefert jeder zwanzigste Test ein falsch-positives Ergebnis). Um diesem Problem Rechnung zu tragen, gibt es sogenannte posthoc-Tests, die nach einer signifikanten ANOVA angewandt werden. Wenn die ANOVA nicht signifikant war, darf dagegen kein posthoc-Test angewandt werden! Der gängigste posthoc-Test ist jener von Tukey und findet sich u. a. im agricolae-Paket:
library(agricolae)
aov_2 <- aov(size~cultivar, data = blume2)
posthoc <- HSD.test(aov_2, "cultivar", group = FALSE, console = TRUE)
[…]Comparison between treatments means difference pvalue signif. LCL UCL
Andro - Bulli 3.9 0.1388 -1.006213 8.806213
Andro - Chroma -8.0 0.0011 ** -12.906213 -3.093787
Bulli - Chroma -11.9 0.0000 *** -16.806213 -6.993787Das Ergebnis sagt uns, dass sich Chroma von Andro und Chroma von Bulli, nicht aber Bulli von Andro signifikant unterscheiden. Bei nur drei Kategorien kann man das noch so formulieren, bei vier, fünf oder mehr wird es aber schnell langatmig und komplex. Das lässt sich mit sogenannten homogenen Gruppen lösen. Hier versieht man die Kategorien mit gleichen Buchstaben, die sich nicht signifikant voneinander unterscheiden, ggf. kann dann eine Kategorie auch mehrere Buchstaben tragen. In unserem Fall wäre die Lösung also:
- Cultivar Andro: b
- Cultivar Bulli: b
- Cultivar Chroma: a
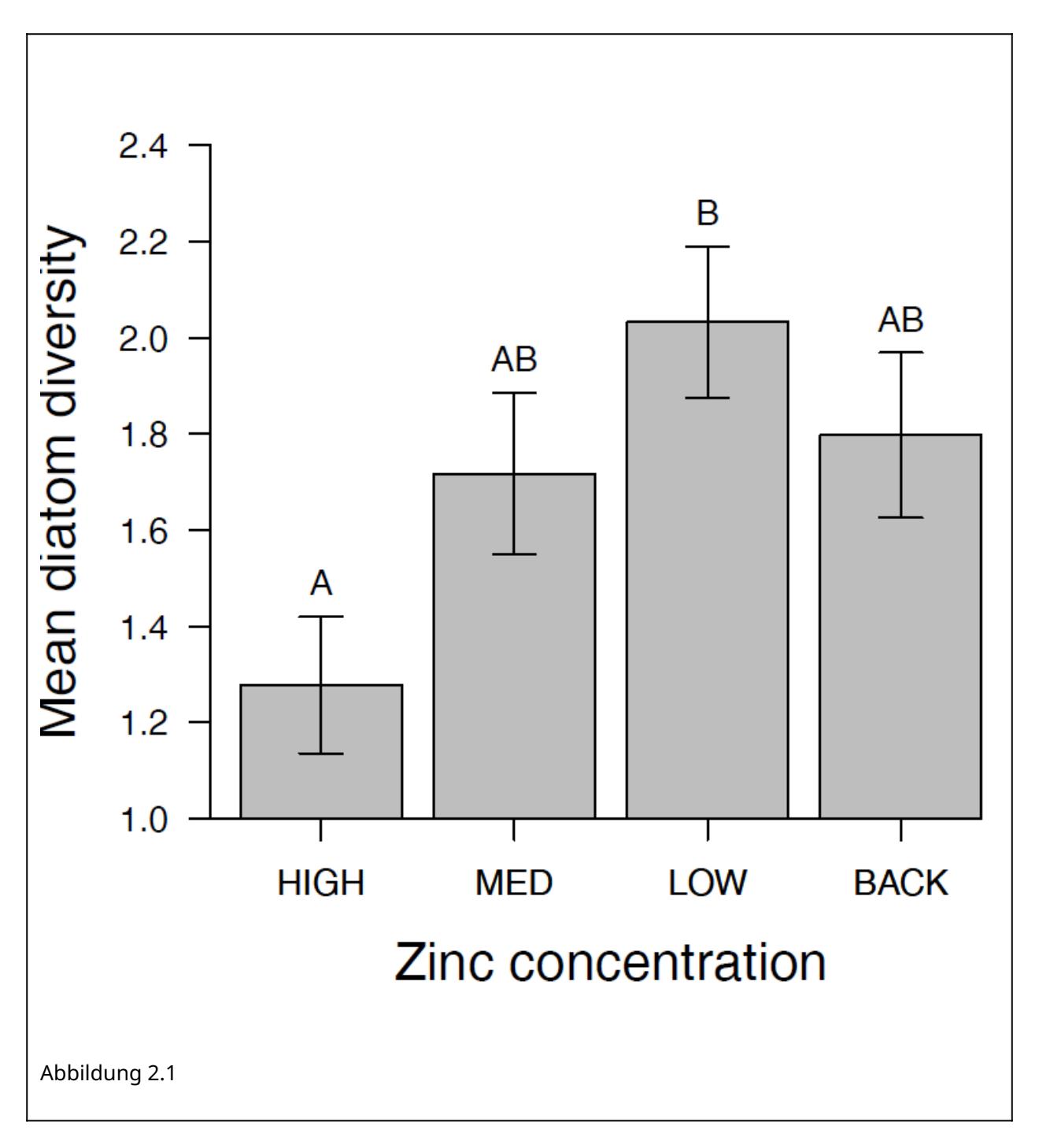
Diese Buchstaben kann man in die Ergebnisabbildung plotten oder als Superskript in einer Ergebnistabelle der Mittelwerte. Die Abbildung 2.1 zeigt ein Beispiel. Hier unterscheiden sich nur High und Low signifikant voneinander, da dies das einzige Paar ist, das keine gemeinsamen Buchstaben hat.
Hier ist noch gezeigt, wie man die Beschriftung in die Boxplots bekommt:
labels <- HSD.test(aov_2, "cultivar", console = TRUE)Treatments with the same letter are not significantly different.
size groups
Chroma 23.3 a
Andro 15.3 b
Bulli 11.4 bDie Buchstaben für die homogenen Gruppen aus dem Output muss man dann manuell zur jeweiligen Art plotten (Reihenfolge der Arten beachten!)
labels <- posthoc$groups
labels$cultivar <- rownames(labels)
ggplot(blume2, aes(cultivar, size)) +
geom_boxplot() +
geom_text(data = labels, aes(x = cultivar, y = 33, label = groups)) +
stat_summary(fun = mean, geom = "point")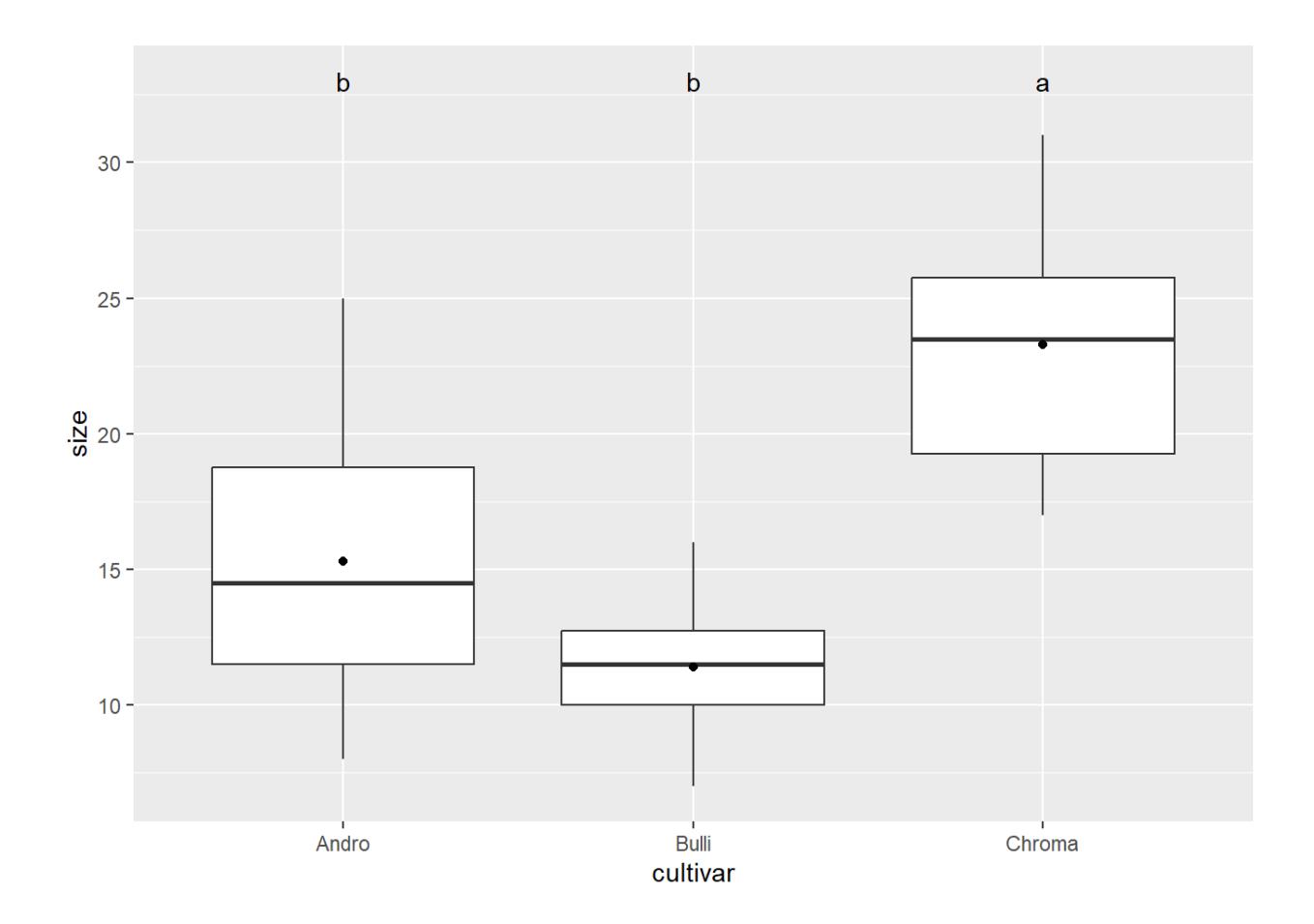
Mehrfaktorielle ANOVA
Bislang haben wir uns eine ANOVA mit nur einem Prädiktor, d. h. einer kategorialen Variablen mit zwei bis vielen Ausprägungen, angeschaut. Das Prinzip lässt sich aber auch auf zwei und mehr kategoriale Prädiktoren ausweiten. Man spricht dann von einer mehrfaktoriellen ANOVA. Im Optimalfall hat man das Erhebungsdesign so gewählt, dass alle Kombinationen Faktorlevels aller Prädiktorvariablen auftreten (dann spricht man von einem vollfaktoriellen Design), am besten sogar in gleicher/ähnlicher Häufigkeit.
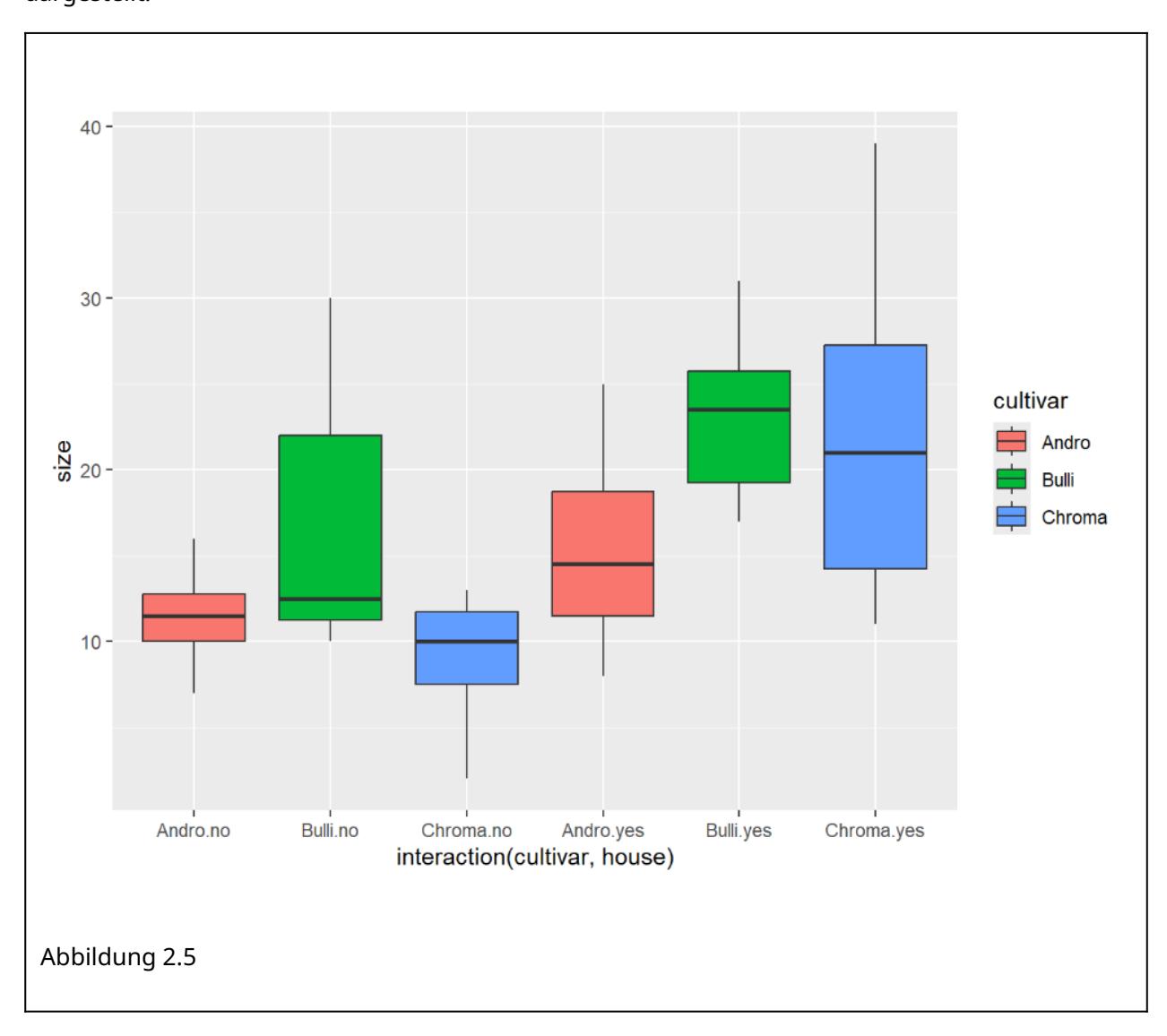
Betrachten wir exemplarisch die Situation mit zwei Prädiktoren (zweifaktorielle Varianzanalyse, twoway ANOVA). Hierzu haben wir in unserem Blumenbeispiel neben den drei Sorten noch ein weiteres “Treatment” hinzugefügt, nämlich, ob die Pflanzen im Gewächshaus (house = yes) oder im Freiland (house = no) aufgezogen wurden. Der Boxplot in der explorativen Datenanalyse ist in Abbildung 2.5 dargestellt.
Wir haben nun zwei Möglichkeiten, die zweifaktorielle Varianzanalyse durchzuführen, mit oder ohne Berücksichtigung von Interaktionen:
aov_3 <- aov(size ~ cultivar + house, data = blume3)
summary(aov_3) Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 417.1 208.5 5.005 0.01 *
house 1 992.3 992.3 23.815 9.19e-06 ***
Residuals 56 2333.2 41.7aov_4b <- aov(size ~ cultivar * house, data = blume3)
summary(aov_4b) Df Sum Sq Mean Sq F value Pr(>F)
cultivar 2 417.1 208.5 5.364 0.0075 **
house 1 992.3 992.3 25.520 5.33e-06 ***
cultivar:house 2 233.6 116.8 3.004 0.0579 .
Residuals 54 2099.6 38.9Ohne Interaktion (oben) verknüpfen wir die beiden Prädiktoren einfach mit “+”; wenn wir die Interaktion auch analysieren wollen (unten), dann verwenden wir * zur Verknüpfung. Eine Interaktion läge dann vor, wenn sich die Auswirkung von Gewächshaus vs. Freiland zwischen den Sorten unterschiede, etwa in einem Fall positiv, im anderen neutral oder negativ. Wir sehen, dass die untere ANOVA mit dem Interaktionsterm im Output eine dritte Zeile cultivar:house enhält, welche die Signifikanz der Interaktion angibt (in unserem Fall also marginal signifikant).
Liegt eine signifikante Interaktion vor, dann nimmt man zur Ergebnisdarstellung am besten eine Grafik, einen sogenannten Interaktionsplot, da sich die Interaktion schon bei zweifaktoriellen ANOVAs schwer in Worte fassen lässt und noch schwerer bei dreifaktoriellen ANOVAs mit potenziell einer Dreifachinteraktion und drei Zweifachinteraktionen. Bei Zweifachinteraktionen kann man sich zwei unterschiedliche Grafiken anzeigen lassen (R Code ist für die obere):
ggplot(blume3, aes(cultivar, size, color = house, group = house)) +
stat_summary(fun = mean, geom = "point", size = 3) +
stat_summary(fun = mean, geom = "line", linewidth = 1)
ggplot(blume3, aes(house, size, color = cultivar, group = cultivar)) +
stat_summary(fun = mean, geom = "line", size = 1) +
stat_summary(fun = mean, geom = "point", size = 3)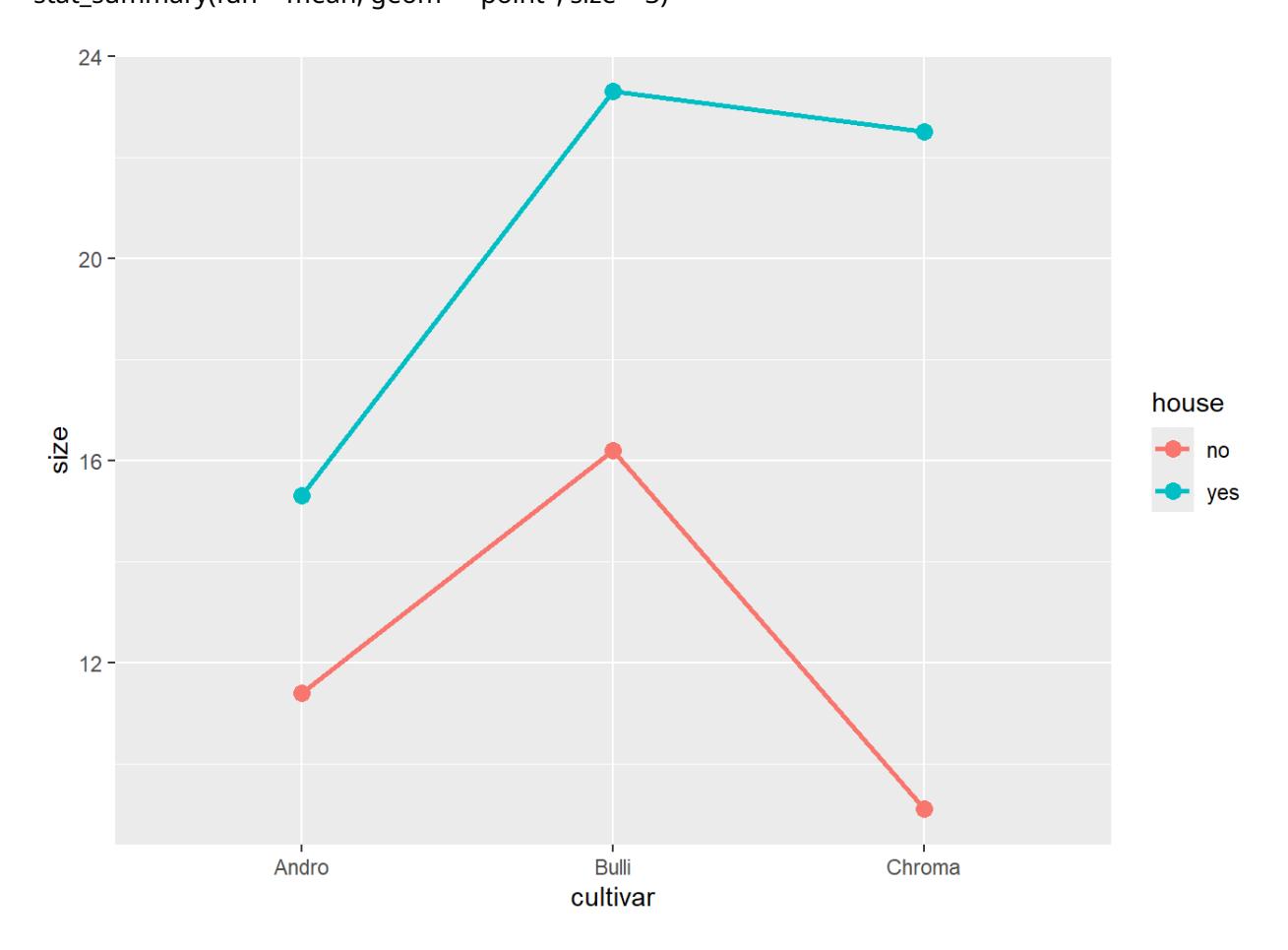
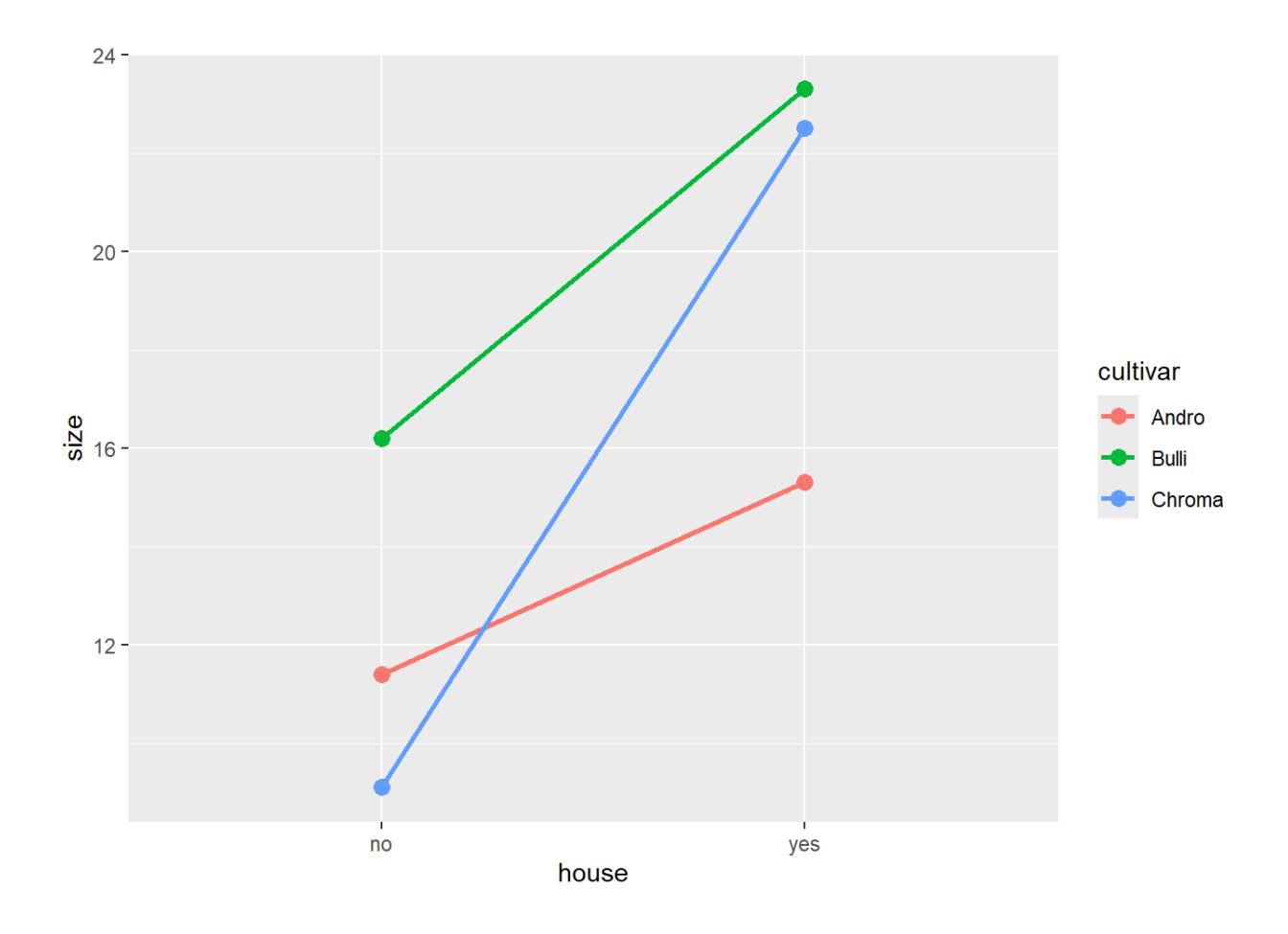
Die Interaktion war nicht signifikant, was sich darin zeigt, dass die Linienzüge für yes und no einigermassen parallel sind, d. h. im Gewächshaus alle drei Kultivare grösser waren. Allerdings haben sich die drei Kultivare nicht völlig konsistent verhalten: der positive Einfluss von Gewächshaus war bei Sorte c viel grösser als bei den anderen beiden (was zu einem p-Wert der Interaktion nahe an der Signifikanzschwelle geführt hat).
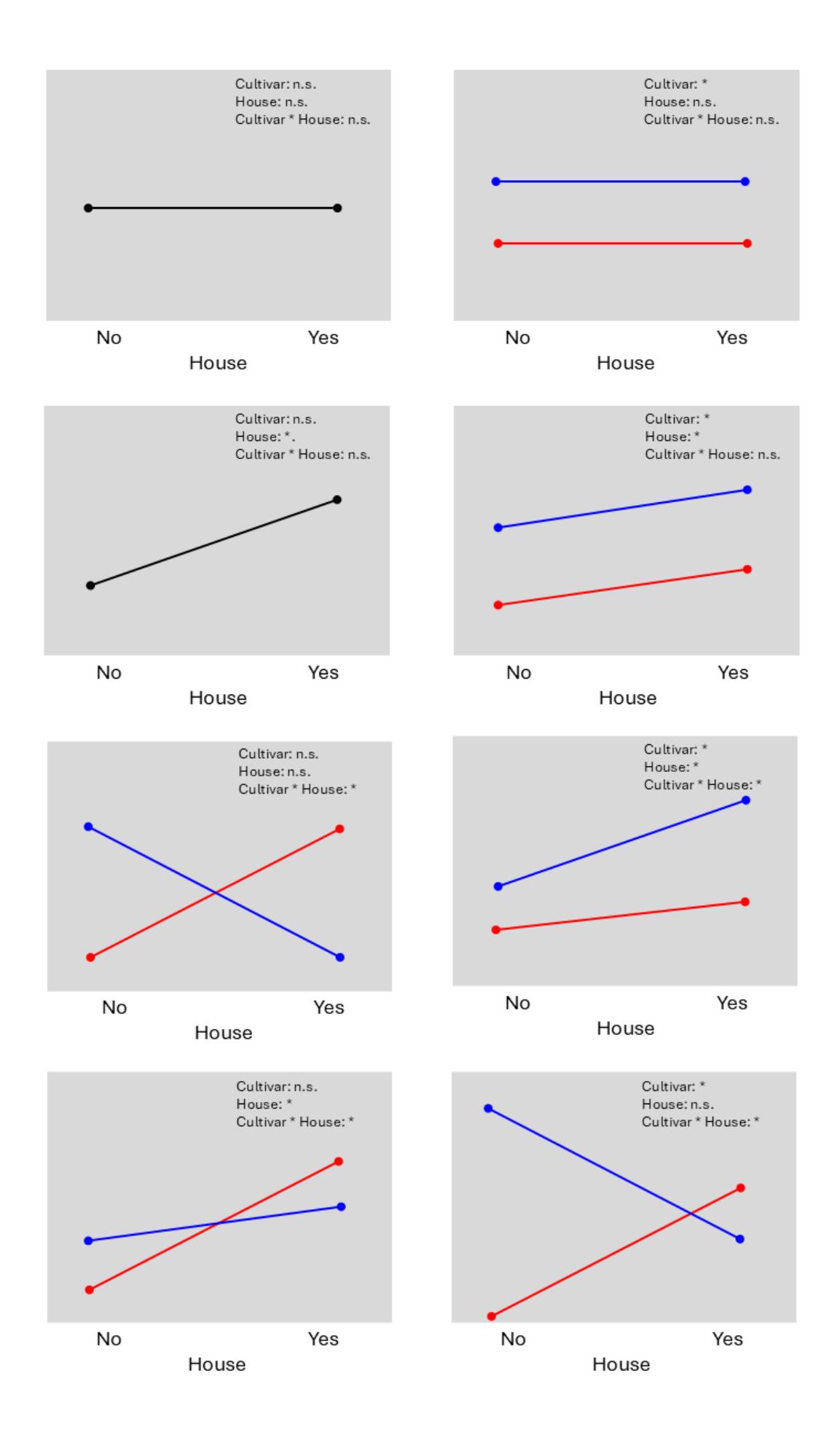
Die folgende Abbildung zeigt, wie ein Interaktionsplots schematisch aussehen würden, je nachdem, welche der Prädiktoren (Cultivar, House, Interaktion) signifikant ist. Insgesamt gibt es 23 = 8 Kombinationen. Zur Vereinfachung zeigt die Abbildung eine Situation mit nur zwei Kultivaren (rot, blau). Schwarze Linien stehen für Linien der Kultivare, die fast deckungsgleich sind.
Voraussetzung statistischer Verfahren
In Statistik 1 wurde kurz erwähnt, dass jeder statistische Test auf bestimmten Annahmen bezüglich der Werteverteilung in der Grundgesamtheit beruht. Beim klassischen t-Test nach Student sind das die Normalverteilung und die Varianzhomogenität.
Parametrische vs. nicht-parametrische Verfahren
Verfahren, die auf dem folgenden gängigen Set von Voraussetzungen beruhen, werden als parametrische Verfahren bezeichnet. Es sind dies zugleich die “linearen Modelle” (doch zu diesem Begriff später mehr):
- Normalverteilung der Residuen
- Varianzhomogenität
- Feste x-Werte
- Unabhängigkeit der Beobachtungen / Zufällige Beprobung
Dem gegenüber gestellt werden so-genannte “nicht-parametrische” Verfahren. Der Begriff ist allerdings sehr irreführend, da nicht-parametrische Verfahren nicht etwa keine Voraussetzungen haben, sondern meist nur geringfügig schwächere als parametrische Verfahren. Die Voraussetzungen für die Anwendung gängiger nicht-parametrischer Verfahren sind:
- Die Verteilung der Residuen kann einer beliebigen Funktion folgen, muss aber für die verschiedenen Faktorlevels (Kategorien) gleich sein
- Feste x-Werte
- Unabhängigkeit der Beobachtungen / Zufällige Beprobung
Diese beiden Listen, weisen auf drei weitverbreitete Irrtümer in der Statistik hin, die in älteren Statistikbüchern regelmässig falsch dargestellt wurden und die auch heute noch in Statistikkursen an Hochschulen oft falsch gelehrt werden:
- Irrtum 1: die abhängige oder gar die unabhängige Variable sollte normalverteilt sein. Korrekt ist: Nur die Residuen des statistischen Models sollten normalverteilt sein. Dagegen ist es gleichgültig, ob die Werte der abhängigen Variablen normalverteilt sind, und erst recht gilt das für die unabhängigen Variablen.
- Irrtum 2: es kommt hauptsächlich auf die Normalverteilung an. Korrekt ist: Die Varianzhomogenität ist wichtiger als Normalverteilung der Residuen.
- Irrtum 3: Bei kleinsten Abweichungen von der Varianzhomogenität oder Normalverteilung sollte auf ein nicht-parametrisches Äquivalent ausgewichen werden. Korrekt ist: Dieses Vorgehen ist meist nicht nötig, aber unvorteilhaft (da nichtparametrische Verfahren meist eine geringere Teststärke haben), im schlimmsten Fall sogar falsch (wie die Voraussetzungen des nicht-parametrischen Verfahrens gleichermassen verletzt sind).
In der Folge ist zu beobachten, dass vielfach vorschnell und unnötig auf “nicht-parametrische” Verfahren ausgewichen wird. Dagegen sprechen viele Gründe dafür, in fast allen Fällen mit parametrischen Verfahren zu arbeiten:
- Parametrische Verfahren sind recht robust gegen die Verletzung der Voraussetzungen, d. h. sie liefern selbst bei recht starken Abweichungen noch (fast) korrekte p-Werte, wie die folgende Simulation zeigte:
- Laut Quinn & Keough (2002) haben Simulationen Folgendes gezeigt:
- : selbst bei bis zu vierfacher SD noch korrekte p-Werte
- \(^{\circ}\) , : Wenn \(SD_1\) = 4 \(SD_2\) , dann entspricht ein berechneter in Wirklichkeit
- mit \(n_1\) und \(n_2\) = Stichprobengrösse für Faktorlevels 1 und 2 und SD = Standardabweichung
- Die meisten komplexeren statistischen Verfahren existieren ohnehin nur in einer parametrischen Variante.
- Dank Datentransformationen (s. Statistik 2 unten) und Generalisierungen linearer Modelle (s. Statistik 5) kann man auch mit Nicht-Normalität der Residuen und Varianzheterogenität = Heteroskedasitzität umgehen.
Wie testet man die Voraussetzungen? (klassischer Weg)
Der “klassische” (aber nicht zielführende!!!) Rat in vielen Statistikbüchern/-kursen ist die Anwendung statistischer Tests für Normalität und Varianzhomogenität. Für die Normalität (beachten, dass die Residuen, nicht die Rohdaten getestet werden müssen, also im Fall einer ANOVA die Werte jeder Kategorie für sich). Es gibt u.a. den Kolmogorov-Smirnov-Test (mit Lillefors-Korrektur) und den Sharpiro-Wilks-Test:
Für das Testen der Varianzhomogenität gibt es u.a. den F-Test zur Varianzhomogenität und den Levene-Test (im Paket car):
Wenn die p-Werte dieser Tests < 0.05 sind, dann liegt eine statistisch signifikante Abweichung von der jeweiligen Voraussetzung vor. Die klassische Konsequenz war, dann auf ein nicht-parametrisches Verfahren auszuweichen. Studierende und viele PraktikerInnen lieben diese scheinbar simple Schwarz-weiss-Sicht, die ein klares Prozedere vorzugeben scheint. Leider bringen diese Tests für die Entscheidung zwischen parametrischen und nicht-parametrischen Verfahren NICHTS. Die Gründe sind eigentlich einfach:
- Die genannten Tests testen allesamt die Wahrscheinlichkeit der Abweichung, nicht den Grad der Abweichung (wobei Letzteres der relevante Punkt ist).
- Damit werden einerseits bei kleinen Stichproben auch problematische Abweichungen nicht erkannt, bei grossen Stichproben harmlose Abweichungen dagegen “moniert” (man sollte sich bewusst sein, dass Variablen in der realen Welt niemals perfekt normalverteilt oder perfekt varianzhomogen sind)
Deshalb wird in modernen Lehrbüchern ausdrücklich davon abgeraten, die genannten Tests für diesen Zweck zu verwenden (z. B. Quinn & Keough 2002).
Wie testet man die Voraussetzungen? (empfohlener Weg)
Da die “klassischen” numerischen Tests nichts helfen, bleibt nur ein Weg, selbst wenn er zunächst unbefriedigend und subjektiv erscheinen mag. Moderne statistische Lehrbücher empfehlen heute, Normalverteilung der Residuen und Varianzhomogenität visuell zu prüfen und nur bei groben Verletzungen über alternative Vorgehensweisen nachzudenken.
Im Fall von t-Tests bzw. ANOVAs ist die einfachste Möglichkeit, nach Faktorlevels gruppierte Boxplots zu betrachten. Alternativ gingen auch Histogramme, allerdings sind diese nur bei grossen n aussagekräftig (Abbildung 2.2).
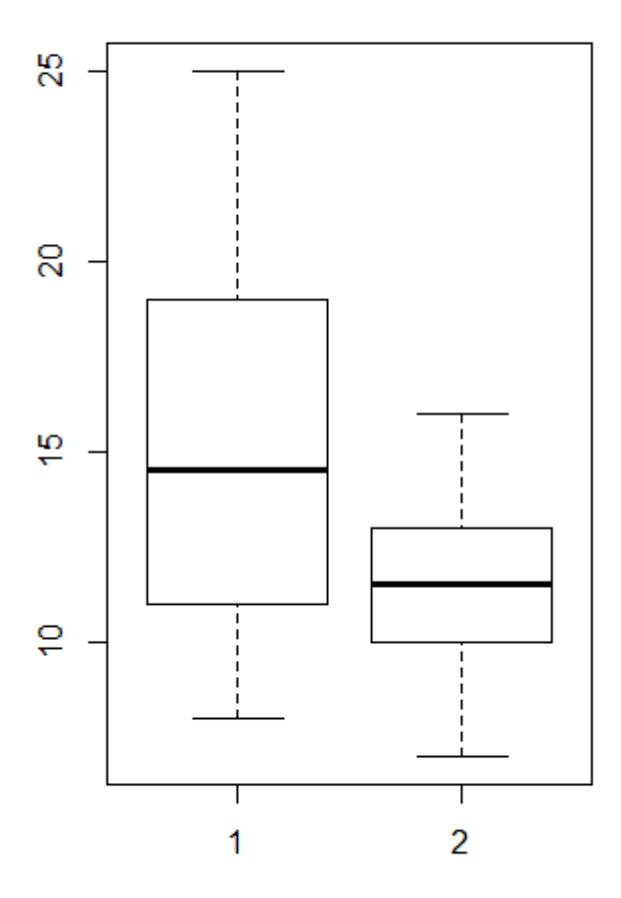
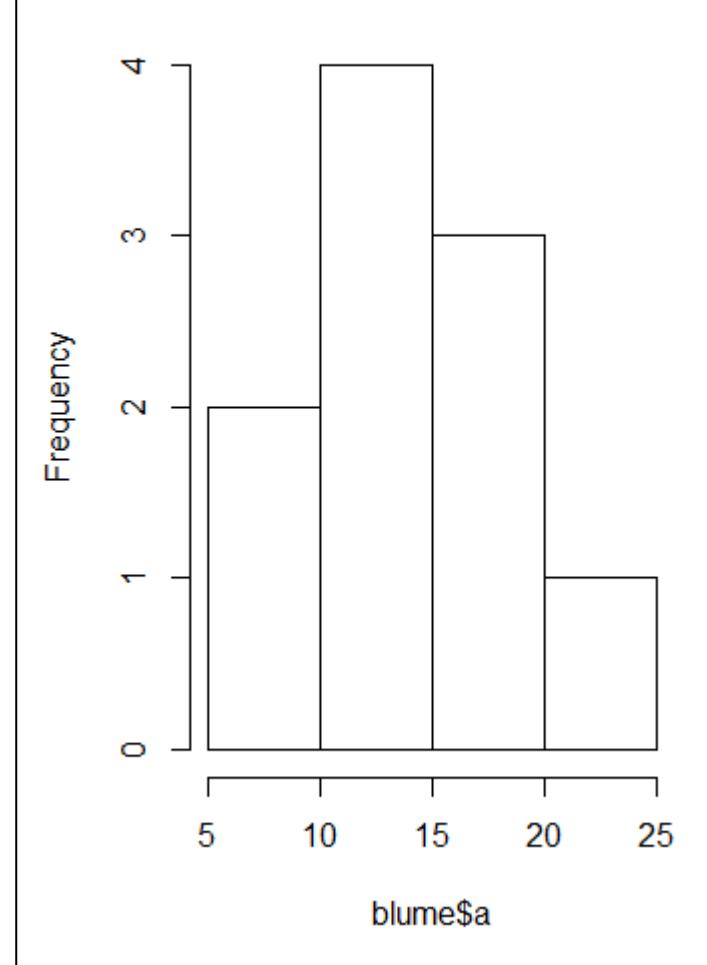
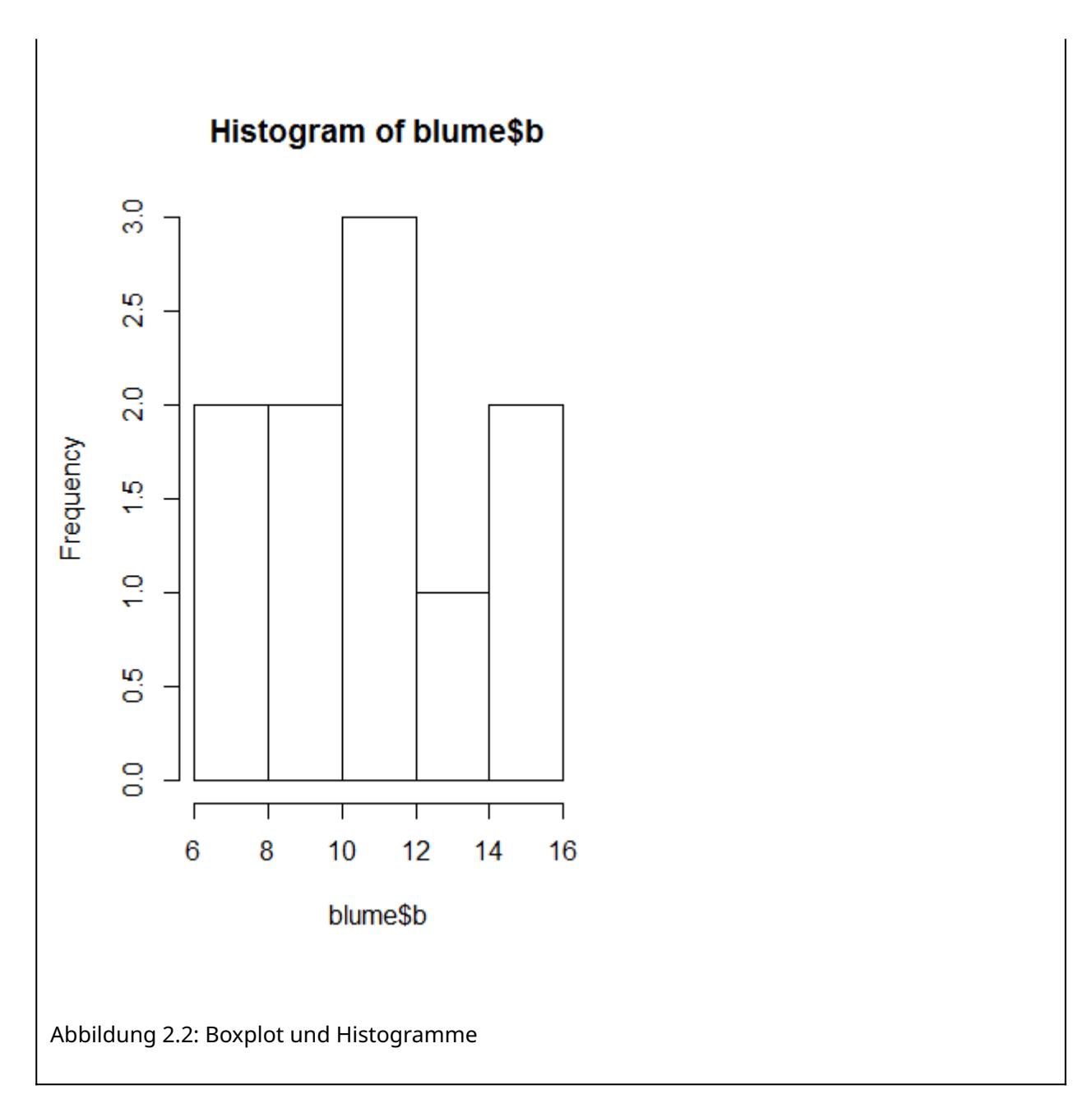
Für die Beurteilung der Varianzhomogenität betrachtet man am besten die Höhe der Boxen im Boxplot. Wenn sie ähnlich hoch sind, ist alles OK, wenn sie sehr stark abweichen, hat man evtl. ein Problem. Sehr stark meint aber, siehe Abbildung 2.2, wirklich sehr stark, d. h. wenn die Box in einer Kategorie mehr als 4-mal so hoch ist wie in einer anderen (bei gleichen/ähnlichen Replikatzahen), und ab mehr als doppelt so hoch bei erheblich verschiedenen Replikatzahlen. Im vorliegenden Fall ist die Varianz in Gruppe 1 etwa 2.5-mal so hoch wie in Gruppe 2, da die Zahl der Replikate aber identisch war, wäre das noch OK.
Zur Beurteilung der Normalverteilung bzw. des entscheidenden Aspekts der Normalverteilung, der Symmetrie, sind ebenfalls die Boxplots aufschlussreich. Eine starke Verletzung liegt vor, wenn der Median weit ausserhalb der Mitte der Box liegt oder wenn der obere “whisker” viel länger als der untere ist (oder auch umgekehrt, aber das kommt in der Praxis so gut wie nie vor).
Ausserdem gibt es noch das Central Limit Theorem (CLT) in der Statistik. Dieses Theorem besagt, dass wenn eine betrachtete Variable selbst schon ein Mittelwert ist, sie zwingend einer Normalverteilung folgt. In diesem Fall ist also kein Test nötig/sinnvoll. Wenn man sich auf das CLT berufen will, kann man z. B. Quinn & Keough (2002) zitieren.
Was tun, wenn die Voraussetzungen verletzt sind? (nichtparametrische Verfahren)
Bei Verletzung der Voraussetzungen, kann man auf nicht-parametrische Verfahren ausweichen, was OK ist, wenn man sich völlig klar darüber ist, welche Voraussetzungen diese ihrerseits haben:
Das nicht-parametrische Äquivalent zum t-Test ist der Wilcoxon-Rangsummen-Test. Er funktioniert, indem Werte in Ränge transformiert und summiert werden (W-statistic). Nachteile sind, dass er sehr konservativ ist (d. h. tendenziell zu hohe p-Werte schätzt). Der klassische Wilcoxon-Test (wilcox.test aus base R) kann zudem keine exakten p-Werte berechnen, wenn Bindungen(ties) vorliegen, d.h. mehrere Beobachtungen identische Werte aufweisen. Deswegen verwenden wir hier einen permutationsbasierten Wilcoxon-Test aus dem Paket coin, der dieses Problem nicht hat. Ausserdem sei noch einmal betont, dass der Wilcoxon-Test zwar keine Annahme über die Verteilung der Werte pro Gruppe macht, jedoch voraussetzt, dass diese in jeder Gruppe gleich ist.
library(coin)
wilcox_test(size ~ cultivar, data = blume)Ferner gibt es Randomisierungs-t-Tests. Diese haben den Vorteil, dass keine Annahme über die Verteilung getroffen werden muss (die Verteilung wird aus den Daten generiert). Zugleich müssen die Beobachtungen noch nicht einmal unabhängig sein. Allerdings testet man hier strenggenommen auch nicht auf Unterschiede in den Grundgesamtheiten, sondern ermittelt die Wahrscheinlichkeit, die beobachteten Unterschiede zufällig erzielt zu haben. Wer mehr über Randomisierungs-Tests wissen will, findet in Logan (2010: 148–150) weitergehende Infos.
Im Fall eines ANOVA-Designs gibt es zwei Situationen, mit jeweils anderen Alternativen zur klassischen ANOVA:
- Wir haben starke Abweichungen von der Normalverteilung der Residuen, aber ähnliche Varianzen. Dann kann der Kruskal-Wallis-Test zum Einsatz kommen (ebenfalls ein Rangsummen-Test). Der zugehörige posthoc-Test ist der Dunn-Test mit Benjamin-Hochberg-Korrektur der p-Werte (wegen multiplem Testen):
kruskal_test(size~cultivar, data = blume2)
library(FSA)
dunnTest(size~cultivar, method = "bh", data = blume2)- Wenn dagegen die Varianzen sehr heterogen sind, die Residuen aber relativ normal/symmetrisch, wie in Abbildung 2.3, kann der Welch-Test eingesetzt werden:
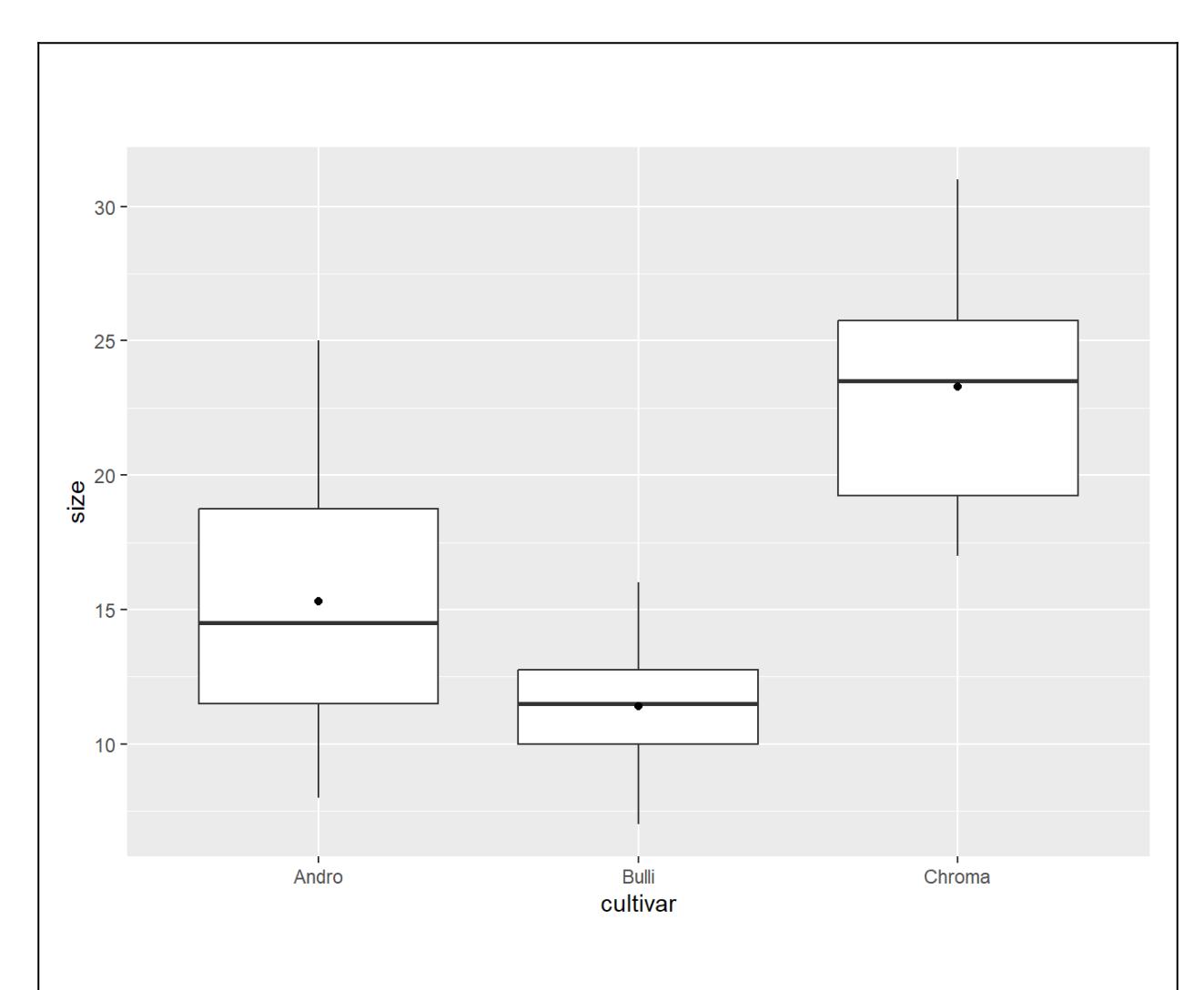
Abbildung 2.3. Boxplot von Residuenverteilungen, die recht gut einer Normalverteilung entspricht (Mediane ungefähr in der Mitte jeder Box, Whisker jeder Box oben und unten ähnlich lang), wo aber die Varianzen deutlich, wenn auch nicht extrem verschieden sind (siehe die unterschiedliche Höhe der Boxen).
oneway.test(size~cultivar, var.equal = F, data = blume2,)Was tun, wenn die Voraussetzungen (erheblich) verletzt sind? (Transformationen)
Statt auf nicht-parametrische Verfahren auszuweichen, kann man auch Transformationen anwenden. Da es um die Verteilung der Residuen geht, muss primär die abhängige Variable für Transformationen in Betracht gezogen werden, manchmal hilft aber auch die Transformation einer unabhängigen Variablen (weitergehende Infos siehe Fox & Weisberg 2019: 161–169).
Wenn man über die Anwendung von Transformationen nachdenkt, sind zwei Aspekte relevant: (1) Entgegen manchen Behauptungen sind untransformierte Daten (linear Skala) nicht per se natürlicher/richtiger. Auch die lineare Skala ist eine Konvention. Viele Naturgesetze (z. B. unsere Sinneswahrnehmung) funktionieren dagegen auf einer Logarithmusskala. (2) Wenn man die abhängige Variable transformiert, muss man sich aber klar darüber sein, dass man dann strenggenommen Hypothesen über die transformierten Daten, nicht über die ursprünglichen Werte testet. Achtung: Wenn man die Analysen mit transformierten Daten durchführt, darf man für die Ergebnisdarstellung die Rücktransformation mittels der jeweiligen Umkehrfunktion nicht vergessen!
Gängige Transformation für die abhängige Variable sind die folgenden:
Logarithmus-Transformation:
- Gut bei rechtsschiefen Daten/wenn die Varianz mit dem Mittelwert zunimmt.
- Die “natürlichste” Transformation.
- Natürlicher Logarithmus (log) oder Zehnerlogarithmus (log10) möglich.
- Werte müssen > 0 sein.
log (x + Konstante)-Transformation:
- Findet man häufig in der Literatur, wenn abhängige Variablen transformiert werden sollen, die auch Nullwerte enthalten
- Es werden unterschiedliche Konstanten (x) addiert, mal 1, mal 0.01. Es ist aber völlig willkürlich, ob man 1000000 oder 0.00000001 oder 3.24567 addiert, hat aber starken Einfluss auf die Ergebnisse
- Auch lassen sich die Ergebnisse nach so einer komplexen Transformation schlecht interpretieren (da man dann ja eine Hypothese über die transformierten Daten testet, s. o.)
- In Übereinstimmung mit Wilson (2007) rate ich daher dringend von derlei Transformationen ab!
Wurzeltransformation:
- Hat einen ähnlichen Effekt wie die Logarithmus-Transformation, lässt sich im Gegensatz zu dieser auch beim Vorliegen von Nullwerten anwenden (Werte müssen nur positiv sein).
- Die “Stärke” der Transformation kann man durch die Art der Wurzel kontinuierlich einstellen: Quadratwurzel, Kubikwurzel, 4. Wurzel,…
“arcsine”-Transformation:
asin(sqrt(x))\*180/pi- Wurde traditionell für Prozentwerte (Proportionen) und andere abhängige Variablen empfohlen, die zwischen 0 und 1 bzw. 0 und 100% begrenzt sind (z. B. Quinn & Keough 2002).
- Nach neueren Untersuchungen (Warton & Hui 2011) wird eher davon abgeraten.
Rangtransformation:
- Im Prinzip das, was “nicht-parametrische” Verfahren machen.
- Grösster Informationsverlust von allen genannten Verfahren (noch grösser wäre der Informationsverlust nur bei Überführung der metrischen abhängigen Variablen in Kategorien oder gar in eine Binärvariable).
Abbildung 2.4 visualisieren exemplarisch die Effekte unterschiedlicher Transformationen auf die Werteverteilung (ganz links sind jeweils die untransformierten Daten, die Transformation rechts hat jeweils eine deutlich bessere Annäherung an die Normalverteilung erzielt).
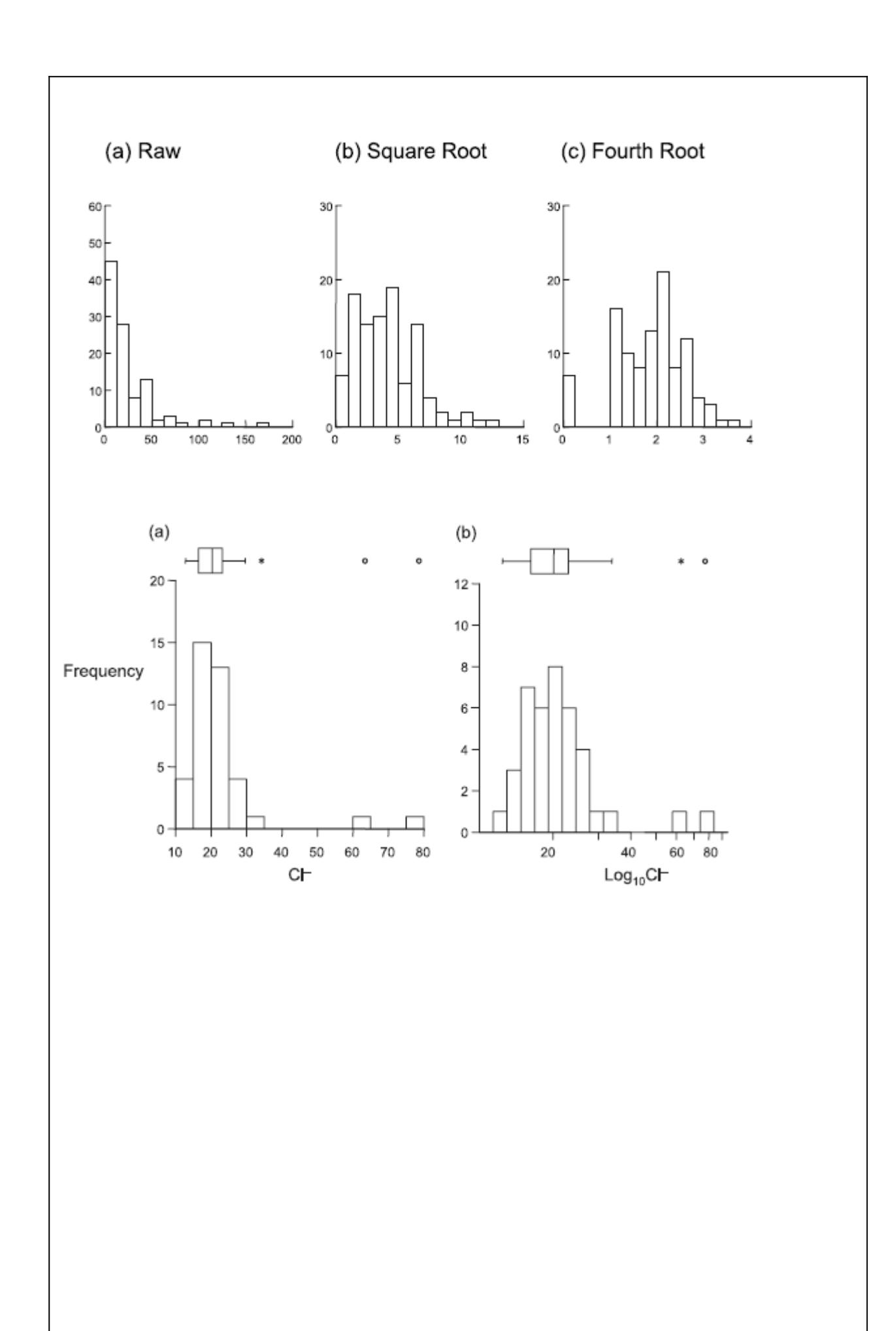
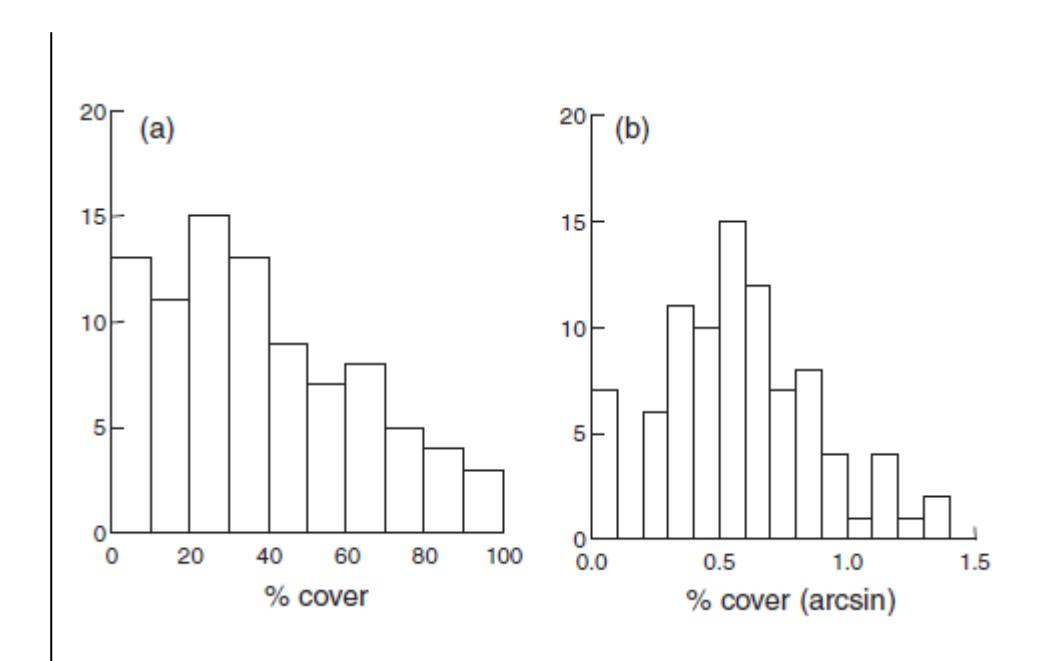
Abbildung 2.4. Auswirkungen von Wurzel-, Logarithmus- und Arcsin-Transformationen auf die Verteilung von Daten. Man sieht, dass bei den gezeigten Verteilungen in den Originaldaten die jeweiligen Transformationen eine Verbesserung bezüglich der Normalverteilungsannahme brachten (aus Quinn & Keough 2002).
Meist muss man nur die abhängige Variable transformieren. Es gibt aber Spezialfälle, wo man erst nach Transformation der abhängigen und der unabhängigen Variable eine adäquate Residuenverteilung erzielt. Dies ist insbesondere dann der Fall, wenn wir eine in Wirklichkeit nichtlineare Beziehung mit einem linearen Modell abbilden. Wenn etwa im Falle einer einfachen linearen Regression (s. u.) in Wirklichkeit ein Potenzgesetz (y = a xb ) vorliegt, erzielt man näherungsweise Varianzhomogenität und Normalverteilung der Residuen nur, wenn man a und b logarithmustransformiert.
Zusammenfassung
- t-Tests und ANOVAs sind parametrische Verfahren, um auf Unterschiede in den Mittelwerten einer metrischen Variablen zwischen zwei bzw. beliebig vielen Gruppen zu testen.
- Parametrische Verfahren basieren auf bestimmten Annahmen zur Streuung der Daten, sind aber robust gegenüber deren Verletzung.
- Die Voraussetzungen parametrischer Verfahren beziehen sich auf die Residuen, nicht auf die unabhängigen, noch auf die abhängigen Variablen per se.
Weiterführende Literatur
- Crawley, M.J. 2015. Statistics: An introduction using R. 2nd ed. John Wiley & Sons, Chichester, UK: 339 pp.
- Chapter 7 Regression: pp. 114–139
- Chapter 8 – Analysis of Variance: pp. 150–167
- Fox, J. & Weisberg, S. 2019. An R companion to applied regression. 3rd ed. SAGE Publications, Thousand Oaks, CA, US: 577 pp.
- Logan, M. 2010. Biostatistical design and analysis using R. A practical guide. Wiley-Blackwell, Oxford, UK: 546 pp.
- pp. 151-166 (lineare Modelle)
- pp. 167-207 (Korrelation und einfache lineare Regression)
- pp. 254-282 (Einfaktorielle ANOVA)
- pp. 311-359 (Mehrfaktorielle ANOVA)
- Quinn, G.P. & Keough, M.J. 2002. Experimental design and data analysis for biologists. Cambridge University Press, Cambridge, UK: 537 pp.
- Warton, D.I. & Hui, F.K.C. 2011. The arcsine is asinine: the analysis of proportions in ecology. Ecology 92: 3–10.
- Wilson, J.B. 2007. Priorities in statistics, the sensitive feet of elephants, and don’t transform data. Folia Geobotanica 42: 161–167.